57. 最优增长 I:随机最优增长模型#
57.1. 概述#
在本讲中,我们将研究一个简单的单个个体最优增长模型。
该模型是标准的单部门无限期增长模型的一种版本,常见于以下文献:
[Stokey et al., 1989]的第2章
[Ljungqvist and Sargent, 2018]的第3.1节
EDTC的第1章
[Sundaram, 1996]的第12章
它是我们之前讨论过的简单吃蛋糕问题的扩展。
这一拓展包括:
通过生产函数实现的非线性储蓄回报,以及
由于生产冲击导致的随机回报。
尽管增加了这些设定,该模型依然相对简单。
我们将其视为通向更复杂模型的“垫脚石”。
我们将使用动态规划和一系列数值方法来求解该模型。
在这第一节最优增长的课程中,我们采用的方法是价值函数迭代(VFI)。
尽管本讲代码运行较慢,但在后续几讲中,我们会使用多种技术大幅提升执行速度。
让我们从一些基本导入开始:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5) #设置默认图形大小
import numpy as np
from scipy.interpolate import interp1d
from scipy.optimize import minimize_scalar
57.2. 模型#
考虑一个主体在时间 \(t\) 拥有数量为 \(y_t \in \mathbb R_+ := [0, \infty)\) 的消费品。
这些产出可以被消费或投资。
当产出被投资时,它会一比一地转化为资本。
由此产生的资本存量,记为 \(k_{t+1}\),将在下一期投入生产。
生产过程是随机的,因为它还取决于在当期结束时实现的一个冲击 \(\xi_{t+1}\)。
下一期的产出为
其中 \(f \colon \mathbb R_+ \to \mathbb R_+\) 被称为生产函数。
资源约束为
且所有变量都必须为非负数。
57.2.1. 假设和说明#
在接下来的设定中,
序列 \(\{\xi_t\}\) 被假定为独立同分布(IID)。
每个 \(\xi_t\) 的共同分布记为 \(\phi\)。
假设生产函数 \(f\) 是递增且连续的。
资本折旧并未明确表示,但可以被整合到生产函数中。
虽然许多其他随机增长模型的处理方法是将 \(k_t\) 作为状态变量,我们采用 \(y_t\) 作为状态变量。
这样做使我们能够在只有一个状态变量的情况下处理随机增长模型。
在我们的其他讲义中,我们会考虑替代性的状态变量设定以及事件发生时点的不同选择。
57.2.2. 优化问题#
给定初始状态 \(y_0\),个体希望最大化
约束条件为
其中
\(u\) 是有界、连续且严格递增的效用函数,且
\(\beta \in (0, 1)\) 是贴现因子。
在(57.3)中,我们假设资源约束(57.1)是以等式形式成立的——这是合理的,因为 \(u\) 是严格递增的,在最优状态下不会浪费任何产出。
总的来说,个体的目标是选择一个消费路径 \(c_0, c_1, c_2, \ldots\),使其:
非负,
满足资源约束(57.1),
最优,即相对于所有其他可行的消费序列,所选路径使目标函数(57.2)达到最大化,以及
适应性,即行动 \(c_t\) 只依赖于可观察的结果,而不依赖于未来的结果,如 \(\xi_{t+1}\)。
在当前语境下:
\(y_t\) 被称为状态变量——它刻画了每一期开始时的”世界状态”。
\(c_t\) 被称为控制变量——它表示代理人在观察到状态之后所做出的消费决策。
57.2.3. 策略函数方法#
解决该问题的一种方法是寻找最佳的策略函数。
策略函数是一个从过去和现在的可观察变量映射到当前行动的函数。
我们特别关注马尔可夫策略,它是从当前状态 \(y_t\) 映射到当前行动 \(c_t\) 的函数。
对于像这样的动态规划问题(实际上对于任何马尔可夫决策过程),最优策略总是一个马尔可夫策略。
换句话说,当前状态 \(y_t\) 为历史提供了一个充分统计量,使得在做出最优决策时,不需要依赖过去的历史。
这个结论相当直观,其证明可以参考[Stokey et al., 1989](第4.1节)。
在接下来的分析中,我们将专注于寻找最优的马尔可夫策略。
在我们的情况下,马尔可夫策略是一个函数 \(\sigma \colon \mathbb R_+ \to \mathbb R_+\),其含义是:将状态映射到行动,即
我们称 \(\sigma\) 为可行消费策略,当且仅当它满足
换句话说,可行消费策略是满足资源约束的马尔可夫策略。
所有可行消费策略的集合记为 \(\Sigma\)。
每个 \(\sigma \in \Sigma\) 都决定了一个连续状态马尔可夫过程 \(\{y_t\}\) ,其动态为
这就描述了在选定并遵循策略 \(\sigma\) 时,产出的时间路径。
将策略函数代入目标函数,可以得到
这就是在给定初始收入 \(y_0\) 时,永远遵循某一策略 \(\sigma\) 的期望现值。
目标是选择一个策略,使得该数值尽可能大。
下一节将更正式地介绍这些思想。
57.2.4. 最优性#
与给定策略 \(\sigma\) 相关的 映射 \(v_\sigma\) 定义为
其中 \(\{y_t\}\) 由方程 (57.5) 给出,且 \(y_0 = y\)。
换句话说,这是从初始条件 \(y\) 开始遵循策略 \(\sigma\) 的终身价值。
价值函数定义为
价值函数给出了在状态 \(y\) 下,考虑所有可行策略后所能获得的最大价值。
如果一个策略 \(\sigma \in \Sigma\) 在所有 \(y \in \mathbb R_+\) 上都能达到 (57.8) 中的上确界,则称其为最优策略。
57.2.5. 贝尔曼方程#
在我们对效用函数和生产函数的假设下,按照(57.8) 定义的价值函数也满足一个贝尔曼方程。
对于本问题,贝尔曼方程的形式为
这是一个关于 \(v\) 的函数方程。
其中项 \(\int v(f(y - c) z) \phi(dz)\) 可以理解为在以下条件下的下一期期望价值:
使用 \(v\) 来衡量价值
当前状态为 \(y\)
消费选择为 \(c\)
如 EDTC 的定理10.1.11和其他文献所示:
价值函数 \(v^*\) 满足贝尔曼方程
换句话说,当 \(v=v^*\) 时,(57.9) 成立。
直观上来说,从给定状态出发的最大价值可以通过在以下两者之间进行最优权衡获得:
当前行动带来的即时回报,与
由该行动导致的未来状态所带来的贴现期望价值。
贝尔曼方程的重要性在于,它为我们提供了更多关于价值函数的信息。
它同时也是一种计算价值函数的方式,我们将在后续进一步讨论。
57.2.6. 逐期最优策略#
价值函数的主要意义在于:它可以帮助我们计算最优策略。
具体如下:
设 \(v\) 是 \(\mathbb R_+\) 上的一个连续函数。我们称某一策略 \(\sigma \in \Sigma\) 是 \(v\)-逐期最优的,如果对所有 \(y \in \mathbb R_+\),\(\sigma(y)\) 是下式的解:
换句话说,当 \(v\) 被视为价值函数时,如果 \(\sigma \in \Sigma\) 能够最优地权衡当前和未来回报,那么它就是 \(v\)-逐期最优的。
在我们的设定中,有如下关键结果:
一个可行的消费策略是最优的,当且仅当它是\(v^*\)-逐期最优的。
这一结论的直观解释与贝尔曼方程的类似(参见(57.9)之后的说明)。
参见EDTC的定理10.1.11。
因此,一旦我们得到了对 \(v^*\) 的一个良好近似,就可以通过计算相应的逐期最优策略来获得(近似)最优策略。
这样做的优势在于:我们现在解决的是一个低维优化问题,而不是原始的高维动态优化问题。
57.2.7. 贝尔曼算子#
那么,如何计算价值函数呢?
一种方法是使用所谓的贝尔曼算子。
(算子是一类将函数映射到函数的映射。)
贝尔曼算子记为 \(T\),其定义为
换句话说,\(T\) 将函数 \(v\) 映射为新的函数 \(Tv\), 其形式由(57.11)给出。
根据构造,贝尔曼方程(57.9)的解集恰好等于 \(T\) 的不动点集。
例如,如果 \(Tv = v\),那么对于任意 \(y \geq 0\),
这正好说明 \(v\) 是贝尔曼方程的一个解。
由此可知 \(v^*\) 是 \(T\) 的一个不动点。
57.2.8. 理论结果回顾#
可以证明,算子 \(T\) 在连续有界函数空间上是一个压缩映射,其度量是上确界距离:
参见 EDTC的引理10.1.18。
因此,在该空间中,算子 \(T\) 仅有一个不动点,而我们知道该不动点就是价值函数。
由此可知
值函数 \(v^*\) 是有界且连续的。
从任意有界且连续的 \(v\) 开始,通过迭代应用 \(T\) 生成的序列 \(v, Tv, T^2v, \ldots\) 将一致收敛到 \(v^*\)。
这种迭代方法被称为价值函数迭代。
我们还知道:若某一可行消费策略是 \(v^*\)-逐期最优的,那么它就是最优策略。
EDTC 的定理10.1.11)可以证明一个\(v^*\)-逐期最优策略是存在的。
因此,至少存在一个最优策略。
我们的问题现在转变为:如何计算它。
57.2.9. 无界效用#
前面所述结果都假设效用函数是有界的。
但在实际研究中,经济学家往往使用无界效用函数 —— 我们也会如此。
在无界情形下,仍然存在一些最优性理论。
但遗憾的是,这些理论往往具有针对性,而不是适用于大范围应用。
尽管如此,它们的主要结论通常与有界情形下的一致(只需去掉“有界”的限定)。
可以参考,例如EDTC 的第12.2节、[Kamihigashi, 2012] 或 [Martins-da-Rocha and Vailakis, 2010]。
57.3. 计算#
现在让我们来看看如何计算值函数和最优策略。
本讲中的实现将着重于清晰性和灵活性。
这两点都很有帮助,但会牺牲一些运行速度 —— 当你运行代码时就会看到这一点。
在后续讲义在,我们会牺牲一些清晰性和灵活性,通过即时编译(JIT compilation)来加速代码。
本讲所用的算法是拟合价值函数迭代法,它在之前的McCall模型和吃蛋糕问题中已经介绍过。
算法步骤如下:
从一组值 \(\{ v_1, \ldots, v_I \}\) 开始,这些值代表初始函数 \(v\) 在网格点 \(\{ y_1, \ldots, y_I \}\) 上的取值。
基于这些数据点,通过线性插值在状态空间 \(\mathbb R_+\) 上构建函数 \(\hat v\)。
通过重复求解(57.11),获取并记录每个网格点 \(y_i\) 上的值 \(T \hat v(y_i)\)。
除非满足某些停止条件,否则设置 \(\{ v_1, \ldots, v_I \} = \{ T \hat v(y_1), \ldots, T \hat v(y_I) \}\) 并返回步骤2。
57.3.1. 标量最大化#
为了最大化贝尔曼方程(57.9)的右侧,我们将使用SciPy中的minimize_scalar程序。
由于我们需要求最大值而不是最小值,因此会利用以下事实:在区间 \([a, b]\) 上函数 \(g\) 的最大化等价于 \(-g\) 的最小化。
为此,并且为了保持接口的整洁,我们将把 minimize_scalar 封装在一个外部函数中,如下所示:
def maximize(g, a, b, args):
"""
在区间 [a, b] 上最大化函数 g。
我们利用了在任何区间上 g 的最大值点也是 -g 的最小值点这一事实。
元组 args 收集了传递给 g 的任何额外参数。
返回最大值和最大值点。
"""
objective = lambda x: -g(x, *args)
result = minimize_scalar(objective, bounds=(a, b), method='bounded')
maximizer, maximum = result.x, -result.fun
return maximizer, maximum
57.3.2. 最优增长模型#
我们暂且假设 \(\phi\) 是 \(\xi := \exp(\mu + s \zeta)\) 的分布,其中
\(\zeta\) 是标准正态分布随机变量,
\(\mu\) 是冲击的位置参数,
\(s\) 是冲击的尺度参数。
我们将这些和最优增长模型的其他基本要素存储在一个类中。
下面定义的类结合了参数,以及一个用于实现贝尔曼方程(57.9)右侧的方法。
class OptimalGrowthModel:
def __init__(self,
u, # 效用函数
f, # 生产函数
β=0.96, # 贴现因子
μ=0, # 冲击位置参数
s=0.1, # 冲击尺度参数
grid_max=4,
grid_size=120,
shock_size=250,
seed=1234):
self.u, self.f, self.β, self.μ, self.s = u, f, β, μ, s
# 设置网格
self.grid = np.linspace(1e-4, grid_max, grid_size)
# 存储冲击(设定随机种子,使结果可重现)
np.random.seed(seed)
self.shocks = np.exp(μ + s * np.random.randn(shock_size))
def state_action_value(self, c, y, v_array):
"""
贝尔曼方程的右侧。
"""
u, f, β, shocks = self.u, self.f, self.β, self.shocks
v = interp1d(self.grid, v_array)
return u(c) + β * np.mean(v(f(y - c) * shocks))
在倒数第二行中,我们使用线性插值。
在最后一行中,(57.11)中的期望值通过蒙特卡洛法计算,近似为:
其中 \(\{\xi_i\}_{i=1}^n\) 是从\(\phi\) 中独立同分布抽取的样本。
蒙特卡洛并不总是计算积分最有效的数值方法,但在当前设定下,它确实具有一些理论优势。
(例如,它保持了贝尔曼算子的压缩映射性质 – 参见[Pál and Stachurski, 2013]。)
57.3.3. 贝尔曼算子#
下面的函数实现了贝尔曼算子。
(我们本可以将其作为OptimalGrowthModel类的一个方法,但对于这种数值计算工作,我们更倾向于使用小型类而不是大而全的单一类。)
def T(v, og):
"""
贝尔曼算子。
更新值函数的猜测值,并同时计算v-逐期最优策略。
* og是OptimalGrowthModel的一个实例
* v是表示价值函数猜测的数组
"""
v_new = np.empty_like(v)
v_greedy = np.empty_like(v)
for i in range(len(grid)):
y = grid[i]
# 在状态y下最大化贝尔曼方程右侧
c_star, v_max = maximize(og.state_action_value, 1e-10, y, (y, v))
v_new[i] = v_max
v_greedy[i] = c_star
return v_greedy, v_new
57.3.4. 一个示例#
假设现在
在这一特定问题中,可以得到一个精确的解析解(参见[Ljungqvist and Sargent, 2018]第3.1.2节),其形式为
最优消费策略为
有这些封闭形式解的价值在于:它们使我们能够检验代码在这一具体情形下是否正确。
在Python中,上述函数可以表示为:
def v_star(y, α, β, μ):
"""
真实价值函数
"""
c1 = np.log(1 - α * β) / (1 - β)
c2 = (μ + α * np.log(α * β)) / (1 - α)
c3 = 1 / (1 - β)
c4 = 1 / (1 - α * β)
return c1 + c2 * (c3 - c4) + c4 * np.log(y)
def σ_star(y, α, β):
"""
真实最优策略
"""
return (1 - α * β) * y
接下来让我们用上述基本要素创建一个模型实例,并将其赋值给变量og。
α = 0.4
def fcd(k):
return k**α
og = OptimalGrowthModel(u=np.log, f=fcd)
现在让我们看看当我们将贝尔曼算子应用于这种情况下的精确解 \(v^*\) 时会发生什么。
理论上,由于 \(v^*\) 是一个不动点,得到的函数应该仍然是 \(v^*\)。
在实践中,我们预计会有一些小的数值误差。
grid = og.grid
v_init = v_star(grid, α, og.β, og.μ) # 从解开始
v_greedy, v = T(v_init, og) # 应用一次T
fig, ax = plt.subplots()
ax.set_ylim(-35, -24)
ax.plot(grid, v, lw=2, alpha=0.6, label='$Tv^*$')
ax.plot(grid, v_init, lw=2, alpha=0.6, label='$v^*$')
ax.legend()
plt.show()

这两个函数本质上没有区别,所以我们开始得很顺利。
现在让我们看看从任意初始条件开始,如何用贝尔曼算子进行迭代。
我们随意地将初始条件设定为 \(v(y) = 5 \ln (y)\)。
v = 5 * np.log(grid) # 初始条件
n = 35
fig, ax = plt.subplots()
ax.plot(grid, v, color=plt.cm.jet(0),
lw=2, alpha=0.6, label='初始条件')
for i in range(n):
v_greedy, v = T(v, og) # 应用贝尔曼算子
ax.plot(grid, v, color=plt.cm.jet(i / n), lw=2, alpha=0.6)
ax.plot(grid, v_star(grid, α, og.β, og.μ), 'k-', lw=2,
alpha=0.8, label='真实的价值函数')
ax.legend()
ax.set(ylim=(-40, 10), xlim=(np.min(grid), np.max(grid)))
plt.show()
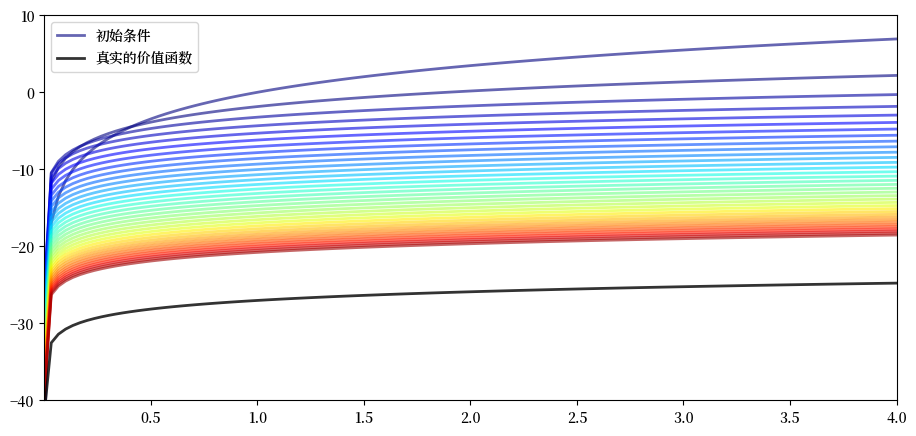
图中显示了
由拟合值迭代算法生成的前36个函数,颜色越热表示迭代次数越高
用黑色线条绘制真实的价值函数 \(v^*\)
迭代序列逐渐收敛至 \(v^*\)。
我们显然正在接近目标。
57.3.5. 迭代至收敛#
我们可以编写一个函数,使其迭代直到差异小于特定的容差水平。
def solve_model(og,
tol=1e-4,
max_iter=1000,
verbose=True,
print_skip=25):
"""
通过迭代贝尔曼算子求解
"""
# 设置迭代循环
v = og.u(og.grid) # 初始条件
i = 0
error = tol + 1
while i < max_iter and error > tol:
v_greedy, v_new = T(v, og)
error = np.max(np.abs(v - v_new))
i += 1
if verbose and i % print_skip == 0:
print(f"第 {i} 次迭代的误差为 {error}。")
v = v_new
if error > tol:
print("未能收敛!")
elif verbose:
print(f"\n在 {i} 次迭代后收敛。")
return v_greedy, v_new
让我们使用这个函数在默认设置下计算一个近似解。
v_greedy, v_solution = solve_model(og)
第 25 次迭代的误差为 0.40975776844490497。
第 50 次迭代的误差为 0.1476753540823772。
第 75 次迭代的误差为 0.05322171277213883。
第 100 次迭代的误差为 0.019180930548646558。
第 125 次迭代的误差为 0.006912744396029069。
第 150 次迭代的误差为 0.002491330384817303。
第 175 次迭代的误差为 0.000897867291303811。
第 200 次迭代的误差为 0.00032358842396718046。
第 225 次迭代的误差为 0.00011662020561331587。
在 229 次迭代后收敛。
现在我们通过将结果与真实值作图比较来检验其准确性:
fig, ax = plt.subplots()
ax.plot(grid, v_solution, lw=2, alpha=0.6,
label='近似的价值函数')
ax.plot(grid, v_star(grid, α, og.β, og.μ), lw=2,
alpha=0.6, label='真实的价值函数')
ax.legend()
ax.set_ylim(-35, -24)
plt.show()
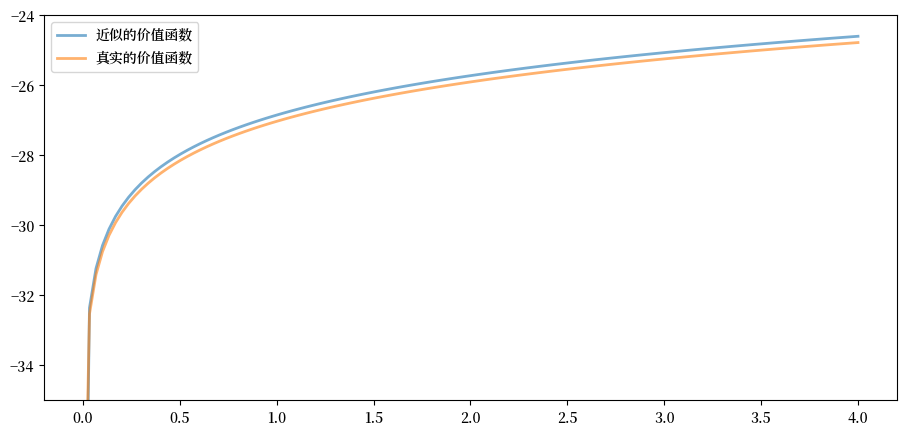
图表显示我们的结果非常准确。
57.3.6. 策略函数#
上面计算的策略v_greedy对应于一个近似最优策略。
下图将其与精确解进行比较,如上所述,精确解为 \(\sigma(y) = (1 - \alpha \beta) y\)
fig, ax = plt.subplots()
ax.plot(grid, v_greedy, lw=2,
alpha=0.6, label='近似的策略函数')
ax.plot(grid, σ_star(grid, α, og.β), '--',
lw=2, alpha=0.6, label='真实的策略函数')
ax.legend()
plt.show()

图表显示我们在这个例子中很好地近似了真实的策略。
57.4. 练习#
练习 57.1
在这类模型中,效用函数的常见选择是CRRA形式
保持其他默认设置(包括柯布-道格拉斯生产函数),用这个效用函数求解最优增长模型。
设定 \(\gamma = 1.5\),计算并绘制最优策略的估计值。
记录这个函数运行所需的时间,以便与下一讲中开发的更快代码进行比较。
解答 练习 57.1
首先,设置模型。
γ = 1.5 # 偏好参数
def u_crra(c):
return (c**(1 - γ) - 1) / (1 - γ)
og = OptimalGrowthModel(u=u_crra, f=fcd)
现在让我们运行它,并计时。
%%time
v_greedy, v_solution = solve_model(og)
第 25 次迭代的误差为 0.5528151810417512。
第 50 次迭代的误差为 0.19923228425590978。
第 75 次迭代的误差为 0.07180266113800826。
第 100 次迭代的误差为 0.025877443335843964。
第 125 次迭代的误差为 0.009326145618970827。
第 150 次迭代的误差为 0.003361112262005861。
第 175 次迭代的误差为 0.0012113338243295857。
第 200 次迭代的误差为 0.0004365607333056687。
第 225 次迭代的误差为 0.00015733505506432266。
在 237 次迭代后收敛。
CPU times: user 20.6 s, sys: 60.2 ms, total: 20.6 s
Wall time: 20.5 s
让我们绘制策略函数,看看它的样子:
fig, ax = plt.subplots()
ax.plot(grid, v_greedy, lw=2,
alpha=0.6, label='近似的最优策略')
ax.legend()
plt.show()

练习 57.2
计时从初始条件 \(v(y) = u(y)\) 开始,使用贝尔曼算子迭代20次所需的时间。
使用前一个练习中的模型设置。
(和之前一样,我们会将这个数字与下一讲中更快的代码进行比较。)
解答 练习 57.2
让我们设置:
og = OptimalGrowthModel(u=u_crra, f=fcd)
v = og.u(og.grid)
这是计时结果:
%%time
for i in range(20):
v_greedy, v_new = T(v, og)
v = v_new
CPU times: user 1.75 s, sys: 15 ms, total: 1.77 s
Wall time: 1.75 s