62. 收入波动问题 II:资产随机收益#
除了 Anaconda 中的内容外,本讲座还需要以下库:
!pip install quantecon
62.1. 概述#
在本讲座中,我们继续研究 收入波动问题。
之前假设利率是固定的,但现在我们允许资产收益随状态变化。
这符合大多数拥有正资产的家庭面临资本收入风险这一事实。
有人认为,建模资本收入风险对于理解收入和财富的联合分布至关重要(参见,例如,[Benhabib et al., 2015] 或 [Stachurski and Toda, 2019])。
本文提出的家庭储蓄模型的理论性质在 [Ma et al., 2020] 中有详细分析。
在计算方面,我们结合时间迭代和内生网格方法来快速准确地求解模型。
我们需要以下导入:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
import numpy as np
from numba import jit, float64
from numba.experimental import jitclass
from quantecon import MarkovChain
62.2. 储蓄问题#
在本节中,我们回顾家庭问题及其最优性结果。
62.2.1. 设定#
家庭选择消费-资产路径 \(\{(c_t, a_t)\}\) 以最大化
受约束于
初始条件 \((a_0, Z_0)=(a,z)\) 视为给定。
注意,财富的总收益率序列 \({R_t}_{t \geq 1}\) 允许是随机的。
序列 \(\{Y_t \}_{t \geq 1}\) 是非金融收入。
问题的随机成分服从
其中
映射 \(R\) 和 \(Y\) 是时不变的非负函数,
创新过程 \(\{\zeta_t\}\) 和 \(\{\eta_t\}\) 独立同分布且相互独立,
\(\{Z_t\}_{t \geq 0}\) 是有限集 \(\mathsf Z\) 上的不可约齐次马尔可夫链
令 \(P\) 表示链 \(\{Z_t\}_{t \geq 0}\) 的马尔可夫矩阵。
我们对偏好的假设与 之前的讲座 中关于收入波动问题的假设相同。
如前所述,\(\mathbb E_z \hat X\) 表示给定当前值 \(Z = z\) 时下一期值 \(\hat X\) 的期望。
62.2.2. 假设#
我们需要一些限制条件来确保目标 (62.1) 是有限的,并且下面描述的解法能够收敛。
我们还需要确保财富的现值值不会增长得太快。
当 \(\{R_t\}\) 是常数时,我们要求 \(\beta R < 1\)。
现在它是随机的,我们要求
注意,当 \(\{R_t\}\) 取某个常数值 \(R\) 时,这一条件简化为之前的限制 \(\beta R < 1\)
值 \(G_R\) 可以理解为长期(几何)平均总收益率。
[Ma et al., 2020]提供了(62.4) 背后的更多直觉。
我们在下面讨论如何检验该条件。
最后,我们对非金融收入施加一些常规的技术性限制:
一个相对简单且满足所有这些限制的环境是 [Benhabib et al., 2015] 的独立同分布和 CRRA 环境。
62.2.3. 最优性#
令候选消费政策类 \(\mathscr C\) 的定义 如前。
在 [Ma et al., 2020] 中证明,在所述假设下,
任何满足欧拉方程的 \(\sigma \in \mathscr C\) 都是最优政策,且
在 \(\mathscr C\) 中恰好存在一个这样的政策。
在当前设定中,欧拉方程的形式为
(直觉和推导与我们在 早期讲座 中关于收入波动问题的内容类似。)
我们再次使用时间迭代来求解欧拉方程,使用 Coleman–Reffett 算子 \(K\) 来匹配欧拉方程 (62.5)。
62.3. 求解算法#
62.3.1. 时间迭代算子#
我们对候选类 \(\sigma \in \mathscr C\) 消费政策的定义与之前关于收入波动问题的讲座中的定义相同。
对于固定的 \(\sigma \in \mathscr C\) 和 \((a,z) \in \mathbf S\),函数 \(K\sigma\) 在 \((a,z)\) 处的值 \(K\sigma(a,z)\) 定义为满足以下方程的 \(\xi \in (0,a]\)
\(K\) 背后的思想是,从定义可以看出,\(\sigma \in \mathscr C\) 满足欧拉方程当且仅当对于所有 \((a, z) \in \mathbf S\) 都有 \(K\sigma(a, z) = \sigma(a, z)\)。
这意味着 \(K\) 在 \(\mathscr C\) 中的不动点和最优消费政策完全重合(更多细节参见 [Ma et al., 2020])。
62.3.2. 收敛性质#
如前所述,我们在 \(\mathscr C\) 上定义如下度量
可以证明
\((\mathscr C, \rho)\) 是一个完备度量空间,
存在一个整数 \(n\) 使得 \(K^n\) 是 \((\mathscr C, \rho)\) 上的压缩映射,且
\(K\) 在 \(\mathscr C\) 中的唯一不动点是 \(\mathscr C\) 中的唯一最优政策。
现在,我们有了一个清晰的路径来成功地逼近最优政策:选择某个 \(\sigma \in \mathscr C\) 然后用 \(K\) 迭代直到收敛(用距离 \(\rho\) 衡量)。
62.3.3. 使用内生网格#
在研究该模型时,我们发现可以通过 内生网格方法 进一步加速时间迭代。
我们将在这里使用相同的方法。
该方法与最优增长模型的方法相同,只是需要记住消费并不总是内部的。
特别是,当资产水平较低时,最优消费可能等于资产。
62.3.3.1. 寻找最优消费#
内生网格方法(EGM)要求我们取一个储蓄值网格 \(s_i\),其中每个这样的 \(s\) 被解释为 \(s = a - c\)。
对于最低的网格点,我们取 \(s_0 = 0\)。
对于相应的 \(a_0, c_0\) 对,我们有 \(a_0 = c_0\)。
这发生在接近原点的地方,资产较低,家庭消费其所能消费的一切。
虽然有许多解,但我们取 \(a_0 = c_0 = 0\),这固定了原点处的政策,有助于插值。
对于 \(s > 0\),根据定义,我们有 \(c < a\),因此消费是内部的。
因此 (62.5) 的最大值部分消失,我们在每个 \(s_i\) 处求解
62.3.3.2. 迭代#
一旦我们得到 \({s_i, c_i}\) 对,内生资产网格通过 \(a_i = c_i + s_i\) 获得。
另外,在上面的讨论中我们固定了 \(z \in \mathsf Z\),所以可以将其与 \(a_i\) 配对。
通过在每个 \(z\) 上对 \({a_i, c_i}\) 插值,就可以得到政策 \((a,z) \mapsto \sigma(a,z)\) 的近似。
在下面的内容中,我们使用线性插值。
62.3.4. 检验假设#
时间迭代的收敛性依赖于条件 \(\beta G_R < 1\) 的满足。
我们可以利用 \(G_R\) 等于矩阵 \(L\) 的谱半径这一事实来检验。矩阵 \(L\) 定义为
这个恒等式在 [Ma et al., 2020] 中得到证明,其中 \(\phi\) 是资产收益创新 \(\zeta_t\) 的密度函数。
(注意,\(\mathsf Z\) 是一个有限集,所以这个表达式定义了一个矩阵。)
当 \(\{R_t\}\) 是独立同分布时,检查这一条件甚更容易。
在这种情况下,从 \(G_R\) 的定义可以清楚地看出 \(G_R\) 就是 \(\mathbb E R_t\)。
我们在下面的代码中检验条件 \(\beta \mathbb E R_t < 1\)。
62.4. 实现#
我们将假设 \(R_t = \exp(a_r \zeta_t + b_r)\),其中 \(a_r, b_r\) 是常数,\(\{\zeta_t\}\) 是独立同分布的标准正态。
我们允许劳动收入相关,即
其中 \(\{\eta_t\}\) 也是独立同分布的标准正态,\(\{ Z_t\}\) 是取值于 \(\{0, 1\}\) 的马尔可夫链。
ifp_data = [
('γ', float64), # 效用参数
('β', float64), # 折现因子
('P', float64[:, :]), # z_t 的转移概率
('a_r', float64), # R_t 的尺度参数
('b_r', float64), # R_t 的加性参数
('a_y', float64), # Y_t 的尺度参数
('b_y', float64), # Y_t 的加性参数
('s_grid', float64[:]), # 储蓄网格
('η_draws', float64[:]), # 用于 MC 的创新 η 的抽取
('ζ_draws', float64[:]) # 用于 MC 的创新 ζ 的抽取
]
@jitclass(ifp_data)
class IFP:
"""
用于收入波动问题的基本类
"""
def __init__(self,
γ=1.5,
β=0.96,
P=np.array([(0.9, 0.1),
(0.1, 0.9)]),
a_r=0.1,
b_r=0.0,
a_y=0.2,
b_y=0.5,
shock_draw_size=50,
grid_max=10,
grid_size=100,
seed=1234):
np.random.seed(seed) # 任意随机种子
self.P, self.γ, self.β = P, γ, β
self.a_r, self.b_r, self.a_y, self.b_y = a_r, b_r, a_y, b_y
self.η_draws = np.random.randn(shock_draw_size)
self.ζ_draws = np.random.randn(shock_draw_size)
self.s_grid = np.linspace(0, grid_max, grid_size)
# 假设 ${R_t}$ 独立同分布并服从下面给定的对数正态分布设定,进行稳定性检验。
# 检验 β E R_t < 1。
ER = np.exp(b_r + a_r**2 / 2)
assert β * ER < 1, "稳定性条件不成立。"
# 边际效用
def u_prime(self, c):
return c**(-self.γ)
# 边际效用的逆函数
def u_prime_inv(self, c):
return c**(-1/self.γ)
def R(self, z, ζ):
return np.exp(self.a_r * ζ + self.b_r)
def Y(self, z, η):
return np.exp(self.a_y * η + (z * self.b_y))
这是基于 EGM 的 Coleman-Reffett 算子:
@jit
def K(a_in, σ_in, ifp):
"""
收入波动问题的 Coleman--Reffett 算子,
使用内生网格方法。
* ifp 是 IFP 的实例
* a_in[i, z] 是资产网格
* σ_in[i, z] 是在 a_in[i, z] 处的消费
"""
# 简化名称
u_prime, u_prime_inv = ifp.u_prime, ifp.u_prime_inv
R, Y, P, β = ifp.R, ifp.Y, ifp.P, ifp.β
s_grid, η_draws, ζ_draws = ifp.s_grid, ifp.η_draws, ifp.ζ_draws
n = len(P)
# 通过线性插值创建消费函数
σ = lambda a, z: np.interp(a, a_in[:, z], σ_in[:, z])
# 分配内存
σ_out = np.empty_like(σ_in)
# 在每个 s_i, z 处获得 c_i,存储在 σ_out[i, z] 中,
# 通过蒙特卡洛计算期望项
for i, s in enumerate(s_grid):
for z in range(n):
# 计算期望
Ez = 0.0
for z_hat in range(n):
for η in ifp.η_draws:
for ζ in ifp.ζ_draws:
R_hat = R(z_hat, ζ)
Y_hat = Y(z_hat, η)
U = u_prime(σ(R_hat * s + Y_hat, z_hat))
Ez += R_hat * U * P[z, z_hat]
Ez = Ez / (len(η_draws) * len(ζ_draws))
σ_out[i, z] = u_prime_inv(β * Ez)
# 计算内生资产网格
a_out = np.empty_like(σ_out)
for z in range(n):
a_out[:, z] = s_grid + σ_out[:, z]
# 在 (0, 0) 处固定消费-资产对有助于插值
σ_out[0, :] = 0
a_out[0, :] = 0
return a_out, σ_out
下一个函数通过时间迭代求解最优消费政策的近似。
def solve_model_time_iter(model, # 包含模型信息的类
a_vec, # 资产的初始条件
σ_vec, # 消费的初始条件
tol=1e-4,
max_iter=1000,
verbose=True,
print_skip=25):
# 设置循环
i = 0
error = tol + 1
while i < max_iter and error > tol:
a_new, σ_new = K(a_vec, σ_vec, model)
error = np.max(np.abs(σ_vec - σ_new))
i += 1
if verbose and i % print_skip == 0:
print(f"第{i}迭代的误差是 {error}。")
a_vec, σ_vec = np.copy(a_new), np.copy(σ_new)
if error > tol:
print("未能收敛!")
elif verbose:
print(f"\n在第{i}次迭代中收敛。")
return a_new, σ_new
现在我们可以用默认参数创建一个实例。
ifp = IFP()
接下来我们设置一个初始条件,对应“消费掉所有资产”。
# 初始猜测 σ = 消费所有资产
k = len(ifp.s_grid)
n = len(ifp.P)
σ_init = np.empty((k, n))
for z in range(n):
σ_init[:, z] = ifp.s_grid
a_init = np.copy(σ_init)
让我们生成一个近似解。
a_star, σ_star = solve_model_time_iter(ifp, a_init, σ_init, print_skip=5)
第5迭代的误差是 0.5081944529506552。
第10迭代的误差是 0.1057246950930697。
第15迭代的误差是 0.03658262202883744。
第20迭代的误差是 0.013936729965906114。
第25迭代的误差是 0.00529216526971199。
第30迭代的误差是 0.0019748126990770665。
第35迭代的误差是 0.0007219210463285108。
第40迭代的误差是 0.0002590544496094971。
第45迭代的误差是 9.163966595471251e-05。
在第45次迭代中收敛。
这是结果消费政策的图:
fig, ax = plt.subplots()
for z in range(len(ifp.P)):
ax.plot(a_star[:, z], σ_star[:, z], label=f"当 $z={z}$ 时的消费")
plt.legend()
plt.show()
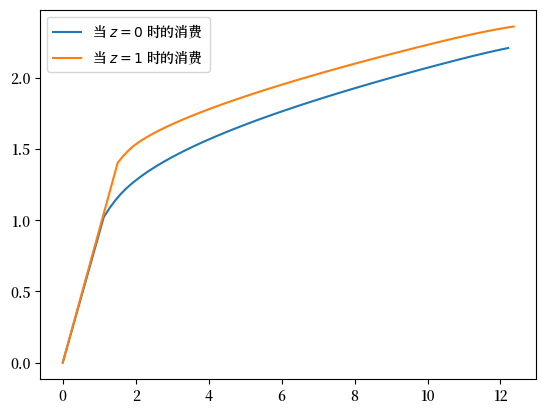
注意,在资产空间的较低区间,我们会消费掉所有资产。
这是因为我们预期下一期会有收入 \(Y_{t+1}\),因此储蓄的紧迫性较低。
你能解释为什么在 \(z=0\) 时,消费掉所有资产会更早结束(即在较低的资产水平就停止)吗?
62.4.1. 运动规律#
让我们试着了解,在这种消费政策下,从长期来看资产会如何变化。
与我们在 之前关于收入波动问题的讲座 中一样,我们首先制作一个 45 度图,展示资产的运动规律:
# 好状态和坏状态的平均劳动收入
Y_mean = [np.mean(ifp.Y(z, ifp.η_draws)) for z in (0, 1)]
# 平均收益
R_mean = np.mean(ifp.R(z, ifp.ζ_draws))
a = a_star
fig, ax = plt.subplots()
for z, lb in zip((0, 1), ('坏状态', '好状态')):
ax.plot(a[:, z], R_mean * (a[:, z] - σ_star[:, z]) + Y_mean[z] , label=lb)
ax.plot(a[:, 0], a[:, 0], 'k--')
ax.set(xlabel='当前资产', ylabel='下一期资产')
ax.legend()
plt.show()

图中实线表示对于每个 \(z\),资产的平均更新函数,由下式给出:
其中
\(\bar R = \mathbb E R_t\),即平均收益率,且
\(\bar Y(z) = \mathbb E_z Y(z, \eta_t)\),即状态 \(z\) 下的平均劳动收入。
虚线是 45 度线。
从图中可以看出,动态是稳定的——即使在最高的状态下,资产也不会发散。
62.5. 练习#
练习 62.1
让我们重复 之前的练习,研究资产的长期横截面分布。
在那个练习中,我们使用了一个相对简单的收入波动模型。
在解答中,我们发现资产分布的形状不切实际。
特别是,我们未能匹配财富分布的长右尾。
你的任务是再次尝试这个练习,但这一次使用我们更复杂的模型。
使用默认参数。
解答 练习 62.1
首先我们编写一个函数来生成一个较长的资产序列。
因为我们希望用 JIT 来编译函数,所以在写代码时不得不打破一些良好的编程风格。
例如,我们会把解 a_star, σ_star 以及 ifp 一起传入,尽管更自然的方式是只传入 ifp 然后在函数内求解。
我们这样做的原因是 solve_model_time_iter 不是 JIT 编译的。
@jit
def compute_asset_series(ifp, a_star, σ_star, z_seq, T=500_000):
"""
在最优储蓄行为下,模拟长度为 T 的资产时间序列
* ifp 是 IFP 的实例
* a_star 是内生网格解
* σ_star 是网格上的最优消费
* z_seq 是 {Z_t} 的时间路径
"""
# 通过线性插值创建消费函数
σ = lambda a, z: np.interp(a, a_star[:, z], σ_star[:, z])
# 模拟资产路径
a = np.zeros(T+1)
for t in range(T):
z = z_seq[t]
ζ, η = np.random.randn(), np.random.randn()
R = ifp.R(z, ζ)
Y = ifp.Y(z, η)
a[t+1] = R * (a[t] - σ(a[t], z)) + Y
return a
接下来,我们调用该函数,生成资产序列,并利用上面的解来绘制直方图。
T = 1_000_000
mc = MarkovChain(ifp.P)
z_seq = mc.simulate(T, random_state=1234)
a = compute_asset_series(ifp, a_star, σ_star, z_seq, T=T)
fig, ax = plt.subplots()
ax.hist(a, bins=40, alpha=0.5, density=True)
ax.set(xlabel='资产')
plt.show()
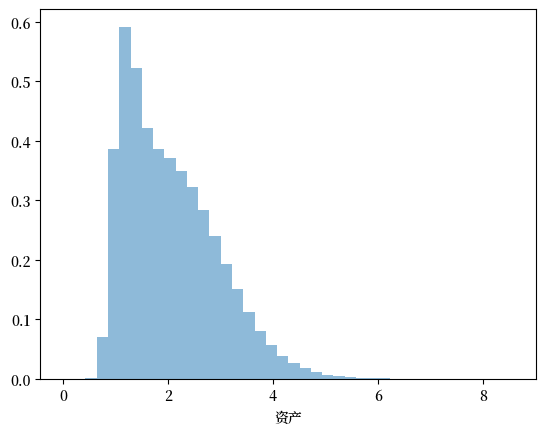
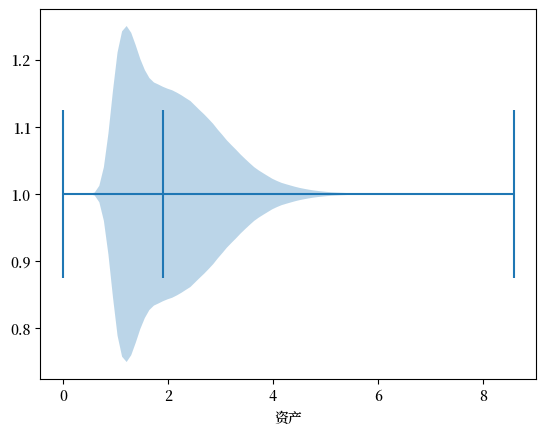
我们现在已经成功再现了财富分布的长右尾。
下面用一张水平小提琴图来展示这一结果的另一种视角。
fig, ax = plt.subplots()
ax.violinplot(a, vert=False, showmedians=True)
ax.set(xlabel='资产')
plt.show()