19. AR(1)参数的后验分布#
我们先从导入一些Python包开始。
!pip install arviz pymc numpyro jax
import arviz as az
import pymc as pmc
import numpyro
from numpyro import distributions as dist
import numpy as np
import jax.numpy as jnp
from jax import random
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
import logging
logging.basicConfig()
logger = logging.getLogger('pymc')
logger.setLevel(logging.CRITICAL)
本讲座使用pymc和numpyro提供的贝叶斯方法对一阶自回归模型的两个参数进行统计推断。
该模型为我们提供了一个很好的机会来研究不同的初始值\(y_0\)的分布对结果的影响。
我们研究两种不同的初始值\(y_0\)的分布:
\(y_0\) 作为一个固定数值
\(y_0\) 作为从\(\{y_t\}\)随机过程的平稳分布中抽取的随机变量
这个模型的第一个组成部分是
其中标量\(\rho\)和\(\sigma_x\)满足\(|\rho| < 1\)和\(\sigma_x > 0\); \(\{\epsilon_{t+1}\}\)是一个均值为\(0\)、方差为\(1\)的独立同分布正态随机变量序列。
统计模型的第二个组成部分是
对于由该统计模型生成的样本序列\(\{y_t\}_{t=0}^T\), 我们可以将其似然函数分解成以下形式:
这里我们用 \(f\) 表示一般的概率密度。
我们想探究未知参数 \((\rho, \sigma_x)\) 的推断如何依赖于对 \(y_0\) 分布的参数 \(\mu_0, \sigma_0\)。
下面,我们研究两种广泛使用的替代假设:
第一种情况,我们将 \(y_0\) 视为已知的固定值,即 \((\mu_0,\sigma_0) = (y_0, 0)\)。这相当于对观察到的初始值进行条件化。
第二种情况,我们假设 \(y_0\) 来自模型的平稳分布,此时 \(\mu_0\) 和 \(\sigma_0\) 由参数 \(\rho\) 和 \(\sigma_x\) 决定。
注意: 我们不考虑将 \(\mu_0\) 和 \(\sigma_0\) 作为待估计参数的情况。
未知参数是 \(\rho, \sigma_x\)。
我们有 \(\rho, \sigma_x\) 的独立先验概率分布,并希望在观察到样本 \(\{y_{t}\}_{t=0}^T\) 后计算后验概率分布。
本讲使用 pymc4 和 numpyro 来计算 \(\rho, \sigma_x\) 的后验分布。
我们将使用 NUTS 采样器在链中生成后验分布的样本。
NUTS是一种蒙特卡洛马尔可夫链(MCMC)算法,它避免了随机游走行为,能更快地收敛到目标分布。
这不仅具有速度上的优势,还允许在不掌握拟合方法的理论知识的情况下,拟合复杂模型。
让我们来探讨对\(y_0\)分布做出不同假设的影响:
第一种方法是直接使用观察到的\(y_0\)值作为条件。这相当于将\(y_0\)视为一个确定的值,而不是一个随机变量。
第二种方法假设\(y_0\)是从(19.1)所描述过程的平稳分布中抽取的, 因此\(y_0 \sim {\cal N} \left(0, {\sigma_x^2\over (1-\rho)^2} \right)\)。
当初始值\(y_0\)位于平稳分布尾部较远处时,对初始值进行条件化会得到一个更准确的后验分布,我们将对此进行解释。
基本上,当\(y_0\)恰好位于平稳分布的尾部,而我们不对\(y_0\)进行条件化时,\(\{y_t\}_{t=0}^T\)的似然函数会调整后验分布的参数\(\rho, \sigma_x\),使得观测到的\(y_0\)值在平稳分布下比实际情况更可能出现,从而在短样本中对后验分布产生扭曲。
下面的例子展示了不对\(y_0\)进行条件化是如何导致\(\rho\)的后验概率分布向更大的值偏移的。
为了展示这一点,我们先通过模拟生成一个AR(1)过程的样本数据。
选择初始值\(y_0\)的方式很重要。
如果我们认为 \(y_0\) 是从平稳分布 \({\mathcal N}(0, \frac{\sigma_x^{2}}{1-\rho^2})\) 中抽取的,那么使用这个分布作为 \(f(y_0)\) 是个好主意。为什么?因为 \(y_0\) 包含了关于 \(\rho, \sigma_x\) 的信息。
如果我们怀疑 \(y_0\) 位于平稳分布的尾部很远的位置——以至于样本中早期观测值的变化具有显著的瞬态成分——最好通过设置 \(f(y_0) = 1\) 来对 \(y_0\) 进行条件化。
为了说明这个问题,我们将从选择一个位于平稳分布尾部很远的初始值 \(y_0\) 开始。
def ar1_simulate(rho, sigma, y0, T):
# Allocate space and draw epsilons
y = np.empty(T)
eps = np.random.normal(0.,sigma,T)
# Initial condition and step forward
y[0] = y0
for t in range(1, T):
y[t] = rho*y[t-1] + eps[t]
return y
sigma = 1.
rho = 0.5
T = 50
np.random.seed(145353452)
y = ar1_simulate(rho, sigma, 10, T)
plt.plot(y)
plt.tight_layout()
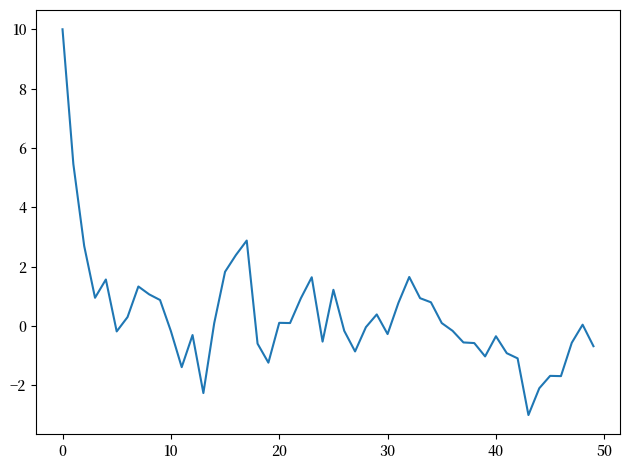
现在我们将使用贝叶斯定理来构建后验分布,以初始值\(y_0\)为条件。
(稍后我们会假设\(y_0\)是从平稳分布中抽取的,但现在不作此假设。)
首先我们将使用pymc4。
19.1. PyMC实现#
对于pymc中的正态分布,
\(var = 1/\tau = \sigma^{2}\)。
AR1_model = pmc.Model()
with AR1_model:
# 首先设定先验分布
rho = pmc.Uniform('rho', lower=-1., upper=1.) # 假设rho是稳定的
sigma = pmc.HalfNormal('sigma', sigma = np.sqrt(10))
# 下一期y的期望值(rho * y)
yhat = rho * y[:-1]
# 实际值的似然函数
y_like = pmc.Normal('y_obs', mu=yhat, sigma=sigma, observed=y[1:])
pmc.sample 默认使用NUTS采样器来生成样本,如下面的代码单元所示:
with AR1_model:
trace = pmc.sample(50000, tune=10000, return_inferencedata=True)
with AR1_model:
az.plot_trace(trace, figsize=(17,6))
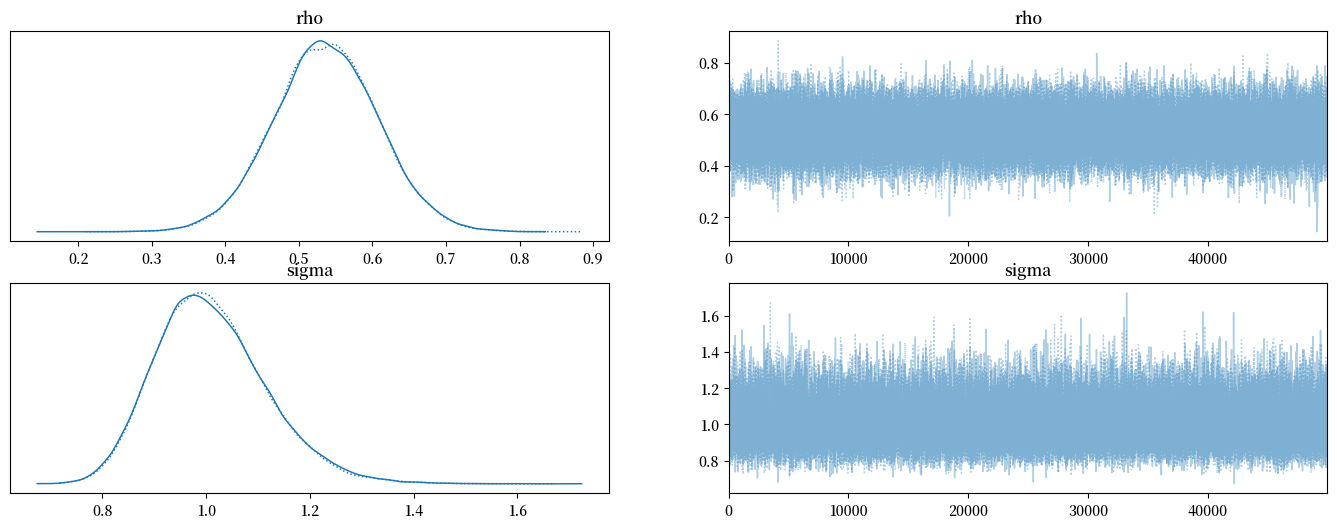
显然,后验分布并没有以我们用来生成数据的真实值 \(\rho = .5, \sigma_x = 1\) 为中心。
这是一阶自回归过程中经典的赫维奇偏差(Hurwicz bias)的表现(参见 Leonid Hurwicz [Hurwicz, 1950])。
赫维奇偏差在样本量越小时表现得越明显(参见 [Orcutt and Winokur, 1969])。
不管怎样,这里是关于后验分布的更多信息。
with AR1_model:
summary = az.summary(trace, round_to=4)
summary
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| rho | 0.5362 | 0.0710 | 0.4017 | 0.6692 | 0.0002 | 0.0002 | 89836.0255 | 63641.6483 | 1.0000 |
| sigma | 1.0099 | 0.1066 | 0.8232 | 1.2157 | 0.0004 | 0.0004 | 89610.1792 | 69864.0315 | 1.0001 |
现在让我们计算另一种情况下的后验分布:假设初始观测值 \(y_0\) 是从平稳分布中抽取的,而不是将其视为固定值。
这意味着
我们按如下方式修改代码:
AR1_model_y0 = pmc.Model()
with AR1_model_y0:
# 首先设定先验分布
rho = pmc.Uniform('rho', lower=-1., upper=1.) # 假设 rho 是稳定的
sigma = pmc.HalfNormal('sigma', sigma=np.sqrt(10))
# 平稳 y 的标准差
y_sd = sigma / np.sqrt(1 - rho**2)
# yhat
yhat = rho * y[:-1]
y_data = pmc.Normal('y_obs', mu=yhat, sigma=sigma, observed=y[1:])
y0_data = pmc.Normal('y0_obs', mu=0., sigma=y_sd, observed=y[0])
with AR1_model_y0:
trace_y0 = pmc.sample(50000, tune=10000, return_inferencedata=True)
# 灰色垂直线表示发散的情况
with AR1_model_y0:
az.plot_trace(trace_y0, figsize=(17,6))
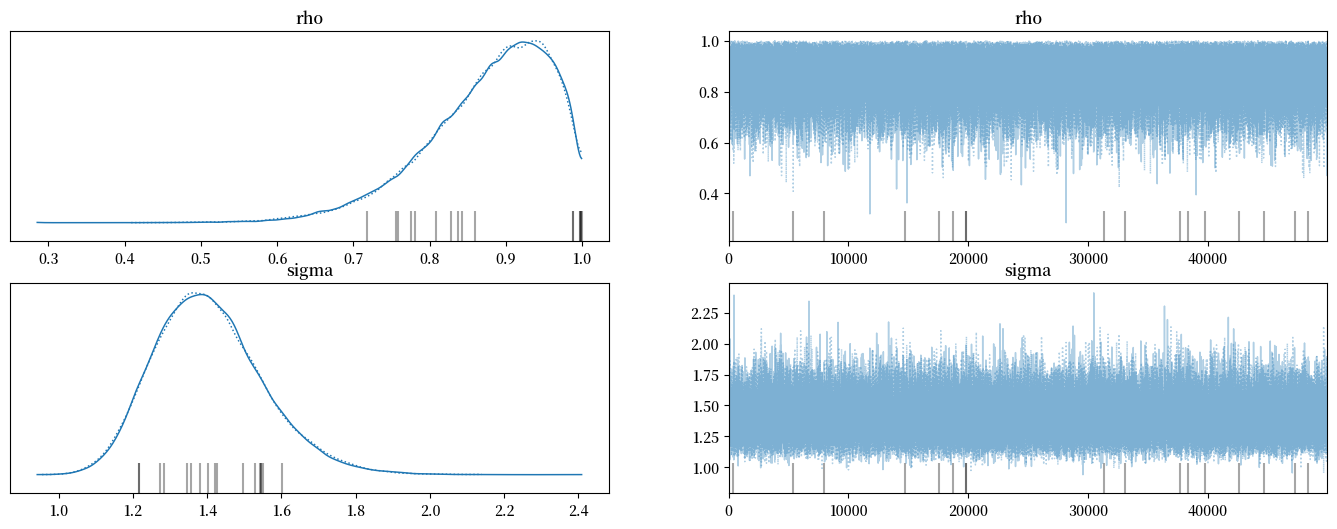
with AR1_model:
summary_y0 = az.summary(trace_y0, round_to=4)
summary_y0
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| rho | 0.8763 | 0.0814 | 0.7321 | 0.9990 | 0.0003 | 0.0003 | 54397.2920 | 39979.6959 | 1.0 |
| sigma | 1.4047 | 0.1473 | 1.1456 | 1.6896 | 0.0006 | 0.0006 | 67608.4101 | 53084.3474 | 1.0 |
请注意当我们基于\(y_0\)进行条件化而不是假设\(y_0\)来自平稳分布时,\(\rho\)的后验分布相对向右偏移。
思考一下为什么会发生这种情况。
提示
这与贝叶斯定律如何解决逆问题有关 - 它通过给那些能更好地解释观测数据的参数值分配更高的概率来实现这一点。
在我们使用numpyro来计算这两种关于\(y_0\)分布的假设下的后验分布之前,我们会回到这个问题。
我们现在用numpyro重复这些计算。
19.2. Numpyro实现#
def plot_posterior(sample):
"""
绘制轨迹和直方图
"""
# 转换为np数组
rhos = sample['rho']
sigmas = sample['sigma']
rhos, sigmas, = np.array(rhos), np.array(sigmas)
fig, axs = plt.subplots(2, 2, figsize=(17, 6))
# 绘制轨迹
axs[0, 0].plot(rhos) # rho
axs[1, 0].plot(sigmas) # sigma
# 绘制后验分布
axs[0, 1].hist(rhos, bins=50, density=True, alpha=0.7)
axs[0, 1].set_xlim([0, 1])
axs[1, 1].hist(sigmas, bins=50, density=True, alpha=0.7)
axs[0, 0].set_title("rho")
axs[0, 1].set_title("rho")
axs[1, 0].set_title("sigma")
axs[1, 1].set_title("sigma")
plt.show()
def AR1_model(data):
# 设置先验分布
rho = numpyro.sample('rho', dist.Uniform(low=-1., high=1.))
sigma = numpyro.sample('sigma', dist.HalfNormal(scale=np.sqrt(10)))
# 下一期y的期望值 (rho * y)
yhat = rho * data[:-1]
# 实际值的似然函数
y_data = numpyro.sample('y_obs', dist.Normal(loc=yhat, scale=sigma), obs=data[1:])
# 创建 jnp 数组
y = jnp.array(y)
# 设置 NUTS 核心
NUTS_kernel = numpyro.infer.NUTS(AR1_model)
# 运行 MCMC
mcmc = numpyro.infer.MCMC(NUTS_kernel, num_samples=50000, num_warmup=10000, progress_bar=False)
mcmc.run(rng_key=random.PRNGKey(1), data=y)
plot_posterior(mcmc.get_samples())
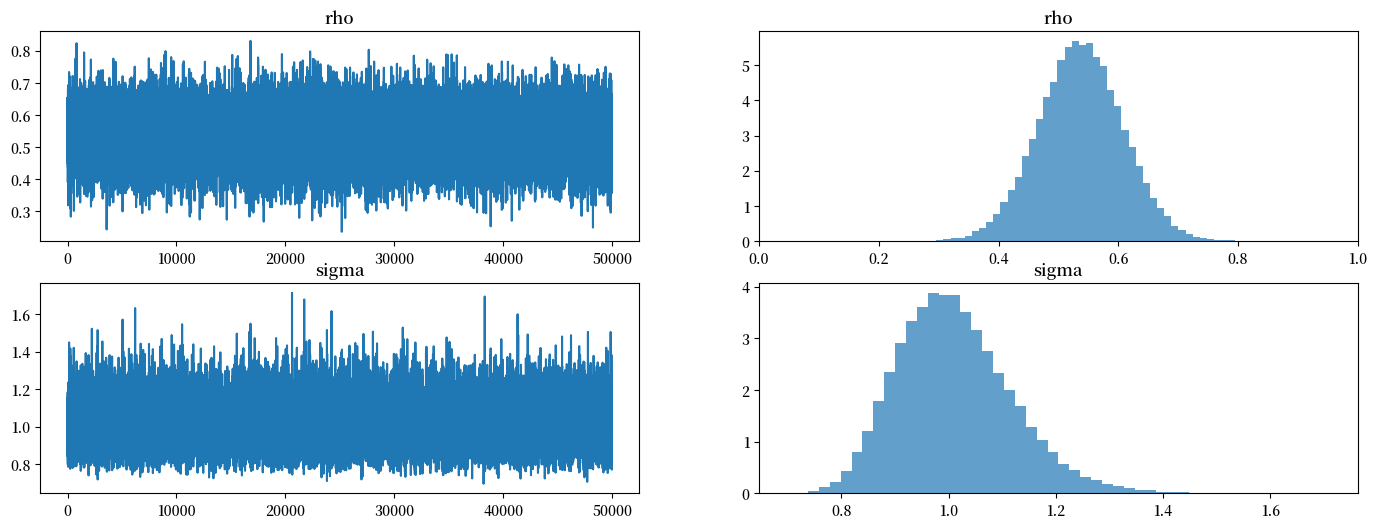
mcmc.print_summary()
mean std median 5.0% 95.0% n_eff r_hat
rho 0.54 0.07 0.54 0.42 0.65 39631.76 1.00
sigma 1.01 0.11 1.00 0.84 1.18 37869.08 1.00
Number of divergences: 0
接下来,我们再次计算后验分布,这次假设 \(y_0\) 是从平稳分布中抽取的,因此
以下是实现这一目的的新代码。
def AR1_model_y0(data):
# 设置先验分布
rho = numpyro.sample('rho', dist.Uniform(low=-1., high=1.))
sigma = numpyro.sample('sigma', dist.HalfNormal(scale=np.sqrt(10)))
# 平稳y的标准差
y_sd = sigma / jnp.sqrt(1 - rho**2)
# 下一期y的期望值(rho * y)
yhat = rho * data[:-1]
# 实际实现值的似然
y_data = numpyro.sample('y_obs', dist.Normal(loc=yhat, scale=sigma), obs=data[1:])
y0_data = numpyro.sample('y0_obs', dist.Normal(loc=0., scale=y_sd), obs=data[0])
# 创建jnp数组
y = jnp.array(y)
# 设置NUTS核心
NUTS_kernel = numpyro.infer.NUTS(AR1_model_y0)
# 运行MCMC
mcmc2 = numpyro.infer.MCMC(NUTS_kernel, num_samples=50000, num_warmup=10000, progress_bar=False)
mcmc2.run(rng_key=random.PRNGKey(1), data=y)
plot_posterior(mcmc2.get_samples())
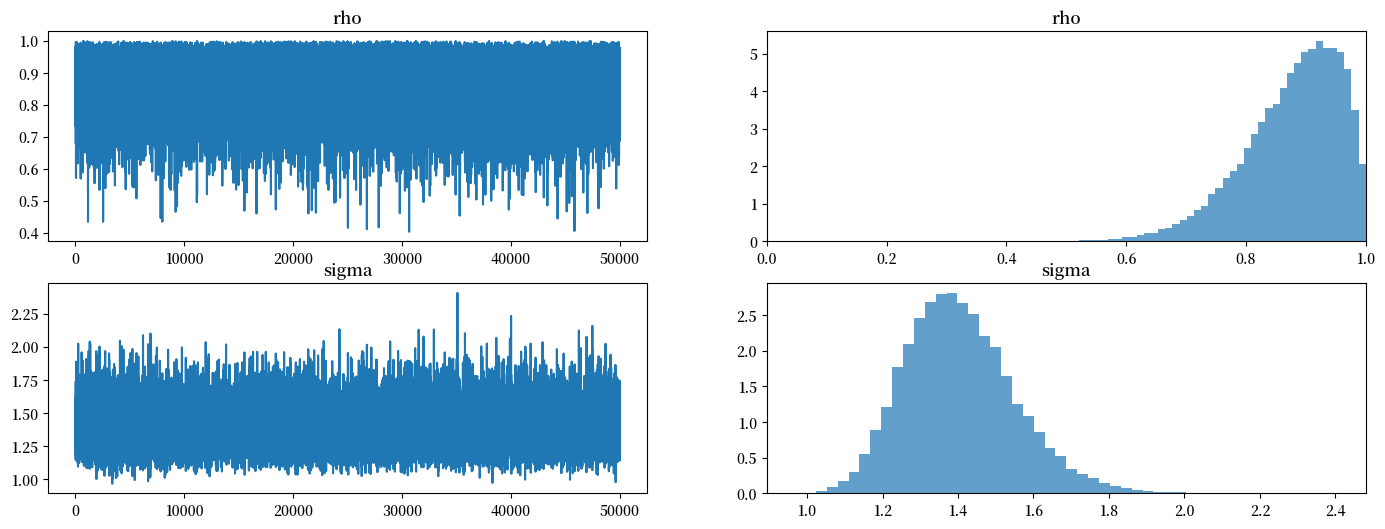
mcmc2.print_summary()
mean std median 5.0% 95.0% n_eff r_hat
rho 0.88 0.08 0.89 0.76 1.00 30336.42 1.00
sigma 1.40 0.15 1.39 1.17 1.63 25638.85 1.00
Number of divergences: 0
看看后验分布发生了什么!
贝叶斯推断试图通过调整参数来解释这个”异常”的初始观测值。这导致后验分布偏离了生成数据时使用的真实参数值。
贝叶斯定律通过驱使\(\rho \rightarrow 1\)和\(\sigma \uparrow\)来提高平稳分布的方差,从而能够为第一个观测值生成一个合理的似然。
这个例子很好地说明了在贝叶斯推断中,我们对初始条件分布的假设会对最终的推断结果产生重要影响。