46. 工作搜寻 V:职业选择建模#
除了Anaconda中已有的库外,本讲座还需要以下库:
!pip install quantecon
46.1. 概述#
接下来,我们研究一个关于职业和工作选择的计算问题。
这个模型最初由Derek Neal提出[Neal, 1999]。
本文的讲解借鉴了[Ljungqvist and Sargent, 2018]第6.5节的内容。
我们先导入一些包:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5)
import numpy as np
import quantecon as qe
from numba import jit, prange
from quantecon.distributions import BetaBinomial
from scipy.special import binom, beta
from mpl_toolkits.mplot3d.axes3d import Axes3D
from matplotlib import cm
46.1.1. 模型特点#
模型中的个体们通过选择职业和职业内的工作来最大化预期的贴现工资收入。
这是一个包含两个状态变量的无限期动态规划问题。
46.2. 模型#
在下文中,我们区分职业和工作,其中
职业被理解为包含许多工作的一个领域,而
工作被理解为在特定公司的一个职位
对于劳动者来说,工资可以分解为工作和职业的贡献
\(w_t = \theta_t + \epsilon_t\),其中
\(\theta_t\) 是在时间 \(t\) 职业的贡献
\(\epsilon_t\) 是在时间 \(t\) 工作的贡献
在时间 \(t\) 开始时,劳动者有以下选择
保持当前的(职业,工作)组合 \((\theta_t, \epsilon_t)\) — 以下简称为”原地不动”
保持当前职业 \(\theta_t\) 但重新选择工作 \(\epsilon_t\) — 以下简称为”新工作”
同时重新选择职业 \(\theta_t\) 和工作 \(\epsilon_t\) — 以下简称”新生活”
\(\theta\) 和 \(\epsilon\) 的抽取彼此独立,且与过去的值无关,其中:
\(\theta_t \sim F\)
\(\epsilon_t \sim G\)
注意,劳动者没有保留工作但重新选择职业的选项 — 开始新职业总是需要开始新工作。
年轻劳动者的目标是最大化折现工资的预期总和
且受限于上述的选择限制。
令 \(v(\theta, \epsilon)\) 表示价值函数,即在给定初始状态 \((\theta, \epsilon)\) 的情况下,所有可行的(职业,工作)策略中 (46.1) 的最大值。
价值函数满足
其中
显然 \(I\)、\(II\) 和 \(III\) 分别对应”原地不动”、“新工作”和”新生活”。
46.2.1. 参数化#
如同 [Ljungqvist and Sargent, 2018] 第6.5节所述,我们将关注模型的离散版本,参数设置如下:
\(\theta\) 和 \(\epsilon\) 的取值都在集合
np.linspace(0, B, grid_size)中 — 在 \(0\) 和 \(B\) 之间(包含端点)的均匀网格点grid_size = 50B = 5β = 0.95
分布 \(F\) 和 \(G\) 是离散分布,从网格点 np.linspace(0, B, grid_size) 中生成抽样。
Beta-二项分布族是一个非常有用的离散分布族,其概率质量函数为
Beta-二项分布可以通过以下两步生成:
首先从Beta分布中随机抽取一个概率值\(q\),该Beta分布由形状参数\((a,b)\)决定
然后进行\(n\)次独立的二项试验,每次试验以概率\(q\)成功
因此,\(p(k \,|\, n, a, b)\)表示在这个过程中恰好获得\(k\)次成功的概率。
这个分布族有以下优点:
形式灵活,可以产生多种分布形状,从均匀分布到各种单峰分布
参数少且直观,仅需要三个参数就能完全确定分布
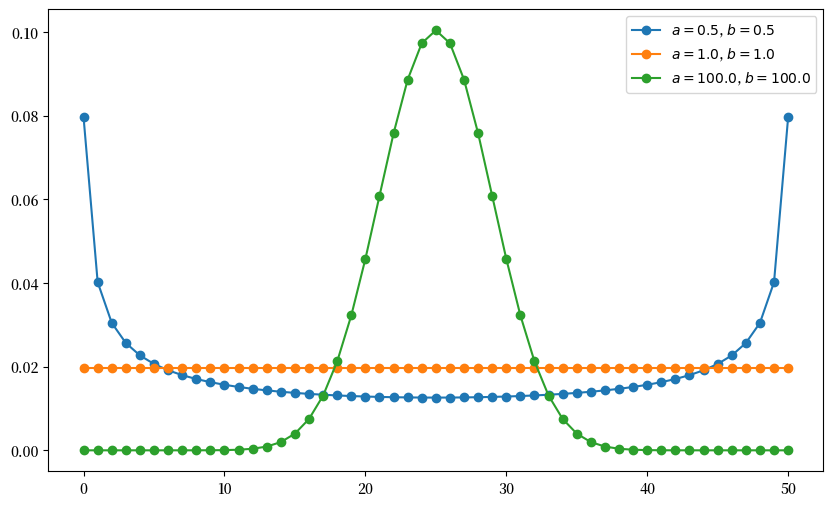
下图展示了当\(n=50\)时,不同形状参数对概率质量函数的影响。
def gen_probs(n, a, b):
probs = np.zeros(n+1)
for k in range(n+1):
probs[k] = binom(n, k) * beta(k + a, n - k + b) / beta(a, b)
return probs
n = 50
a_vals = [0.5, 1, 100]
b_vals = [0.5, 1, 100]
fig, ax = plt.subplots(figsize=(10, 6))
for a, b in zip(a_vals, b_vals):
ab_label = f'$a = {a:.1f}$, $b = {b:.1f}$'
ax.plot(list(range(0, n+1)), gen_probs(n, a, b), '-o', label=ab_label)
ax.legend()
plt.show()
46.3. 实现#
我们首先创建一个类 CareerWorkerProblem,它将保存模型的默认参数化和价值函数的初始猜测。
class CareerWorkerProblem:
def __init__(self,
B=5.0, # 上界
β=0.95, # 贴现因子
grid_size=50, # 网格大小
F_a=1,
F_b=1,
G_a=1,
G_b=1):
self.β, self.grid_size, self.B = β, grid_size, B
self.θ = np.linspace(0, B, grid_size) # θ值集合
self.ϵ = np.linspace(0, B, grid_size) # ϵ值集合
self.F_probs = BetaBinomial(grid_size - 1, F_a, F_b).pdf()
self.G_probs = BetaBinomial(grid_size - 1, G_a, G_b).pdf()
self.F_mean = np.sum(self.θ * self.F_probs)
self.G_mean = np.sum(self.ϵ * self.G_probs)
# 存储这些参数用于str和repr方法
self._F_a, self._F_b = F_a, F_b
self._G_a, self._G_b = G_a, G_b
以下函数接收一个CareerWorkerProblem实例,并返回相应的贝尔曼算子\(T\)和贪婪策略函数。
在此模型中,\(T\)由\(Tv(\theta, \epsilon) = \max\{I, II, III\}\)定义,其中\(I\)、\(II\)和\(III\)如(46.2)所示。
def operator_factory(cw, parallel_flag=True):
"""
返回经过jit编译的贝尔曼算子和贪婪策略函数
cw是一个``CareerWorkerProblem``实例
"""
θ, ϵ, β = cw.θ, cw.ϵ, cw.β
F_probs, G_probs = cw.F_probs, cw.G_probs
F_mean, G_mean = cw.F_mean, cw.G_mean
@jit(parallel=parallel_flag)
def T(v):
"贝尔曼算子"
v_new = np.empty_like(v)
for i in prange(len(v)):
for j in prange(len(v)):
v1 = θ[i] + ϵ[j] + β * v[i, j] # 保持现状
v2 = θ[i] + G_mean + β * v[i, :] @ G_probs # 新工作
v3 = G_mean + F_mean + β * F_probs @ v @ G_probs # 新生活
v_new[i, j] = max(v1, v2, v3)
return v_new
@jit
def get_greedy(v):
"计算v-贪婪策略"
σ = np.empty(v.shape)
for i in range(len(v)):
for j in range(len(v)):
v1 = θ[i] + ϵ[j] + β * v[i, j]
v2 = θ[i] + G_mean + β * v[i, :] @ G_probs
v3 = G_mean + F_mean + β * F_probs @ v @ G_probs
if v1 > max(v2, v3):
action = 1
elif v2 > max(v1, v3):
action = 2
else:
action = 3
σ[i, j] = action
return σ
return T, get_greedy
最后,solve_model将接收一个CareerWorkerProblem实例,并使用贝尔曼算子进行迭代,以找到贝尔曼方程的不动点。
def solve_model(cw,
use_parallel=True,
tol=1e-4,
max_iter=1000,
verbose=True,
print_skip=25):
T, _ = operator_factory(cw, parallel_flag=use_parallel)
# 设置循环
v = np.full((cw.grid_size, cw.grid_size), 100.) # 初始猜测
i = 0
error = tol + 1
while i < max_iter and error > tol:
v_new = T(v)
error = np.max(np.abs(v - v_new))
i += 1
if verbose and i % print_skip == 0:
print(f"Error at iteration {i} is {error}.")
v = v_new
if error > tol:
print("Failed to converge!")
elif verbose:
print(f"\nConverged in {i} iterations.")
return v_new
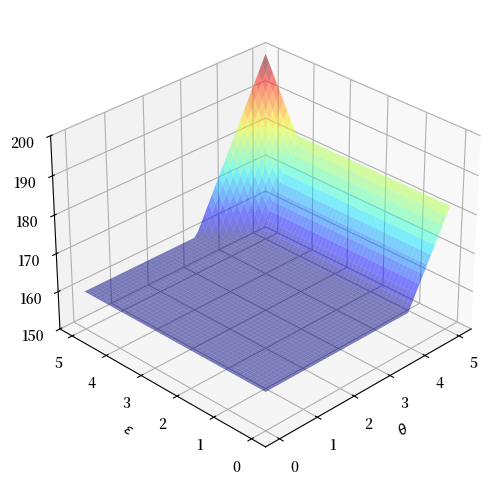
这是模型的解决方案 – 一个近似值函数
cw = CareerWorkerProblem()
T, get_greedy = operator_factory(cw)
v_star = solve_model(cw, verbose=False)
greedy_star = get_greedy(v_star)
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
tg, eg = np.meshgrid(cw.θ, cw.ϵ)
ax.plot_surface(tg,
eg,
v_star.T,
cmap=cm.jet,
alpha=0.5,
linewidth=0.25)
ax.set(xlabel=r'$\theta$', ylabel=r'$\epsilon$', zlim=(150, 200))
ax.view_init(ax.elev, 225)
plt.show()
这就是最优策略
fig, ax = plt.subplots(figsize=(6, 6))
tg, eg = np.meshgrid(cw.θ, cw.ϵ)
lvls = (0.5, 1.5, 2.5, 3.5)
ax.contourf(tg, eg, greedy_star.T, levels=lvls, cmap=cm.winter, alpha=0.5)
ax.contour(tg, eg, greedy_star.T, colors='k', levels=lvls, linewidths=2)
ax.set(xlabel=r'$\theta$', ylabel=r'$\epsilon$')
ax.text(1.8, 2.5, '新生活', fontsize=14)
ax.text(4.5, 2.5, '新工作', fontsize=14, rotation='vertical')
ax.text(4.0, 4.5, '维持现状', fontsize=14)
plt.show()

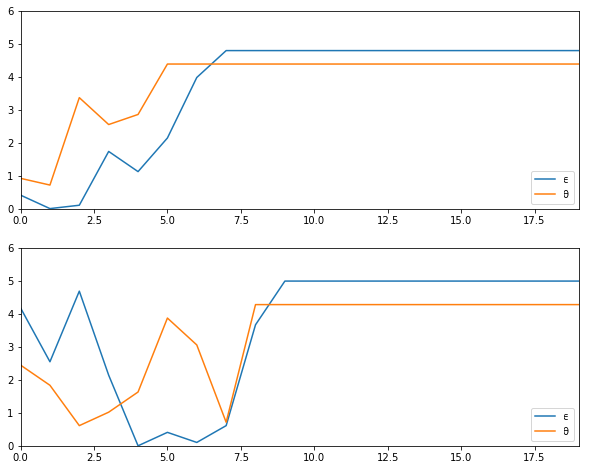
解释:
如果工作和职业都很差或一般,劳动者会尝试新的工作和新的职业。
如果职业足够好,劳动者会保持这个职业,并尝试新的工作直到找到一个足够好的工作。
如果工作和职业都很好,劳动者会保持现状。
注意,劳动者会倾向于保持一个好的职业发展方向,但是高薪工作却不一定会一直做下去。
原因是高终身工资需要职业方向和职业内的工作都很好,而且劳动者不能在不换工作的情况下换职业。
有时必须牺牲一个好工作来转向一个更好的职业。
46.4. 练习#
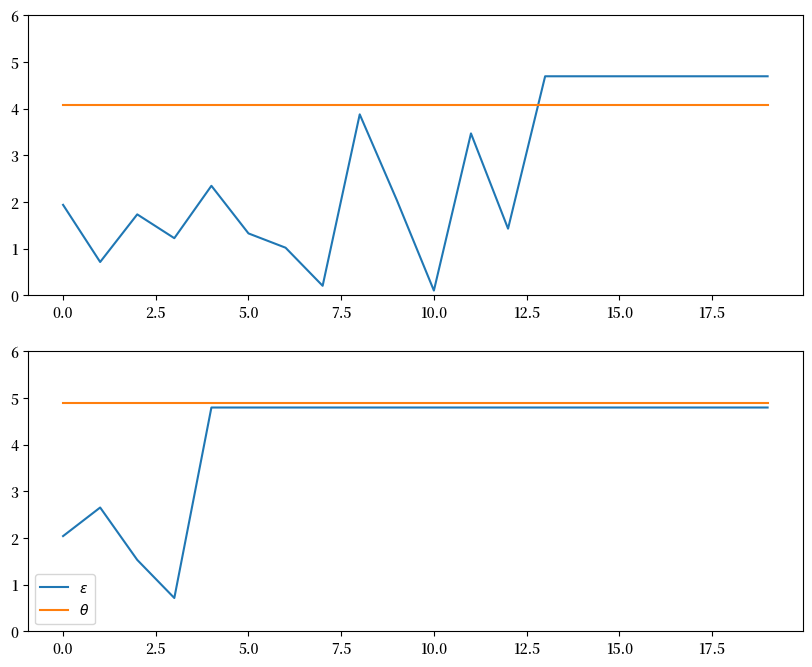
练习 46.1
使用 CareerWorkerProblem 类中的默认参数设置,
当劳动者遵循最优策略时,生成并绘制 \(\theta\) 和 \(\epsilon\) 的典型样本路径。
特别是,除了随机性之外,复现以下图形(其中横轴表示时间)
提示
要从分布\(F\)和\(G\)中生成抽样,请使用quantecon.random.draw()。
解答 练习 46.1
模拟工作/职业路径。
在阅读代码时,请注意optimal_policy[i, j] = 在\((\theta_i, \epsilon_j)\)处的策略 = 1、2或3;分别表示’保持现状’、‘新工作’和’新生活’。
F = np.cumsum(cw.F_probs)
G = np.cumsum(cw.G_probs)
v_star = solve_model(cw, verbose=False)
T, get_greedy = operator_factory(cw)
greedy_star = get_greedy(v_star)
def gen_path(optimal_policy, F, G, t=20):
i = j = 0
θ_index = []
ϵ_index = []
for t in range(t):
if optimal_policy[i, j] == 1: # 保持现状
pass
elif greedy_star[i, j] == 2: # 新工作
j = qe.random.draw(G)
else: # 新生活
i, j = qe.random.draw(F), qe.random.draw(G)
θ_index.append(i)
ϵ_index.append(j)
return cw.θ[θ_index], cw.ϵ[ϵ_index]
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
for ax in axes:
θ_path, ϵ_path = gen_path(greedy_star, F, G)
ax.plot(ϵ_path, label=r'$\epsilon$')
ax.plot(θ_path, label=r'$\theta$')
ax.set_ylim(0, 6)
plt.legend()
plt.show()
练习 46.2
现在让我们考虑从起点\((\theta, \epsilon) = (0, 0)\)开始,劳动者需要多长时间才能找到一份永久性工作。
换句话说,我们要研究这个随机变量的分布
显然,当且仅当\((\theta_t, \epsilon_t)\)进入\((\theta, \epsilon)\)空间的”保持不变”区域时,劳动者的工作才会变成永久性的。
令\(S\)表示这个区域,\(T^*\)可以表示为在最优策略下首次到达\(S\)的时间:
收集这个随机变量的25,000个样本并计算中位数(应该约为7)。
用\(\beta=0.99\)重复这个练习并解释变化。
解答 练习 46.2
原始参数下的中位数可以按如下方式计算
cw = CareerWorkerProblem()
F = np.cumsum(cw.F_probs)
G = np.cumsum(cw.G_probs)
T, get_greedy = operator_factory(cw)
v_star = solve_model(cw, verbose=False)
greedy_star = get_greedy(v_star)
@jit
def passage_time(optimal_policy, F, G):
t = 0
i = j = 0
while True:
if optimal_policy[i, j] == 1: # 保持不变
return t
elif optimal_policy[i, j] == 2: # 新工作
j = qe.random.draw(G)
else: # 新生活
i, j = qe.random.draw(F), qe.random.draw(G)
t += 1
@jit(parallel=True)
def median_time(optimal_policy, F, G, M=25000):
samples = np.empty(M)
for i in prange(M):
samples[i] = passage_time(optimal_policy, F, G)
return np.median(samples)
median_time(greedy_star, F, G)
7.0
要计算中位数时使用 \(\beta=0.99\) 而不是默认值 \(\beta=0.95\),请将 cw = CareerWorkerProblem() 替换为 cw = CareerWorkerProblem(β=0.99)。
这些中位数会受随机性影响,但应该分别约为7和14。
不出所料,更有耐心的劳动者会等待更长时间才会安定在最终的工作岗位上。
练习 46.3
将参数设置为 G_a = G_b = 100 并生成一个新的最优策略图 – 解释。
解答 练习 46.3
这是一个解决方案
cw = CareerWorkerProblem(G_a=100, G_b=100)
T, get_greedy = operator_factory(cw)
v_star = solve_model(cw, verbose=False)
greedy_star = get_greedy(v_star)
fig, ax = plt.subplots(figsize=(6, 6))
tg, eg = np.meshgrid(cw.θ, cw.ϵ)
lvls = (0.5, 1.5, 2.5, 3.5)
ax.contourf(tg, eg, greedy_star.T, levels=lvls, cmap=cm.winter, alpha=0.5)
ax.contour(tg, eg, greedy_star.T, colors='k', levels=lvls, linewidths=2)
ax.set(xlabel=r'$\theta$', ylabel=r'$\epsilon$')
ax.text(1.8, 2.5, '新生活', fontsize=14)
ax.text(4.5, 1.5, '新工作', fontsize=14, rotation='vertical')
ax.text(4.0, 4.5, '保持现状', fontsize=14)
plt.show()
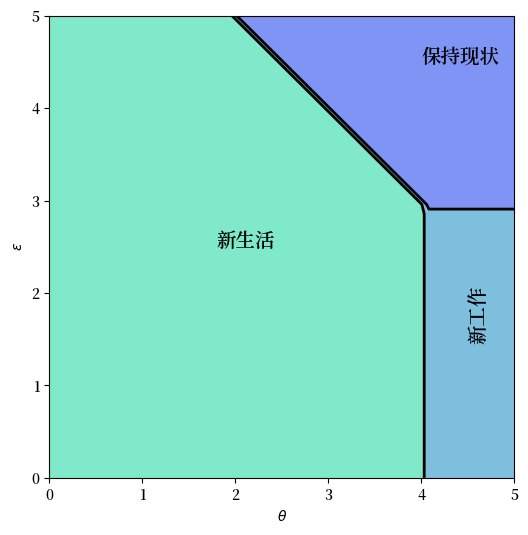
在新图中,你可以看到劳动者选择留在原地的区域变大了,这是因为 \(\epsilon\) 的分布更加集中在均值附近,使得高薪工作的可能性降低了。