28. 可交换性和贝叶斯更新#
28.1. 概述#
本讲座研究通过贝叶斯定律进行的学习。
我们涉及由Bruno DeFinetti [de Finetti, 1937]发明的贝叶斯统计推断的基础。
DeFinetti的工作对经济学家的相关性在David Kreps的[Kreps, 1988]第11章中得到了有力的阐述。
我们在本讲座中研究的一个例子是这个讲座的一个关键组成部分,它扩充了
classic McCall的经典工作搜索模型[McCall, 1970]通过为失业劳动者提供一个统计推断问题来展示。
我们创建图表来说明似然比在贝叶斯定律中所起的作用。
我们将使用这些图表来深入理解本讲座中关于增强型McCall工作搜索模型中学习机制的运作原理。
除此之外,本讲座还讨论了随机变量序列的统计概念之间的联系,这些序列是:
独立同分布的
可交换的(也称为条件独立同分布)
理解这些概念对于领会贝叶斯更新的工作原理至关重要。
你可以在这里阅读关于可交换性的内容。
因为可交换性的另一个术语是条件独立性,我们想要回答基于什么条件这个问题。
我们还要解释为什么独立性假设阻碍了学习,而条件独立性假设使学习成为可能。
在下文中,我们经常使用
\(W\) 表示一个随机变量
\(w\) 表示随机变量 \(W\) 的一个特定实现值
让我们从一些导入开始:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5) #设置默认图形大小
from numba import jit, vectorize
from math import gamma
import scipy.optimize as op
from scipy.integrate import quad
import numpy as np
28.2. 独立同分布#
我们首先来看看独立同分布序列这个概念。
独立同分布序列通常简写为IID。
这个概念包含两个方面:
独立性
同分布
如果一个序列\(W_0, W_1, \ldots\)的联合概率密度等于序列各个组成部分的密度的乘积,则称该序列是独立分布的。
如果序列\(W_0, W_1, \ldots\)是独立同分布的(IID),那么除了独立性之外,对于所有\(t =0, 1, \ldots\),\(W_t\)的边际密度都相同。
例如,设\(p(W_0, W_1, \ldots)\)为序列的联合密度,\(p(W_t)\)为特定\(W_t\)的边际密度(对所有\(t =0, 1, \ldots\)成立)。
那么,如果序列\(W_0, W_1, \ldots\)是IID的,则其联合密度满足:
因此联合密度是一系列相同边际密度的乘积。
28.2.1. IID意味着过去的观测不能告诉我们任何关于未来观测的信息#
如果一个随机变量序列是IID的,过去的信息对未来的实现没有任何指示作用。
因此,从过去无法学到任何关于未来的信息。
为了理解这些陈述,让我们考虑一个不一定是IID的随机变量序列\(\{W_t\}_{t=0}^T\)的联合分布
根据概率定律,我们总可以将这样的联合密度分解为条件密度的乘积:
一般来说,
这表明左边的条件密度不等于右边的边际密度。
但在特殊的独立同分布(IID)情况下,
且部分历史\(W_{t-1}, \ldots, W_0\)不包含关于\(W_t\)概率的任何信息。
因此在IID情况下,从过去的随机变量中无法学习到关于未来随机变量密度的任何信息。
但当序列不是IID时,我们可以从过去随机变量的观测中学习到关于未来的一些信息。
接下来我们来看一个序列不是IID的一般情况的例子。
请注意从过去可以学到什么以及何时可以学到。
28.3. 过去观测具有信息性的情况#
设\(\{W_t\}_{t=0}^\infty\)是一个非负标量随机变量序列,其联合概率分布按如下方式构建。
有两个不同的累积分布函数\(F\)和\(G\),它们分别具有密度函数\(f\)和\(g\),用于描述一个非负标量随机变量\(W\)。
在时间开始之前,比如在时间\(t=-1\)时,”自然”一次性地选择了要么\(f\)要么\(g\)。
此后在每个时间\(t \geq 0\),自然从所选的分布中抽取一个随机变量\(W_t\)。
因此,数据被永久地生成为从要么\(F\)要么\(G\)中独立同分布(IID)的抽样。
我们可以说客观上,即在自然选择了\(F\)或\(G\)之后,数据是从\(F\)中生成的概率要么是\(0\)要么是\(1\)。
现在我们在这个设定中引入一个部分知情的决策者,他知道:
\(F\)和\(G\)两者,但是
不知道自然在\(t=-1\)时一次性选择的是\(F\)还是\(G\)
所以我们的决策者不知道自然选择了这两个分布中的哪一个。
决策者用主观概率\(\tilde \pi\)来描述他的不确定性,并假设自然以概率\(\tilde \pi \in (0,1)\)选择了\(F\),以概率\(1 - \tilde \pi\)选择了\(G\)。
因此,我们假设决策者:
知道\(F\)和\(G\)这两个分布
不知道自然选择了这两个分布中的哪一个
通过表现得好像或认为自然以概率\(\tilde \pi \in (0,1)\)选择了分布\(F\),以概率\(1 - \tilde \pi\)选择了分布\(G\)来表达他的不确定性
在时间\(t \geq 0\)时知道部分历史\(w_t, w_{t-1}, \ldots, w_0\)
为了继续,我们需要了解决策者对部分历史的联合分布的信念。
接下来我们将讨论这一点,并在此过程中描述可交换性的概念。
28.4. IID和可交换之间的关系#
在自然选择\(F\)的条件下,序列\(W_0, W_1, \ldots\)的联合密度是
在自然选择\(G\)的条件下,序列\(W_0, W_1, \ldots\)的联合密度为
因此,在自然选择\(F\)的条件下,序列\(W_0, W_1, \ldots\)是独立同分布的。
此外,在自然选择\(G\)的条件下,序列\(W_0, W_1, \ldots\)也是独立同分布的。
但是部分历史的无条件分布又如何呢?
\(W_0, W_1, \ldots\)的无条件分布显然是
在无条件分布\(h(W_0, W_1, \ldots )\)下,序列\(W_0, W_1, \ldots\)不是独立同分布的。
要验证这个说法,只需注意到,例如
因此,条件分布
这意味着随机变量 \(W_0\) 包含了关于随机变量 \(W_1\) 的信息。
所以过去确实包含了可以用来了解未来的信息。
但是什么信息?如何了解?
28.5. 可交换性#
虽然序列 \(W_0, W_1, \ldots\) 不是独立同分布的,但可以验证它是可交换的,这意味着”重新排序”的联合分布 \(h(W_0, W_1)\) 和 \(h(W_1, W_0)\) 满足
等等。
更一般地说,如果一个随机变量序列的联合概率分布在有限个随机变量的位置发生改变时保持不变,则称该序列是可交换的。
方程 (28.1) 表示了一个可交换的联合密度函数,它是由两个独立同分布(IID)的随机变量序列的联合密度函数构成的混合。
对贝叶斯统计学家来说,混合参数 \(\tilde \pi \in (0,1)\) 具有特殊的解释,即自然选择概率分布 \(F\) 的主观先验概率。
DeFinetti [de Finetti, 1937] 建立了一个相关的可交换过程表示,该过程是通过混合参数为 \(\theta \in (0,1)\) 的独立同分布伯努利随机变量序列,以及混合概率密度 \(\pi(\theta)\) 得到的。贝叶斯统计学家会将这个混合概率密度解释为未知伯努利参数 \(\theta\) 的先验分布。
28.6. 贝叶斯定律#
我们在上面注意到,在我们的示例模型中,从可交换但非独立同分布过程的历史数据中可以学到关于未来的一些信息。
但是我们如何学习?
以及学习什么?
关于什么问题的答案是 \(\tilde \pi\)。
如何问题的答案是使用贝叶斯定律。
另一种表述使用贝叶斯定律的方式是说从一个(主观的)联合分布中,计算适当的条件分布。
让我们在这个背景下深入了解贝叶斯定律。
令 \(q\) 表示自然实际从中抽取 \(w\) 的分布,并令
这里我们将 \(\pi\) 视为决策者的主观概率(也称为个人概率)。
假设在 \(t \geq 0\) 时,决策者已观察到历史序列 \(w^t \equiv [w_t, w_{t-1}, \ldots, w_0]\)。
我们令
其中我们采用如下约定
在给定 \(w^t\) 条件下,\(w_{t+1}\) 的分布为
更新 \(\pi_{t+1}\) 的贝叶斯规则为
等式(28.2)源自贝叶斯法则,该法则告诉我们
其中
28.7. 关于贝叶斯更新的更多细节#
让我们仔细观察并重新整理等式(28.2)中表示的贝叶斯法则,目的是理解后验概率\(\pi_{t+1}\)如何受到先验概率\(\pi_t\)和似然比的影响
我们可以方便地将更新规则(28.2)重写为
这意味着
注意似然比和先验是如何相互作用,以决定观测值\(w_{t+1}\)是导致决策者增加还是减少他/她对分布\(F\)的主观概率。
当似然比\(l(w_{t+1})\)大于1时,观测值\(w_{t+1}\)会将分布\(F\)的概率\(\pi\)向上推动,当似然比\(l(w_{t+1})\)小于1时,观测值\(w_{t+1}\)会将\(\pi\)向下推动。
表达式(28.3)是我们将用来显示由以下因素引起的\(\{\pi_t\}_{t=0}^\infty\)动态的一些图表的基础
贝叶斯定律。
我们将绘制 \(l\left(w\right)\) 来帮助我们理解学习过程是如何进行的——即,如何通过贝叶斯更新来更新自然选择分布 \(f\) 的概率 \(\pi\)。
为了创建完成工作所需的 Python 基础设施,我们构建一个包装函数,该函数可以根据 \(f\) 和 \(g\) 的参数显示信息丰富的图表。
@vectorize
def p(x, a, b):
"通用贝塔分布函数。"
r = gamma(a + b) / (gamma(a) * gamma(b))
return r * x ** (a-1) * (1 - x) ** (b-1)
def learning_example(F_a=1, F_b=1, G_a=3, G_b=1.2):
"""
一个包装函数,用于显示信念π的更新规则,
给定指定F和G分布的参数。
"""
f = jit(lambda x: p(x, F_a, F_b))
g = jit(lambda x: p(x, G_a, G_b))
# l(w) = f(w) / g(w)
l = lambda w: f(w) / g(w)
# 用于求解 l(w) = 1 的目标函数
obj = lambda w: l(w) - 1
x_grid = np.linspace(0, 1, 100)
π_grid = np.linspace(1e-3, 1-1e-3, 100)
w_max = 1
w_grid = np.linspace(1e-12, w_max-1e-12, 100)
# 贝塔分布的众数
# 用它将w分成两个区间进行根查找
G_mode = (G_a - 1) / (G_a + G_b - 2)
roots = np.empty(2)
roots[0] = op.root_scalar(obj, bracket=[1e-10, G_mode]).root
roots[1] = op.root_scalar(obj, bracket=[G_mode, 1-1e-10]).root
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(18, 5))
ax1.plot(l(w_grid), w_grid, label='$l$', lw=2)
ax1.vlines(1., 0., 1., linestyle="--")
ax1.hlines(roots, 0., 2., linestyle="--")
ax1.set_xlim([0., 2.])
ax1.legend(loc=4)
ax1.set(xlabel='$l(w)=f(w)/g(w)$', ylabel='$w$')
ax2.plot(f(x_grid), x_grid, label='$f$', lw=2)
ax2.plot(g(x_grid), x_grid, label='$g$', lw=2)
ax2.vlines(1., 0., 1., linestyle="--")
ax2.hlines(roots, 0., 2., linestyle="--")
ax2.legend(loc=4)
ax2.set(xlabel='$f(w), g(w)$', ylabel='$w$')
area1 = quad(f, 0, roots[0])[0]
area2 = quad(g, roots[0], roots[1])[0]
area3 = quad(f, roots[1], 1)[0]
ax2.text((f(0) + f(roots[0])) / 4, roots[0] / 2, f"{area1: .3g}")
ax2.fill_between([0, 1], 0, roots[0], color='blue', alpha=0.15)
ax2.text(np.mean(g(roots)) / 2, np.mean(roots), f"{area2: .3g}")
w_roots = np.linspace(roots[0], roots[1], 20)
ax2.fill_betweenx(w_roots, 0, g(w_roots), color='orange', alpha=0.15)
ax2.text((f(roots[1]) + f(1)) / 4, (roots[1] + 1) / 2, f"{area3: .3g}")
ax2.fill_between([0, 1], roots[1], 1, color='blue', alpha=0.15)
W = np.arange(0.01, 0.99, 0.08)
Π = np.arange(0.01, 0.99, 0.08)
ΔW = np.zeros((len(W), len(Π)))
ΔΠ = np.empty((len(W), len(Π)))
for i, w in enumerate(W):
for j, π in enumerate(Π):
lw = l(w)
ΔΠ[i, j] = π * (lw / (π * lw + 1 - π) - 1)
q = ax3.quiver(Π, W, ΔΠ, ΔW, scale=2, color='r', alpha=0.8)
ax3.fill_between(π_grid, 0, roots[0], color='blue', alpha=0.15)
ax3.fill_between(π_grid, roots[0], roots[1], color='green', alpha=0.15)
ax3.fill_between(π_grid, roots[1], w_max, color='blue', alpha=0.15)
ax3.hlines(roots, 0., 1., linestyle="--")
ax3.set(xlabel='$\pi$', ylabel='$w$')
ax3.grid()
plt.show()
现在我们将创建一组图表来说明贝叶斯定律所引发的动态变化。
我们将从Python函数的各种对象的默认值开始,然后在后续示例中对其进行修改。
learning_example()
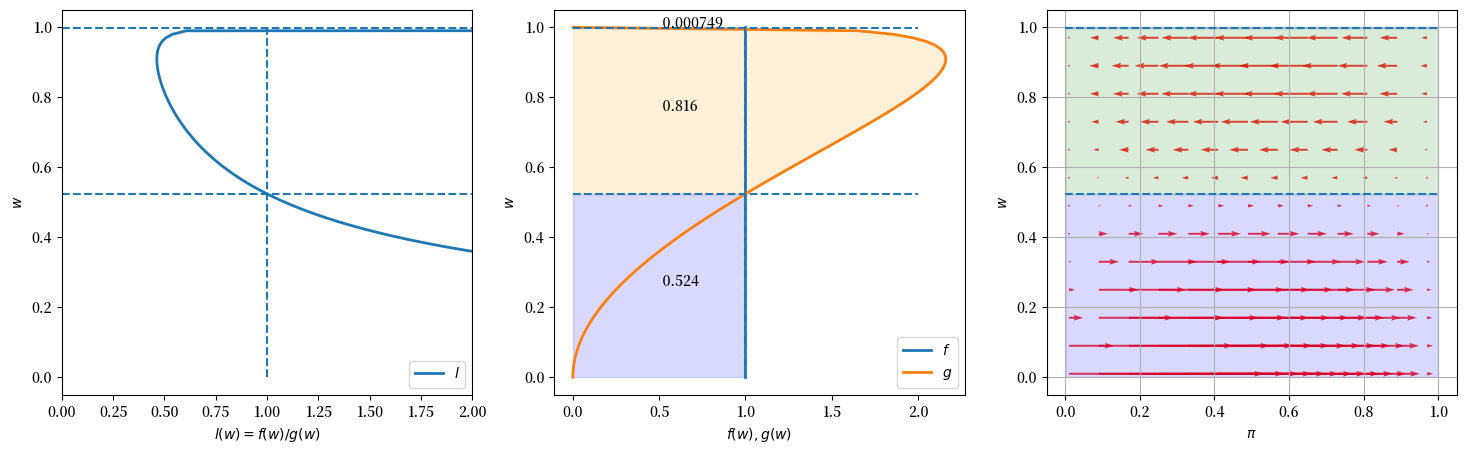
请看上面的三个图表,这些图表是针对以下情况创建的:\(f\) 是在 \([0,1]\) 上的均匀分布(即参数为 \(F_a=1, F_b=1\) 的Beta分布),而 \(g\) 是具有默认参数值 \(G_a=3, G_b=1.2\) 的Beta分布。
左侧的图表将似然比 \(l(w)\) 作为横坐标轴,将 \(w\) 作为纵坐标轴进行绘制。
中间的图表将 \(f(w)\) 和 \(g(w)\) 对 \(w\) 进行绘制,其中水平虚线显示了似然比等于1时的 \(w\) 值。
右侧的图表用向右的箭头表示贝叶斯定律使 \(\pi\) 增加的情况,用向左的箭头表示贝叶斯定律使 \(\pi\) 减少的情况。
箭头的长度表示贝叶斯定律驱使 \(\pi\) 改变的力的大小。
这些长度取决于两个因素:横坐标轴上的先验概率 \(\pi\),以及以当前 \(w\) 值形式出现的证据(在纵坐标轴上)。
中间图中彩色区域的分数分别表示在分布\(F\)和\(G\)下,\(w\)的实现值落入能将信念\(\pi\)向正确方向更新的区间的概率(即当\(G\)为真实分布时向\(0\)更新,当\(F\)为真实分布时向\(1\)更新)。
例如,在上述例子中,在真实分布\(F\)下,如果\(w\)落入区间\([0.524, 0.999]\),\(\pi\)将向\(0\)更新,这在\(F\)下发生的概率是\(1 - .524 = .476\)。
但如果\(G\)是真实分布,这种情况发生的概率将是\(0.816\)。
橙色区域中的分数\(0.816\)是\(g(w)\)在这个区间上的积分。
接下来我们使用代码为我们模型的另一个实例创建图形。
我们保持\(F\)与前一个实例相同,即均匀分布,但现在假设\(G\)是一个参数为\(G_a=2, G_b=1.6\)的Beta分布。
learning_example(G_a=2, G_b=1.6)
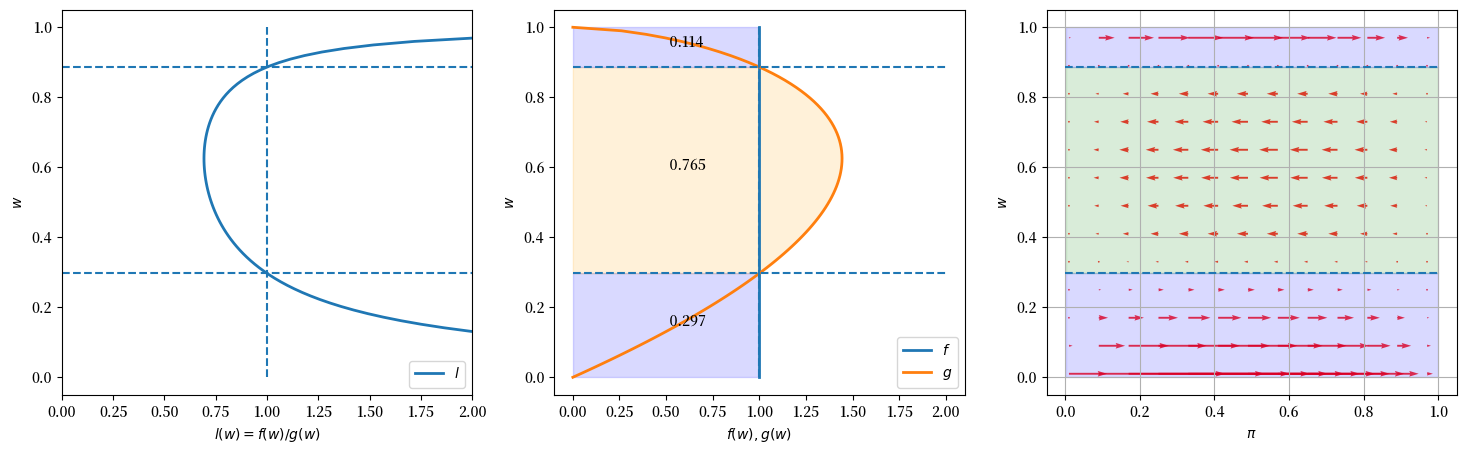
注意观察似然比、中间图表以及箭头与我们之前例子的对比。
28.8. 附录#
28.8.1. \(\pi_t\) 的样本路径#
现在我们将通过绘制 \(\pi_t\) 的多个样本路径来进行一些有趣的探索,这些路径基于两种可能的自然分布选择假设:
自然永久从 \(F\) 分布中抽取
自然永久从 \(G\) 分布中抽取
结果取决于似然比过程的一个特殊性质,这在本讲座中有详细讨论。
让我们编写一些Python代码。
def function_factory(F_a=1, F_b=1, G_a=3, G_b=1.2):
# 定义 f 和 g
f = jit(lambda x: p(x, F_a, F_b))
g = jit(lambda x: p(x, G_a, G_b))
@jit
def update(a, b, π):
"通过从参数为a和b的beta分布中抽样来更新π"
# 抽样
w = np.random.beta(a, b)
# 更新信念
π = 1 / (1 + ((1 - π) * g(w)) / (π * f(w)))
return π
@jit
def simulate_path(a, b, T=50):
"模拟长度为T的信念π路径"
π = np.empty(T+1)
# 初始条件
π[0] = 0.5
for t in range(1, T+1):
π[t] = update(a, b, π[t-1])
return π
def simulate(a=1, b=1, T=50, N=200, display=True):
"模拟N条长度为T的信念π路径"
π_paths = np.empty((N, T+1))
if display:
fig = plt.figure()
for i in range(N):
π_paths[i] = simulate_path(a=a, b=b, T=T)
if display:
plt.plot(range(T+1), π_paths[i], color='b', lw=0.8, alpha=0.5)
if display:
plt.show()
return π_paths
return simulate
simulate = function_factory()
我们首先生成 \(N\) 条模拟的 \(\{\pi_t\}\) 路径,每条路径包含 \(T\) 个时期,其中序列是真实的从分布 \(F\) 中独立同分布抽取的。我们设定初始先验 \(\pi_{-1} = .5\)。
T = 50
# 当自然选择F时
π_paths_F = simulate(a=1, b=1, T=T, N=1000)
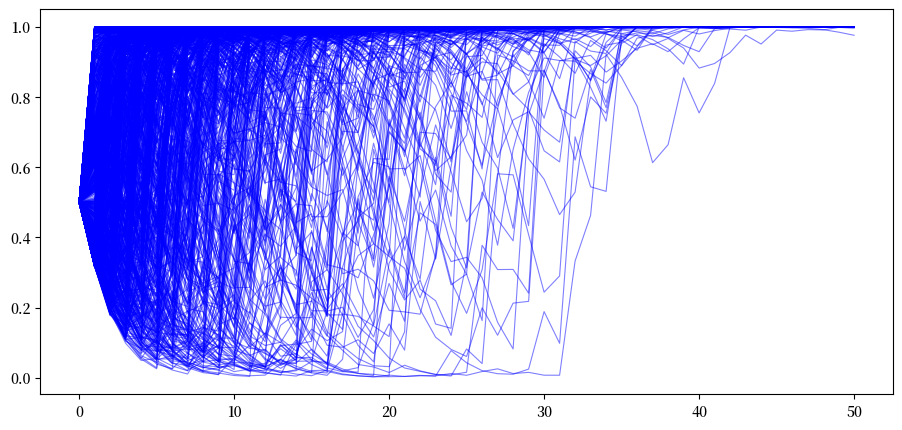
在上述例子中,对于大多数路径 \(\pi_t \rightarrow 1\)。
因此,贝叶斯定律显然最终能够在我们的大多数路径中发现真相。
接下来,当序列确实是来自 \(G\) 的独立同分布抽样时,我们生成 \(T\) 期的路径。同样,我们设定初始先验 \(\pi_{-1} = .5\)。
# when nature selects G
π_paths_G = simulate(a=3, b=1.2, T=T, N=1000)
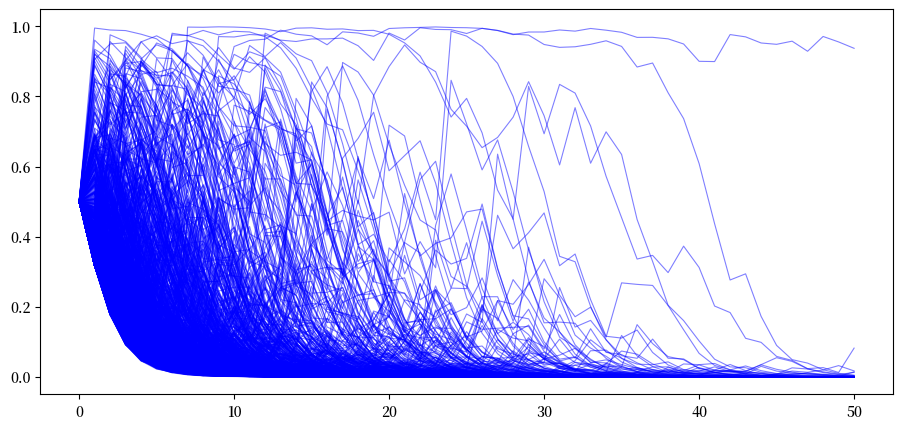
在上图中我们观察到现在大多数路径 \(\pi_t \rightarrow 0\)。
28.8.2. 收敛速率#
我们研究当自然生成的数据是来自 \(F\) 的独立同分布抽样时 \(\pi_t\) 向 \(1\) 的收敛速率,以及当自然生成的数据是来自 \(G\) 的独立同分布抽样时 \(\pi_t\) 向 \(0\) 的收敛速率。
我们通过对 \(\{\pi_t\}_{t=0}^T\) 的模拟路径进行平均来实现这一点。
使用 \(N\) 条模拟的 \(\pi_t\) 路径,当数据是从 \(F\) 中抽样生成时,我们在每个 \(t\) 时刻计算 \(1 - \sum_{i=1}^{N}\pi_{i,t}\),当数据是从 \(G\) 中抽样生成时,我们计算 \(\sum_{i=1}^{N}\pi_{i,t}\)。
plt.plot(range(T+1), 1 - np.mean(π_paths_F, 0), label='F生成')
plt.plot(range(T+1), np.mean(π_paths_G, 0), label='G生成')
plt.legend()
plt.title("收敛");
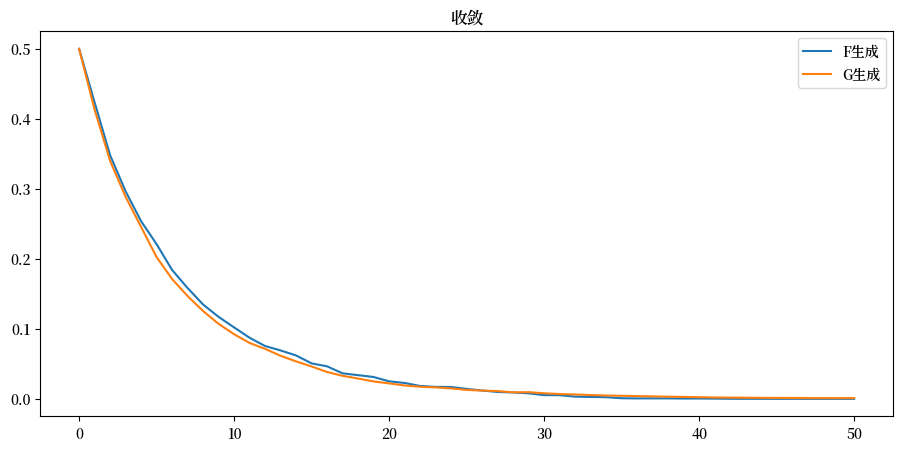
从上图可以看出,收敛速率似乎不依赖于是 \(F\) 还是 \(G\) 生成数据。
28.8.3. \(\pi_t\) 的集合动态图#
通过对相关概率分布进行积分计算 \(\frac{\pi_{t+1}}{\pi_{t}}\) 的条件期望作为 \(\pi_t\) 的函数,可以获得关于 \(\{\pi_t\}\) 动态的更多见解:
其中 \(a =f,g\)。
以下代码近似计算上述积分:
def expected_ratio(F_a=1, F_b=1, G_a=3, G_b=1.2):
# define f and g
f = jit(lambda x: p(x, F_a, F_b))
g = jit(lambda x: p(x, G_a, G_b))
l = lambda w: f(w) / g(w)
integrand_f = lambda w, π: f(w) * l(w) / (π * l(w) + 1 - π)
integrand_g = lambda w, π: g(w) * l(w) / (π * l(w) + 1 - π)
π_grid = np.linspace(0.02, 0.98, 100)
expected_rario = np.empty(len(π_grid))
for q, inte in zip(["f", "g"], [integrand_f, integrand_g]):
for i, π in enumerate(π_grid):
expected_rario[i]= quad(inte, 0, 1, args=(π,))[0]
plt.plot(π_grid, expected_rario, label=f"{q} generates")
plt.hlines(1, 0, 1, linestyle="--")
plt.xlabel("$π_t$")
plt.ylabel("$E[\pi_{t+1}/\pi_t]$")
plt.legend()
plt.show()
首先,考虑 \(F_a=F_b=1\) 且 \(G_a=3, G_b=1.2\) 的情况。
expected_ratio()
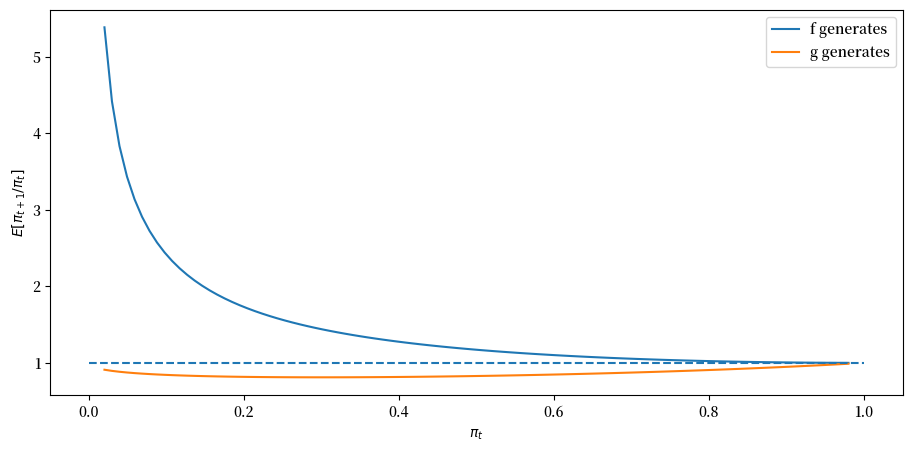
上图显示,当数据由 \(F\) 生成时,\(\pi_t\) 平均总是向北移动,而当数据由 \(G\) 生成时,\(\pi_t\) 向南移动。
接下来,我们将看一个退化情况,其中 \(f\) 和 \(g\) 是相同的贝塔分布,且 \(F_a=G_a=3, F_b=G_b=1.2\)。
从某种意义上说,这里没有什么可学习的。
expected_ratio(F_a=3, F_b=1.2)
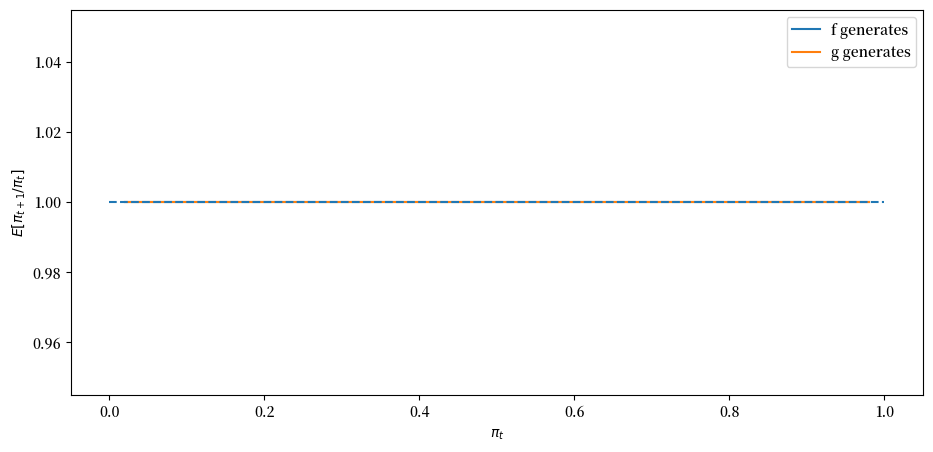
上图表明 \(\pi_t\) 是惰性的,保持在其初始值。
最后,让我们看一个 \(f\) 和 \(g\) 既不是非常不同也不完全相同的情况,特别是当 \(F_a=2, F_b=1\) 且 \(G_a=3, G_b=1.2\) 时。
expected_ratio(F_a=2, F_b=1, G_a=3, G_b=1.2)
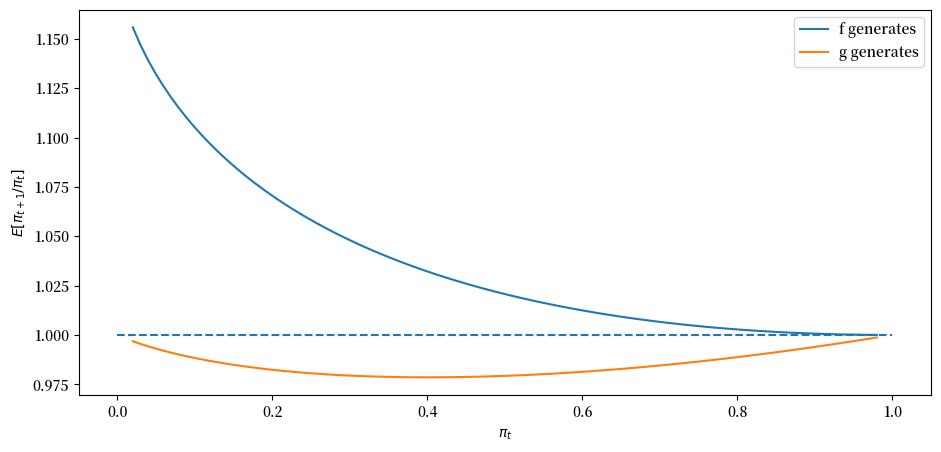
28.9. 后续内容#
我们将在以下讲座中应用并深入探讨本讲座中提出的一些想法: