21. 统计散度度量#
21.1. 概述#
统计散度用于量化两个不同概率分布之间的差异,这些分布可能难以区分,原因如下:
在一个分布下具有正概率的每个事件在另一个分布下也具有正概率
这意味着没有”确凿证据”事件的发生能让统计学家确定数据一定服从其中某一个概率分布
统计散度是一个将两个概率分布映射到非负实数的函数。
统计散度函数在统计学、信息论和现在许多人称之为”机器学习”的领域中发挥着重要作用。
本讲座描述了三种散度度量:
库尔贝克-莱布勒(KL)散度
Jensen-Shannon (JS) 散度
切尔诺夫熵
这些概念将在多个 quantecon 课程中出现。
让我们首先导入必要的 Python 工具。
import matplotlib.pyplot as plt
import numpy as np
from numba import vectorize, jit
from math import gamma
from scipy.integrate import quad
from scipy.optimize import minimize_scalar
import pandas as pd
from IPython.display import display, Math
21.2. 熵、交叉熵、KL散度入门#
在深入之前,我们先介绍一些有用的基本概念。
我们暂时假设 \(f\) 和 \(g\) 是离散随机变量在状态空间 \(I = \{1, 2, \ldots, n\}\) 上的两个概率质量函数,满足 \(f_i \geq 0, \sum_{i} f_i =1, g_i \geq 0, \sum_{i} g_i =1\)。
我们遵循一些统计学家和信息论学家的做法,将从分布 \(f\) 中观察到单次抽样 \(x = i\) 所关联的惊奇度或惊奇量定义为
他们进一步将从单次实现中预期获得的信息量定义为期望惊奇度
Claude Shannon [Shannon, 1948] 将 \(H(f)\) 称为分布 \(f\) 的熵。
备注
通过对 \(\{f_1, f_2, \ldots, f_n\}\) 在约束 \(\sum_i f_i = 1\) 下最大化 \(H(f)\),我们可以验证使熵最大化的分布是均匀分布 \( f_i = \frac{1}{n} . \) 均匀分布的熵 \(H(f)\) 显然等于 \(- \log(n)\)。
Kullback 和 Leibler [Kullback and Leibler, 1951] 将单次抽样 \(x\) 用于区分 \(f\) 和 \(g\) 所提供的信息量定义为对数似然比
以下两个概念被广泛用于比较两个分布 \(f\) 和 \(g\)。
交叉熵:
Kullback-Leibler (KL) 散度:
这些概念通过以下等式相关联。
要证明(21.3),注意到
记住\(H(f)\)是从\(f\)中抽取\(x\)时的预期惊异度。
那么上述等式告诉我们,KL散度是当预期\(x\)是从\(f\)中抽取而实际上是从\(g\)中抽取时产生的预期”额外惊异度”。
21.3. 两个Beta分布:运行示例#
我们将广泛使用Beta分布来说明概念。
Beta分布特别方便,因为它定义在\([0,1]\)上,并且通过适当选择其两个参数可以呈现多样的形状。
具有参数\(a\)和\(b\)的Beta分布的密度函数为
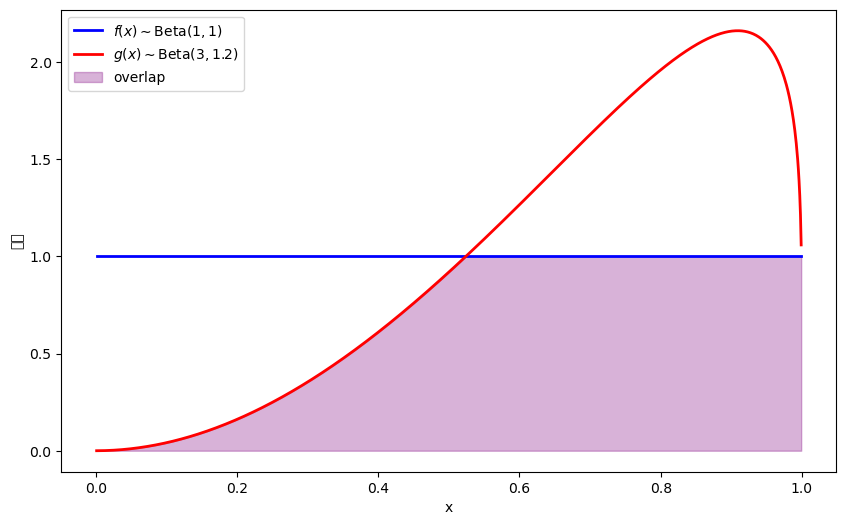
我们引入两个Beta分布\(f(x)\)和\(g(x)\),我们将用它们来说明不同的散度度量。
让我们在Python中定义参数和密度函数
# 两个Beta分布中的参数
F_a, F_b = 1, 1
G_a, G_b = 3, 1.2
@vectorize
def p(x, a, b):
r = gamma(a + b) / (gamma(a) * gamma(b))
return r * x** (a-1) * (1 - x) ** (b-1)
# 两个密度函数
f = jit(lambda x: p(x, F_a, F_b))
g = jit(lambda x: p(x, G_a, G_b))
# 绘制分布图
x_range = np.linspace(0.001, 0.999, 1000)
f_vals = [f(x) for x in x_range]
g_vals = [g(x) for x in x_range]
plt.figure(figsize=(10, 6))
plt.plot(x_range, f_vals, 'b-', linewidth=2, label=r'$f(x) \sim \text{Beta}(1,1)$')
plt.plot(x_range, g_vals, 'r-', linewidth=2, label=r'$g(x) \sim \text{Beta}(3,1.2)$')
# 填充重叠区域
overlap = np.minimum(f_vals, g_vals)
plt.fill_between(x_range, 0, overlap, alpha=0.3, color='purple', label='overlap')
plt.xlabel('x')
plt.ylabel('密度')
plt.legend()
plt.show()
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 23494 (\N{CJK UNIFIED IDEOGRAPH-5BC6}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 24230 (\N{CJK UNIFIED IDEOGRAPH-5EA6}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
21.4. Kullback–Leibler散度#
我们的第一个散度函数是Kullback–Leibler (KL)散度。
对于概率密度(或概率质量函数)\(f\)和\(g\),它的定义为
我们可以将\(D_{KL}(f\|g)\)解释为当数据由\(f\)生成而我们使用\(g\)时产生的预期超额对数损失(预期超额意外性)。
它有几个重要的性质:
非负性(Gibbs不等式):\(D_{KL}(f\|g) \ge 0\),当且仅当\(f\)几乎处处等于\(g\)时取等号
不对称性:\(D_{KL}(f\|g) \neq D_{KL}(g\|f)\)(因此它不是度量)
信息分解: \(D_{KL}(f\|g) = H(f,g) - H(f)\),其中\(H(f,g)\)是交叉熵,\(H(f)\)是\(f\)的Shannon熵
链式法则:对于联合分布\(f(x, y)\)和\(g(x, y)\), \(D_{KL}(f(x,y)\|g(x,y)) = D_{KL}(f(x)\|g(x)) + E_{f}\left[D_{KL}(f(y|x)\|g(y|x))\right]\)
KL散度在统计推断中扮演着核心角色,包括模型选择和假设检验。
似然比过程描述了KL散度与预期对数似然比之间的联系, 而讲座让弥尔顿·弗里德曼困惑的问题将其与序贯概率比检验的测试性能联系起来。
让我们计算示例分布\(f\)和\(g\)之间的KL散度。
def compute_KL(f, g):
"""
通过数值积分计算KL散度KL(f, g)
"""
def integrand(w):
fw = f(w)
gw = g(w)
return fw * np.log(fw / gw)
val, _ = quad(integrand, 1e-5, 1-1e-5)
return val
# 计算我们示例分布之间的KL散度
kl_fg = compute_KL(f, g)
kl_gf = compute_KL(g, f)
print(f"KL(f, g) = {kl_fg:.4f}")
print(f"KL(g, f) = {kl_gf:.4f}")
KL(f, g) = 0.7590
KL(g, f) = 0.3436
KL散度的不对称性具有重要的实际意义。
\(D_{KL}(f\|g)\) 惩罚那些 \(f > 0\) 但 \(g\) 接近零的区域,反映了使用 \(g\) 来建模 \(f\) 的代价,反之亦然。
21.5. Jensen-Shannon散度#
有时我们需要一个对称的散度度量,用来衡量两个分布之间的差异,而不偏向任何一方。
这种情况经常出现在聚类等应用中,我们想要比较分布,但不假设其中一个是真实模型。
Jensen-Shannon (JS) 散度通过将两个分布与它们的混合分布进行比较来使KL散度对称化:
其中 \(m\) 是对 \(f\) 和 \(g\) 取平均的混合分布
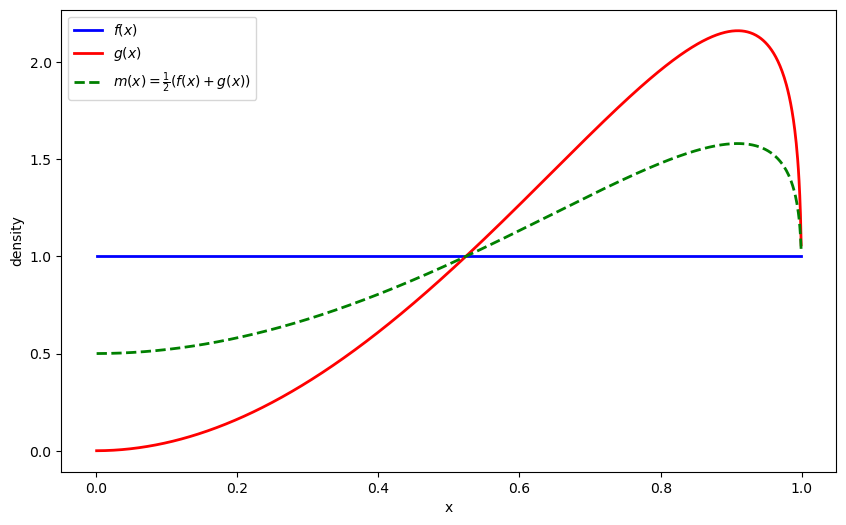
让我们也可视化混合分布 \(m\):
def m(x):
return 0.5 * (f(x) + g(x))
m_vals = [m(x) for x in x_range]
plt.figure(figsize=(10, 6))
plt.plot(x_range, f_vals, 'b-', linewidth=2, label=r'$f(x)$')
plt.plot(x_range, g_vals, 'r-', linewidth=2, label=r'$g(x)$')
plt.plot(x_range, m_vals, 'g--', linewidth=2, label=r'$m(x) = \frac{1}{2}(f(x) + g(x))$')
plt.xlabel('x')
plt.ylabel('density')
plt.legend()
plt.show()
JS散度具有以下几个有用的性质:
对称性:\(JS(f,g)=JS(g,f)\)。
有界性:\(0 \le JS(f,g) \le \log 2\)。
其平方根\(\sqrt{JS}\)在概率分布空间上是一个度量(Jensen-Shannon距离)。
JS散度等于二元随机变量\(Z \sim \text{Bernoulli}(1/2)\)(用于指示源)与样本\(X\)之间的互信息,其中当\(Z=0\)时\(X\)从\(f\)抽样,当\(Z=1\)时从\(g\)抽样。
Jensen-Shannon散度在某些生成模型的优化中起着关键作用,因为它是有界的、对称的,且比KL散度更平滑,通常能为训练提供更稳定的梯度。
让我们计算示例分布\(f\)和\(g\)之间的JS散度
def compute_JS(f, g):
"""计算Jensen-Shannon散度。"""
def m(w):
return 0.5 * (f(w) + g(w))
js_div = 0.5 * compute_KL(f, m) + 0.5 * compute_KL(g, m)
return js_div
js_div = compute_JS(f, g)
print(f"Jensen-Shannon散度 JS(f,g) = {js_div:.4f}")
Jensen-Shannon散度 JS(f,g) = 0.0984
我们可以使用带权重 \(\alpha = (\alpha_i)_{i=1}^{n}\) 的广义 Jensen-Shannon 散度轻松推广到两个以上的分布:
其中:
\(\alpha_i \geq 0\) 且 \(\sum_{i=1}^n \alpha_i = 1\),以及
\(H(f) = -\int f(x) \log f(x) dx\) 是分布 \(f\) 的香农熵
21.6. Chernoff 熵#
Chernoff 熵源自大偏差理论的早期应用,该理论通过提供罕见事件的指数衰减率来改进中心极限近似。
对于密度函数 \(f\) 和 \(g\),Chernoff 熵为
注释:
内部积分是 Chernoff 系数。
当 \(\phi=1/2\) 时,它变成 Bhattacharyya 系数 \(\int \sqrt{f g}\)。
在具有 \(T\) 个独立同分布观测的二元假设检验中,最优错误概率以 \(e^{-C(f,g) T}\) 的速率衰减。
我们将在 似然比过程 讲座中看到第三点的一个例子, 我们将在模型选择的背景下研究 Chernoff 熵。
让我们计算示例分布 \(f\) 和 \(g\) 之间的 Chernoff 熵。
def chernoff_integrand(ϕ, f, g):
"""计算给定 ϕ 的 Chernoff 熵中的积分。"""
def integrand(w):
return f(w)**ϕ * g(w)**(1-ϕ)
result, _ = quad(integrand, 1e-5, 1-1e-5)
return result
def compute_chernoff_entropy(f, g):
"""计算 Chernoff 熵 C(f,g)。"""
def objective(ϕ):
return chernoff_integrand(ϕ, f, g)
result = minimize_scalar(objective, bounds=(1e-5, 1-1e-5), method='bounded')
min_value = result.fun
ϕ_optimal = result.x
chernoff_entropy = -np.log(min_value)
return chernoff_entropy, ϕ_optimal
C_fg, ϕ_optimal = compute_chernoff_entropy(f, g)
print(f"Chernoff 熵 C(f,g) = {C_fg:.4f}")
print(f"最优 ϕ = {ϕ_optimal:.4f}")
Chernoff 熵 C(f,g) = 0.1212
最优 ϕ = 0.5969
21.7. 比较散度度量#
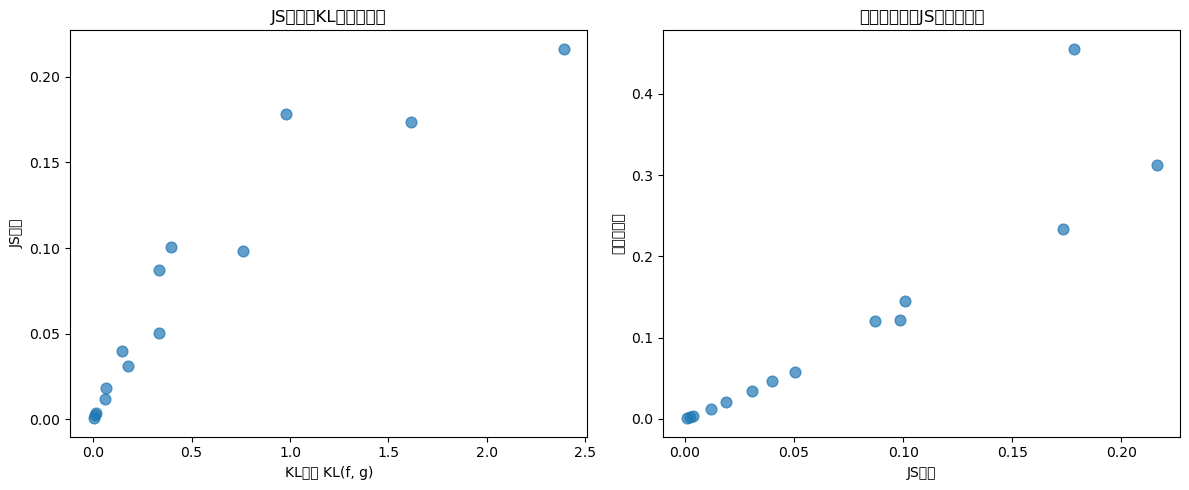
我们现在比较几对Beta分布之间的这些度量
当我们改变Beta分布的参数时,我们可以清楚地看到各种散度测度之间的协同变化。
接下来我们可视化KL散度、JS散度和切尔诺夫熵之间的关系。
kl_fg_values = [float(result['KL(f, g)']) for result in results]
js_values = [float(result['JS']) for result in results]
chernoff_values = [float(result['C']) for result in results]
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].scatter(kl_fg_values, js_values, alpha=0.7, s=60)
axes[0].set_xlabel('KL散度 KL(f, g)')
axes[0].set_ylabel('JS散度')
axes[0].set_title('JS散度与KL散度的关系')
axes[1].scatter(js_values, chernoff_values, alpha=0.7, s=60)
axes[1].set_xlabel('JS散度')
axes[1].set_ylabel('切尔诺夫熵')
axes[1].set_title('切尔诺夫熵与JS散度的关系')
plt.tight_layout()
plt.show()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 25955 (\N{CJK UNIFIED IDEOGRAPH-6563}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 24230 (\N{CJK UNIFIED IDEOGRAPH-5EA6}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 19982 (\N{CJK UNIFIED IDEOGRAPH-4E0E}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 30340 (\N{CJK UNIFIED IDEOGRAPH-7684}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 20851 (\N{CJK UNIFIED IDEOGRAPH-5173}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 31995 (\N{CJK UNIFIED IDEOGRAPH-7CFB}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 20999 (\N{CJK UNIFIED IDEOGRAPH-5207}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 23572 (\N{CJK UNIFIED IDEOGRAPH-5C14}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 35834 (\N{CJK UNIFIED IDEOGRAPH-8BFA}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 22827 (\N{CJK UNIFIED IDEOGRAPH-592B}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/105462246.py:17: UserWarning: Glyph 29109 (\N{CJK UNIFIED IDEOGRAPH-71B5}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 25955 (\N{CJK UNIFIED IDEOGRAPH-6563}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 24230 (\N{CJK UNIFIED IDEOGRAPH-5EA6}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 19982 (\N{CJK UNIFIED IDEOGRAPH-4E0E}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 30340 (\N{CJK UNIFIED IDEOGRAPH-7684}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20851 (\N{CJK UNIFIED IDEOGRAPH-5173}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 31995 (\N{CJK UNIFIED IDEOGRAPH-7CFB}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20999 (\N{CJK UNIFIED IDEOGRAPH-5207}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 23572 (\N{CJK UNIFIED IDEOGRAPH-5C14}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 35834 (\N{CJK UNIFIED IDEOGRAPH-8BFA}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 22827 (\N{CJK UNIFIED IDEOGRAPH-592B}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 29109 (\N{CJK UNIFIED IDEOGRAPH-71B5}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
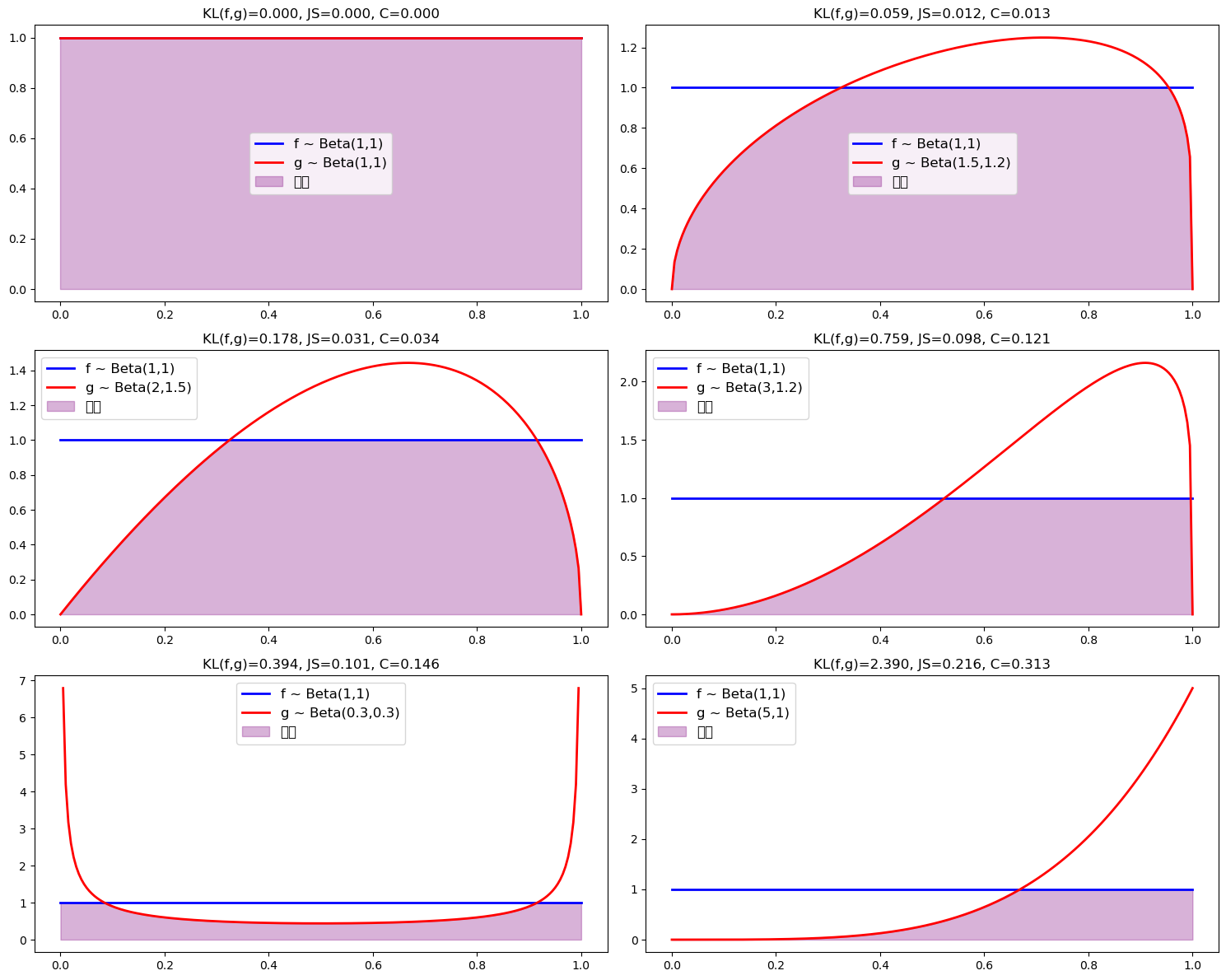
现在我们生成图表来直观展示随着差异度量的增加,重叠程度如何减少。
param_grid = [
((1, 1), (1, 1)),
((1, 1), (1.5, 1.2)),
((1, 1), (2, 1.5)),
((1, 1), (3, 1.2)),
((1, 1), (0.3, 0.3)),
((1, 1), (5, 1))
]
/tmp/ipykernel_9283/3821519245.py:34: UserWarning: Glyph 37325 (\N{CJK UNIFIED IDEOGRAPH-91CD}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_9283/3821519245.py:34: UserWarning: Glyph 21472 (\N{CJK UNIFIED IDEOGRAPH-53E0}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 37325 (\N{CJK UNIFIED IDEOGRAPH-91CD}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 21472 (\N{CJK UNIFIED IDEOGRAPH-53E0}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
21.8. KL散度和最大似然估计#
给定n个观测样本 \(X = \{x_1, x_2, \ldots, x_n\}\),经验分布为
其中 \(\delta(x - x_i)\) 是中心在 \(x_i\) 的狄拉克德尔塔函数:
离散概率测度:对每个观测数据点赋予概率 \(\frac{1}{n}\)
经验期望:\(\langle X \rangle_{p_e} = \frac{1}{n} \sum_{i=1}^n x_i = \bar{\mu}\)
支撑集:仅在观测数据点 \(\{x_1, x_2, \ldots, x_n\}\) 上
从经验分布 \(p_e\) 到参数模型 \(p_\theta(x)\) 的KL散度为:
利用狄拉克德尔塔函数的数学性质,可得
由于参数 \(\theta\) 的对数似然函数为:
因此最大似然选择参数以最小化
因此,MLE等价于最小化从经验分布到统计模型\(p_\theta\)的KL散度。
21.9. 相关讲座#
本讲座介绍了我们将在其他地方遇到的工具。
其他应用散度度量与统计推断之间联系的quantecon讲座包括似然比过程、让弥尔顿·弗里德曼困惑的问题和错误模型。
在研究Lawrence Blume和David Easley的异质信念和金融市场模型的异质信念与金融市场中,统计散度函数也占据核心地位。