73. 不确定性陷阱#
73.1. 概述#
在本讲座中,我们将学习Fajgelbaum、Schaal和Taschereau-Dumouchel [Fajgelbaum et al., 2015]提出的不确定性陷阱模型的简化版本。
该模型展示了自我强化的不确定性如何对经济活动产生重大影响。
在模型中,
基本面随机变化且不能被完全观察。
在任何时刻都有活跃和不活跃的企业家;只有活跃的企业家进行生产。
个体(包括活跃和非活跃的企业家)对基本面持有以概率分布表示的信念。
更大的不确定性意味着这些分布的离散程度更高。
企业家具有风险规避特性,因此在不确定性高时较少倾向于保持活跃。
活跃企业家的产出是可观察的,提供了一个带噪声的信号,帮助模型内的所有人推断基本面。
企业家通过贝叶斯法则更新他们对基本面的信念,这通过卡尔曼滤波来实现。
不确定性陷阱之所以出现,是因为:
高度不确定性使企业家不愿保持活跃。
低参与度(即活跃企业家数量较少)减少了关于基本面的信息流。
信息减少转化为更高的不确定性,进一步阻碍企业家选择保持活跃,如此循环。
不确定性陷阱源于一种正外部性:高水平的总体经济活动会产生有价值的信息。
让我们从一些标准导入开始:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5) #设置默认图形大小
import numpy as np
73.2. 模型#
[Fajgelbaum et al., 2015]中描述的原始模型有许多有趣的组成部分。
我们将研究一个简化版本,但它仍然包含了许多关键思想。
73.2.1. 基本原理#
基本过程\(\{\theta_t\}\)的演变由以下公式给出:
其中
\(\sigma_\theta > 0\) 且 \(0 < \rho < 1\)
\(\{w_t\}\)是独立同分布的标准正态分布
随机变量\(\theta_t\)在任何时间点都是不可观察的。
73.2.2. 产出#
总共有\(\bar M\)个风险规避的企业家。
第\(m\)个企业家在\(t\)时刻处于活跃状态时的条件产出等于
这里为了简化符号省略了时间下标。
冲击方差的倒数\(\gamma_x\)被称为冲击的精确度。
精度越高,\(x_m\) 对基本面的信息含量就越大。
输出冲击在时间和企业之间是相互独立的。
73.2.3. 信息和信念#
所有企业家最初对 \(\theta_0\) 都持有相同的信念。
信号是公开可观察的,因此所有主体始终持有相同的信念。
省略时间下标后,对当前 \(\theta\) 的信念用正态分布 \(N(\mu, \gamma^{-1})\) 表示。
这里 \(\gamma\) 是信念的精度;其倒数是不确定性的程度。
这些参数通过卡尔曼滤波进行更新。
令
\(\mathbb M \subset \{1, \ldots, \bar M\}\) 表示当前活跃企业的集合。
\(M := |\mathbb M|\) 表示当前活跃企业的数量。
\(X\) 是活跃企业的平均产出 \(\frac{1}{M} \sum_{m \in \mathbb M} x_m\)。
使用这些符号,并用撇号表示下一期的值,我们可以将均值和精度的更新写作
这些是标准卡尔曼滤波结果应用于当前设置。
练习1提供了关于(73.2)和(73.3)如何推导的更多细节,然后要求你填写剩余的步骤。
下图以45度图的形式绘制了(73.3)中精度的运动规律,每条曲线对应一个\(M \in \{0, \ldots, 6\}\)。
其他参数值为\(\rho = 0.99, \gamma_x = 0.5, \sigma_\theta =0.5\)
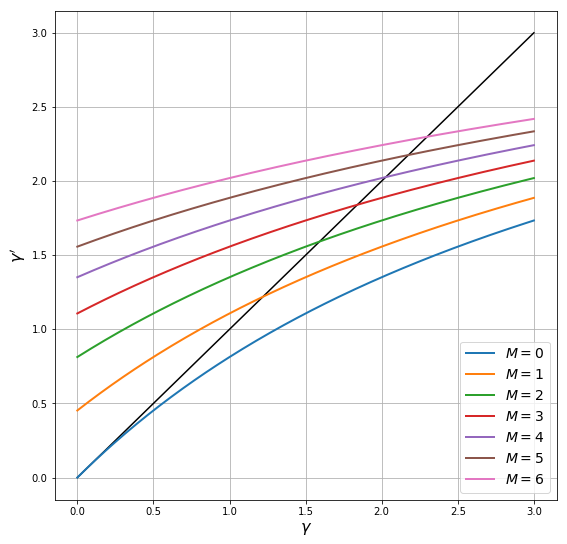
曲线与45度线相交的点是不同\(M\)值对应的精度的长期稳态。
因此,如果这些\(M\)值中的一个保持固定,相应的稳态就是精度的均衡水平。
较高的 \(M\) 值对应着对基本面有更多的信息,因此在稳态下有更高的精确度
较低的 \(M\) 值对应着较少的信息,在稳态下有更多的不确定性
实际上,正如我们将看到的,活跃企业的数量会随机波动。
73.2.4. 参与#
再次省略时间下标,如果满足以下条件,企业家会在当前期进入市场:
这里
\(x_m\) 的数学期望基于 (73.1) 和对 \(\theta\) 的信念 \(N(\mu, \gamma^{-1})\)
\(F_m\) 是一个随机但可预见的固定成本,在时间和企业间相互独立
\(c\) 是反映机会成本的常数
\(F_m\) 是可预见的这一说法意味着它在期初就已实现,并在 (73.4) 中被视为常数。
效用函数具有常数绝对风险厌恶形式:
其中 \(a\) 是一个正参数。
将(73.4)和(73.5)结合,当满足以下条件时,企业家 \(m\) 参与市场(或称为活跃):
使用对数正态随机变量期望的标准公式,这等价于以下条件
73.3. 实现#
我们要模拟这个经济。
作为第一步,让我们创建一个类来整合
参数、\(\theta\) 的当前值以及两个信念参数 \(\mu\) 和 \(\gamma\) 的当前值
更新 \(\theta\)、\(\mu\) 和 \(\gamma\) 的方法,以及确定活跃企业数量及其产出的方法
更新方法遵循上述 \(\theta\)、\(\mu\) 和 \(\gamma\) 的运动规律。
评估活跃企业数量的方法会生成 \(F_1, \ldots, F_{\bar M}\) 并对每个企业测试条件 (73.6)。
init 方法将我们在下面模拟中使用的参数编码为默认值
class UncertaintyTrapEcon:
def __init__(self,
a=1.5, # 风险厌恶
γ_x=0.5, # 生产冲击精度
ρ=0.99, # θ的相关系数
σ_θ=0.5, # θ冲击的标准差
num_firms=100, # 企业数量
σ_F=1.5, # 固定成本的标准差
c=-420, # 外部机会成本
μ_init=0, # μ的初始值
γ_init=4, # γ的初始值
θ_init=0): # θ的初始值
# == 记录值 == #
self.a, self.γ_x, self.ρ, self.σ_θ = a, γ_x, ρ, σ_θ
self.num_firms, self.σ_F, self.c, = num_firms, σ_F, c
self.σ_x = np.sqrt(1/γ_x)
# == 初始化状态 == #
self.γ, self.μ, self.θ = γ_init, μ_init, θ_init
def ψ(self, F):
temp1 = -self.a * (self.μ - F)
temp2 = self.a**2 * (1/self.γ + 1/self.γ_x) / 2
return (1 / self.a) * (1 - np.exp(temp1 + temp2)) - self.c
def update_beliefs(self, X, M):
"""
基于总量X和M更新信念(μ, γ)。
"""
# 简化名称
γ_x, ρ, σ_θ = self.γ_x, self.ρ, self.σ_θ
# 更新μ
temp1 = ρ * (self.γ * self.μ + M * γ_x * X)
temp2 = self.γ + M * γ_x
self.μ = temp1 / temp2
# 更新γ
self.γ = 1 / (ρ**2 / (self.γ + M * γ_x) + σ_θ**2)
def update_θ(self, w):
"""
根据冲击w更新基本状态θ。
"""
self.θ = self.ρ * self.θ + self.σ_θ * w
def gen_aggregates(self):
"""
基于当前信念(μ, γ)生成总量。这是一个
依赖于F抽样的模拟步骤。
"""
F_vals = self.σ_F * np.random.randn(self.num_firms)
M = np.sum(self.ψ(F_vals) > 0) # 计算活跃企业数量
if M > 0:
x_vals = self.θ + self.σ_x * np.random.randn(M)
X = x_vals.mean()
else:
X = 0
return X, M
在下面的结果中,我们使用这段代码来模拟主要变量的时间序列。
73.4. 结果#
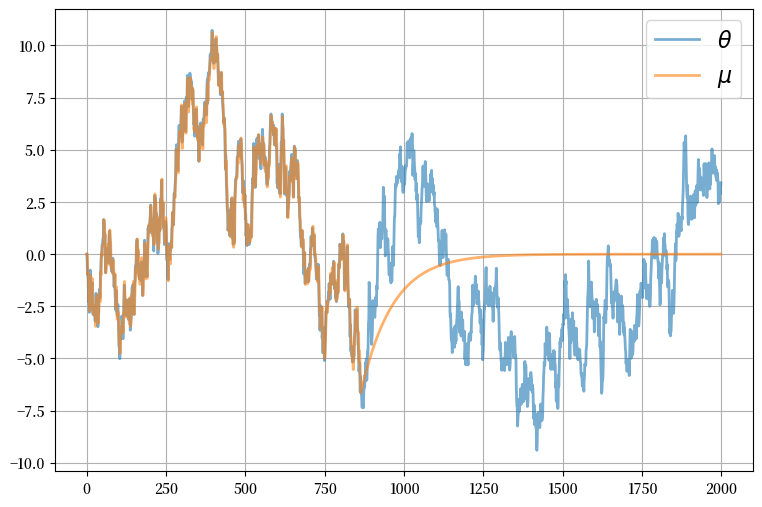
让我们首先看看\(\mu\)的动态变化,这是代理用来追踪\(\theta\)的
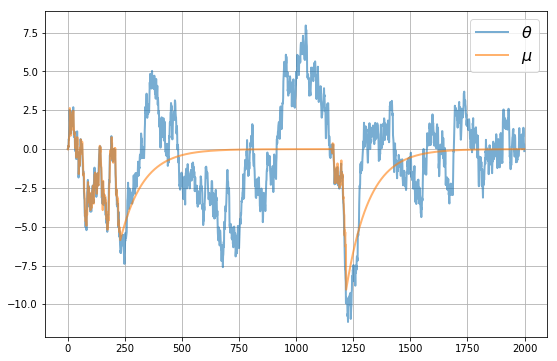
我们可以看到,当市场中有足够多的企业时,\(\mu\)能很好地追踪\(\theta\)。
然而,有时由于信息不足,\(\mu\)对\(\theta\)的追踪效果很差。
这些就是不确定性陷阱发生的时期。
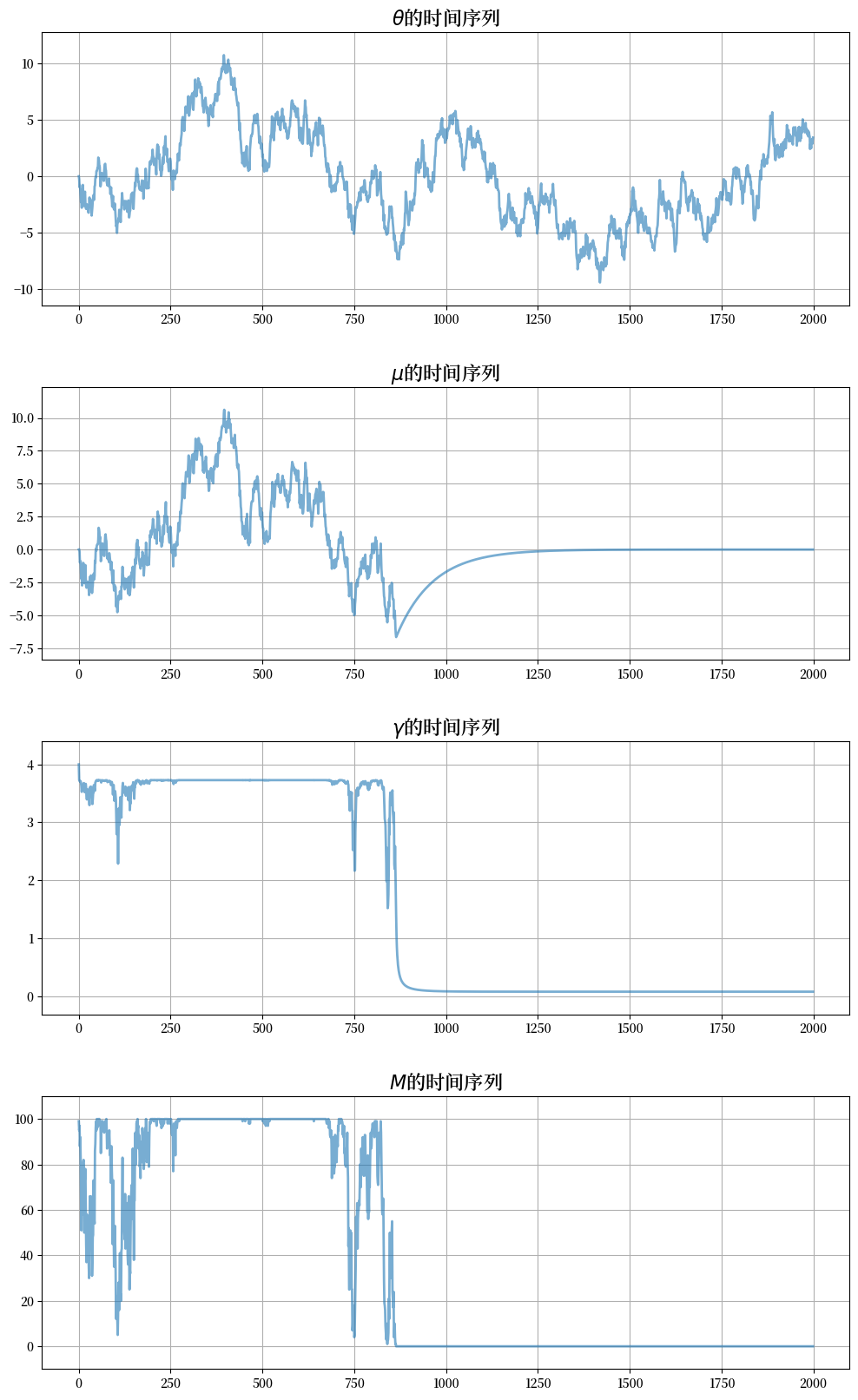
在这些时期
精确度低,不确定性高
市场中的企业数量很少
为了更清楚地了解这种动态变化,让我们一次性查看所有主要时间序列在给定冲击下的表现
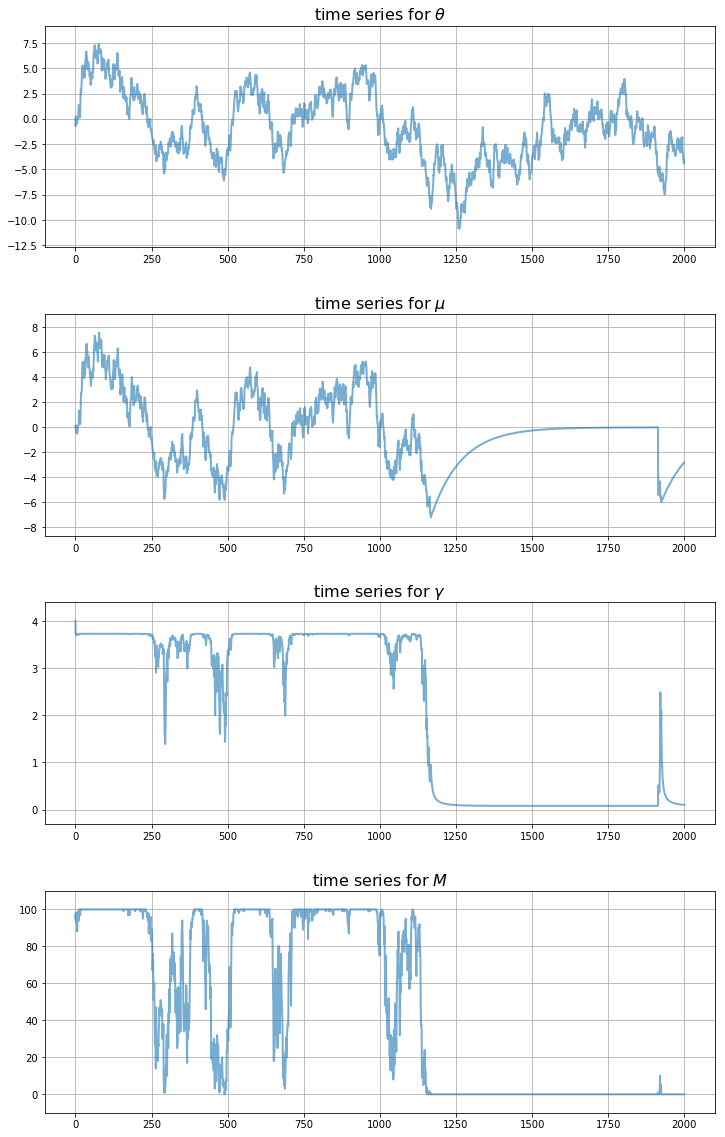
注意观察这些陷阱是如何在基本面经历一系列不利冲击后才形成的。
因此,该模型为我们提供了一个传播机制,将不良的随机抽样映射为经济活动的长期下滑。
73.5. 练习#
练习 73.1
根据以下标准结果(参见[Young and Smith, 2005]第24页),填写(73.2)和(73.3)背后的详细内容。
事实 设\(\mathbf x = (x_1, \ldots, x_M)\)是来自共同分布\(N(\theta, 1/\gamma_x)\)的独立同分布抽样向量,\(\bar x\)为样本均值。如果已知\(\gamma_x\),且\(\theta\)的先验分布为\(N(\mu, 1/\gamma)\),则给定\(\mathbf x\)时\(\theta\)的后验分布为
其中
解答 练习 73.1
本练习要求你根据所述内容验证讲座中给出的\(\gamma\)和\(\mu\)的运动规律
关于标量高斯设置中贝叶斯更新的结果。所述结果告诉我们,在观察了 \(M\) 个公司的平均输出 \(X\) 后,我们的后验信念将是
其中
如果我们取一个具有这种分布的随机变量 \(\theta\),然后评估 \(\rho \theta + \sigma_\theta w\) 的分布,其中 \(w\) 是独立的标准正态分布,我们就能得到讲座中给出的 \(\mu'\) 和 \(\gamma'\) 的表达式。
练习 73.2
除去随机性,复现上面显示的模拟图。
使用 UncertaintyTrapEcon 类的 init 方法中列出的默认参数值。
解答 练习 73.2
首先,让我们复现说明精度运动规律的图,即
这里的 \(M\) 是活跃企业的数量。下图在45度图上绘制了不同 \(M\) 值下 \(\gamma_{t+1}\) 对 \(\gamma_t\) 的关系
econ = UncertaintyTrapEcon()
ρ, σ_θ, γ_x = econ.ρ, econ.σ_θ, econ.γ_x # 简化名称
γ = np.linspace(1e-10, 3, 200) # γ 网格
fig, ax = plt.subplots(figsize=(9, 9))
ax.plot(γ, γ, 'k-') # 45度线
for M in range(7):
γ_next = 1 / (ρ**2 / (γ + M * γ_x) + σ_θ**2)
label_string = f"$M = {M}$"
ax.plot(γ, γ_next, lw=2, label=label_string)
ax.legend(loc='lower right', fontsize=14)
ax.set_xlabel(r'$\gamma$', fontsize=16)
ax.set_ylabel(r"$\gamma'$", fontsize=16)
ax.grid()
plt.show()
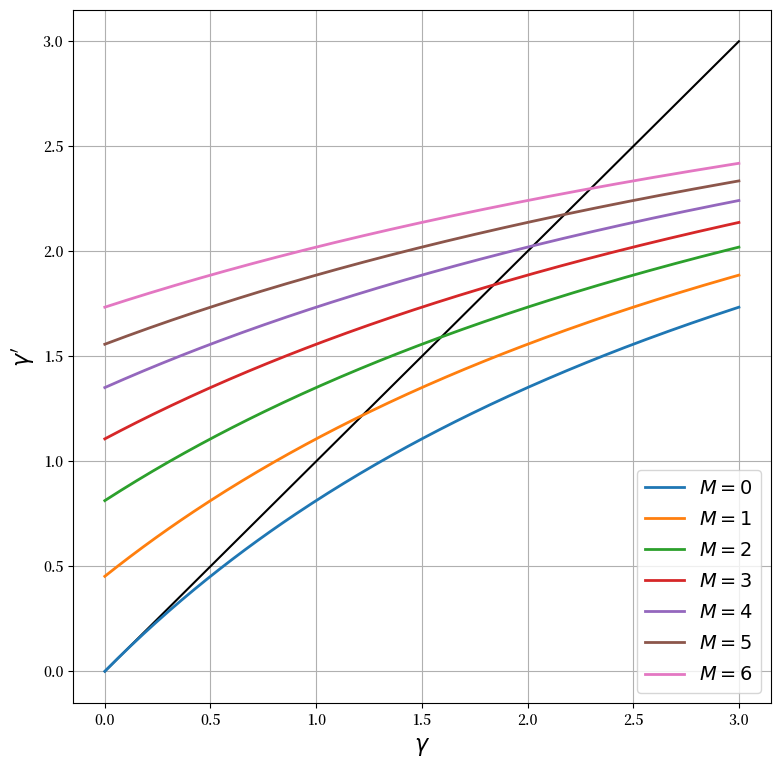
曲线与45度线相交的点是对应每个\(M\)的长期稳态,这是在\(M\)值保持固定的情况下。随着企业数量的减少,精确度的长期稳态也随之下降。
接下来让我们生成信念和总量的时间序列数据——即活跃企业数量和平均产出
sim_length=2000
μ_vec = np.empty(sim_length)
θ_vec = np.empty(sim_length)
γ_vec = np.empty(sim_length)
X_vec = np.empty(sim_length)
M_vec = np.empty(sim_length)
μ_vec[0] = econ.μ
γ_vec[0] = econ.γ
θ_vec[0] = 0
w_shocks = np.random.randn(sim_length)
for t in range(sim_length-1):
X, M = econ.gen_aggregates()
X_vec[t] = X
M_vec[t] = M
econ.update_beliefs(X, M)
econ.update_θ(w_shocks[t])
μ_vec[t+1] = econ.μ
γ_vec[t+1] = econ.γ
θ_vec[t+1] = econ.θ
# 记录总量的最终值
X, M = econ.gen_aggregates()
X_vec[-1] = X
M_vec[-1] = M
首先,让我们看看在这些模拟中 \(\mu\) 是如何跟踪 \(\theta\) 的
fig, ax = plt.subplots(figsize=(9, 6))
ax.plot(range(sim_length), θ_vec, alpha=0.6, lw=2, label=r"$\theta$")
ax.plot(range(sim_length), μ_vec, alpha=0.6, lw=2, label=r"$\mu$")
ax.legend(fontsize=16)
ax.grid()
plt.show()
现在让我们把所有内容一起绘制出来
fig, axes = plt.subplots(4, 1, figsize=(12, 20))
# 添加一些间距
fig.subplots_adjust(hspace=0.3)
series = (θ_vec, μ_vec, γ_vec, M_vec)
names = r'$\theta$', r'$\mu$', r'$\gamma$', r'$M$'
for ax, vals, name in zip(axes, series, names):
# 确定合适的y轴范围
s_max, s_min = max(vals), min(vals)
s_range = s_max - s_min
y_max = s_max + s_range * 0.1
y_min = s_min - s_range * 0.1
ax.set_ylim(y_min, y_max)
# 绘制序列
ax.plot(range(sim_length), vals, alpha=0.6, lw=2)
ax.set_title(f"{name}的时间序列", fontsize=16)
ax.grid()
plt.show()
如果你运行上面的代码,当然会得到不同的图表。
尝试使用不同的参数来观察它们对时间序列的影响。
(尝试对冲击使用非高斯分布也会很有趣,但这是一个较大的练习,因为这会超出标准卡尔曼滤波器的范畴)