56. 吃蛋糕问题 II:数值方法#
56.1. 概述#
在本讲中,我们将继续研究吃蛋糕问题。
本讲的目标是使用数值方法来求解该问题。
这似乎没有必要,因为我们已经通过解析方法得到了最优策略。
然而,吃蛋糕问题如果不加修改就过于简单,几乎没有实际用途。一旦我们对问题进行修改,求解就必须依赖数值方法。
因此,现在引入数值方法并在这个简单问题上进行测试是有意义的。
由于我们已经知道解析解,这将使我们能够评估不同数值方法的精确度。
我们将使用以下导入:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
import numpy as np
from scipy.optimize import minimize_scalar, bisect
56.2. 回顾模型#
在开始之前,你可能想要回顾一下细节。
特别要回顾的是贝尔曼方程:
其中 \(u\) 是CRRA效用函数。
价值函数和最优策略的解析解如下所示。
def c_star(x, β, γ):
return (1 - β ** (1/γ)) * x
def v_star(x, β, γ):
return (1 - β**(1 / γ))**(-γ) * (x**(1-γ) / (1-γ))
我们的第一个目标是用数值方法再现这些解析解。
56.3. 价值函数迭代#
我们将采用的第一种方法是价值函数迭代。
这是一种逐次逼近的方法,在我们关于工作搜寻的讲座中已经讨论过。
基本思路是:
取一个任意的初始猜测 \(v\)。
得到一个更新 \(w\),其定义为
\[ w(x) = \max_{0\leq c \leq x} \{u(c) + \beta v(x-c)\} \]如果 \(w\) 与 \(v\) 大致相等,则停止;否则设 \(v=w\) 并返回第2步。
让我们把它写得更数学化一些。
56.3.1. 贝尔曼算子#
我们引入贝尔曼算子 \(T\),它以函数 \(v\) 为输入,返回一个新函数 \(Tv\),定义为
从 \(v\) 出发,我们得到 \(Tv\),再应用 \(T\) 得到 \(T^2 v := T(Tv)\),依此类推。
这被称为从初始猜测 \(v\) 出发,迭代贝尔曼算子。
正如我们在后面的讲座中详细讨论的那样,可以使用巴纳赫收缩映射定理来证明函数序列 \(T^n v\) 收敛到贝尔曼方程的解。
56.3.2. 拟合价值函数迭代#
消费 \(c\) 和状态变量 \(x\) 都是连续的。
这在数值计算方面造成了一些复杂性。
例如,我们需要存储每个函数 \(T^n v\) 以计算下一个迭代值 \(T^{n+1} v\)。
但这意味着我们必须在无限多个 \(x\) 处存储 \(T^n v(x)\),这通常是不可能的。
为了解决这个问题,我们将使用拟合价值函数迭代,这在之前关于工作搜寻的讲座中已经讨论过。
这个过程如下:
从一组值 \(\{ v_0, \ldots, v_I \}\) 开始,这些值表示初始函数 \(v\) 在网格点\(\{ x_0, \ldots, x_I \}\) 上的值。
通过线性插值,在状态空间 \(\mathbb{R}_+\) 上建立函数 \(\hat{v}\)。
通过反复求解贝尔曼方程中的最大化问题,获取并记录每个网格点 \(x_i\) 上的值 \(T \hat v(x_i)\)。
除非满足某个停止条件,否则设置 \(\{ v_0, \ldots, v_I \} = \{ T \hat v(x_0), \ldots, T \hat v(x_I) \}\) 并返回步骤2。
在步骤2中,我们将使用连续分段线性插值。
56.3.3. 实现#
下面的maximize函数是一个小型辅助函数,它将SciPy的最小化程序转换为一个最大化程序。
def maximize(g, a, b, args):
"""
在区间[a, b]上最大化函数g。
我们利用了这样一个事实:在任意区间上,g 的最大值点,同时也是 -g 的最小值点。
参数元组 args 收集传递给 g 的额外参数。
返回最大值和最大值点。
"""
objective = lambda x: -g(x, *args)
result = minimize_scalar(objective, bounds=(a, b), method='bounded')
maximizer, maximum = result.x, -result.fun
return maximizer, maximum
我们将参数 \(\beta\) 和 \(\gamma\) 存储在一个名为 CakeEating 的类中。
这个类还将提供一个名为 state_action_value 的方法。该方法用来返回在给定状态和函数 \(v\) 的猜测下,某个消费选择的价值。
class CakeEating:
def __init__(self,
β=0.96, # 折现因子
γ=1.5, # 相对风险厌恶程度
x_grid_min=1e-3, # 为了数值稳定性排除零
x_grid_max=2.5, # 蛋糕大小
x_grid_size=120):
self.β, self.γ = β, γ
# 设置网格
self.x_grid = np.linspace(x_grid_min, x_grid_max, x_grid_size)
# 效用函数
def u(self, c):
γ = self.γ
if γ == 1:
return np.log(c)
else:
return (c ** (1 - γ)) / (1 - γ)
# 效用函数的一阶导数
def u_prime(self, c):
return c ** (-self.γ)
def state_action_value(self, c, x, v_array):
"""
在给定 x 和 c 的情况下,贝尔曼方程右侧的值。
"""
u, β = self.u, self.β
v = lambda x: np.interp(x, self.x_grid, v_array)
return u(c) + β * v(x - c)
现在,我们定义贝尔曼算子:
def T(v, ce):
"""
贝尔曼算子。更新价值函数的猜测。
* ce 是 CakeEating 类的一个实例
* v 是一个数组,表示对价值函数的猜测
"""
v_new = np.empty_like(v)
for i, x in enumerate(ce.x_grid):
# 在状态 x 下最大化贝尔曼方程的右侧
v_new[i] = maximize(ce.state_action_value, 1e-10, x, (x, v))[1]
return v_new
在定义了贝尔曼算子之后,我们就可以开始求解这个模型了。
让我们先用默认参数创建一个CakeEating实例。
ce = CakeEating()
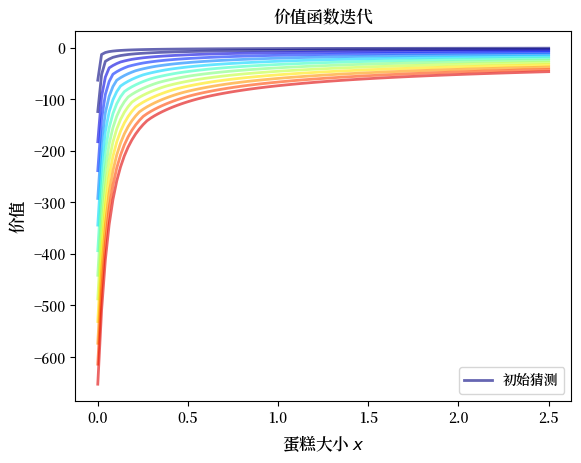
现在让我们看看价值函数的迭代过程。
我们从初始猜测 \(v = u\)开始,即对每个网格点\(x\),\(v(x) = u(x)\)。
x_grid = ce.x_grid
v = ce.u(x_grid) # 初始猜测
n = 12 # 迭代次数
fig, ax = plt.subplots()
ax.plot(x_grid, v, color=plt.cm.jet(0),
lw=2, alpha=0.6, label='初始猜测')
for i in range(n):
v = T(v, ce) # 应用贝尔曼算子
ax.plot(x_grid, v, color=plt.cm.jet(i / n), lw=2, alpha=0.6)
ax.legend()
ax.set_ylabel('价值', fontsize=12)
ax.set_xlabel('蛋糕大小 $x$', fontsize=12)
ax.set_title('价值函数迭代')
plt.show()
为了更系统地完成这项工作,我们引入一个名为compute_value_function的包装函数,该函数会一直迭代直到满足某些收敛条件。
def compute_value_function(ce,
tol=1e-4,
max_iter=1000,
verbose=True,
print_skip=25):
# 设置循环
v = np.zeros(len(ce.x_grid)) # 初始猜测
i = 0
error = tol + 1
while i < max_iter and error > tol:
v_new = T(v, ce)
error = np.max(np.abs(v - v_new))
i += 1
if verbose and i % print_skip == 0:
print(f"第 {i} 次迭代的误差是 {error}.")
v = v_new
if error > tol:
print("未能收敛!")
elif verbose:
print(f"\n在第 {i} 次迭代中收敛。")
return v_new
现在让我们调用它。注意,运行需要一点时间。
v = compute_value_function(ce)
第 25 次迭代的误差是 23.8003755134813.
第 50 次迭代的误差是 8.577577195046615.
第 75 次迭代的误差是 3.091330659691039.
第 100 次迭代的误差是 1.1141054204751981.
第 125 次迭代的误差是 0.4015199357729671.
第 150 次迭代的误差是 0.14470646660561215.
第 175 次迭代的误差是 0.052151735472762084.
第 200 次迭代的误差是 0.018795314242879613.
第 225 次迭代的误差是 0.006773769545588948.
第 250 次迭代的误差是 0.0024412443051460286.
第 275 次迭代的误差是 0.0008798164327572522.
第 300 次迭代的误差是 0.00031708295392718355.
第 325 次迭代的误差是 0.00011427565573285392.
在第 329 次迭代中收敛。
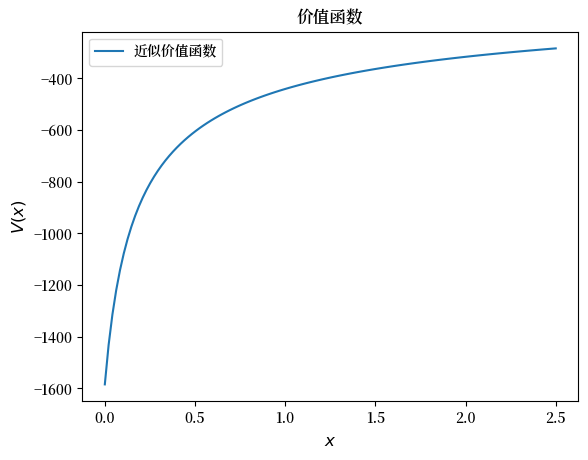
现在我们可以绘图查看收敛后的价值函数是什么样子。
fig, ax = plt.subplots()
ax.plot(x_grid, v, label='近似价值函数')
ax.set_ylabel('$V(x)$', fontsize=12)
ax.set_xlabel('$x$', fontsize=12)
ax.set_title('价值函数')
ax.legend()
plt.show()
接下来让我们将其与解析解进行比较。
v_analytical = v_star(ce.x_grid, ce.β, ce.γ)
fig, ax = plt.subplots()
ax.plot(x_grid, v_analytical, label='解析解')
ax.plot(x_grid, v, label='数值解')
ax.set_ylabel('$V(x)$', fontsize=12)
ax.set_xlabel('$x$', fontsize=12)
ax.legend()
ax.set_title('解析解与数值解的价值函数对比')
plt.show()
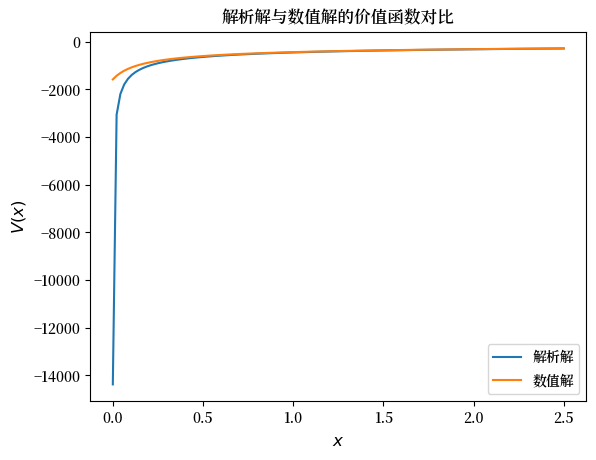
对于较大的 \(x\) 值,近似的质量相当好,但在下边界附近则要差一些。
这是因为效用函数以及由此产生的价值函数在接近下边界时非常陡峭,因此难以逼近。
56.3.4. 策略函数#
下面我们看看如何用它来计算最优策略。
在吃蛋糕问题的第一讲中,最优消费策略被证明为
让我们看看我们的数值结果是否能得到类似的形式。
我们的数值策略将是在一系列 \(x\) 点上计算
然后进行插值。
对于 \(v\),我们将使用我们上面获得的近似价值函数。
这是相关函数:
def σ(ce, v):
"""
最优策略函数。给定价值函数,
它找到每个状态下的最优消费。
* ce 是 CakeEating 的一个实例
* v 是一个价值函数数组
"""
c = np.empty_like(v)
for i in range(len(ce.x_grid)):
x = ce.x_grid[i]
# 在状态 x 下最大化贝尔曼方程的右侧
c[i] = maximize(ce.state_action_value, 1e-10, x, (x, v))[0]
return c
现在让我们传入近似值函数并计算最优消费:
c = σ(ce, v)
让我们将其与真实的解析解进行对比绘图
c_analytical = c_star(ce.x_grid, ce.β, ce.γ)
fig, ax = plt.subplots()
ax.plot(ce.x_grid, c_analytical, label='解析解')
ax.plot(ce.x_grid, c, label='数值解')
ax.set_ylabel(r'$\sigma(x)$')
ax.set_xlabel('$x$')
ax.legend()
plt.show()
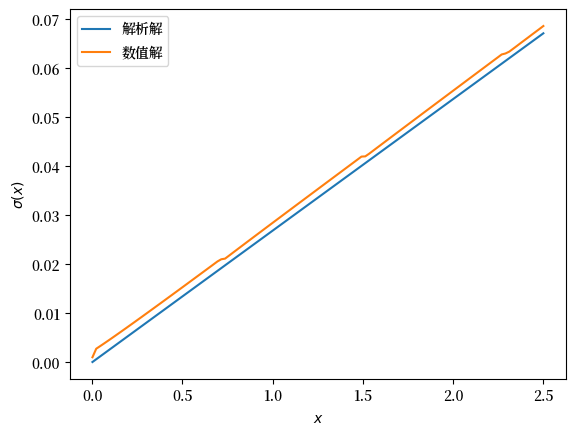
拟合效果还算合理,但并不完美。
我们可以通过增加网格规模,或者在价值函数迭代过程中降低误差容忍度来改进它。
然而,这两种方法都会导致更长的计算时间。
另一种可能性是使用一种替代算法,它既有可能缩短计算时间,同时还能提高精确度。
接下来我们将探讨这种方法。
56.4. 时间迭代#
现在我们来看另一种计算最优策略的方法。
回忆一下,最优策略满足欧拉方程
在计算上,我们可以从任意初始猜测 \(\sigma_0\) 开始,然后选择 \(c\) 来求解
在所有 \(x > 0\) 上解得的 \(c\) 就生成了一个 \(x\) 的函数。
我们称这个新函数为 \(\sigma_1\),并将它作为新的猜测,重复上述步骤。
这被称为时间迭代。
与值函数迭代一样,我们可以将更新步骤视为一个算子的作用,这次用 \(K\) 表示。
特别地,\(K\sigma\) 是使用刚才描述的程序从 \(\sigma\) 更新得到的策略。
我们将在下面的练习中使用这个术语。
相对于价值函数迭代,时间迭代的主要优势在于它在策略空间而不是价值函数空间中运算。
这很有帮助,因为策略函数的曲率较小,因此更容易逼近。
在练习中,你将被要求实现时间迭代,并与价值函数迭代进行比较。
你会发现这种方法更快,也更精确。
这是由于
刚才提到的曲率问题,以及
我们利用了更多的信息——在这里是一阶条件。
56.5. 练习#
练习 56.1
尝试如下对问题的修改:
让蛋糕大小不再按照 \(x_{t+1} = x_t - c_t\) 变化,而是按照
变化,其中 \(\alpha\) 是一个满足 \(0 < \alpha < 1\) 的参数。
(我们在学习最优增长模型时会看到这种更新规则。)
请对价值函数迭代代码进行相应修改,并绘制价值函数和策略函数。
尽量重用已有代码。
解答 练习 56.1
我们需要创建一个类来保存基本要素,并返回贝尔曼方程的右端。
我们将使用继承来最大化代码重用。
class OptimalGrowth(CakeEating):
"""
CakeEating的一个子类,添加了参数α并重写了
state_action_value方法。
"""
def __init__(self,
β=0.96, # 折现因子
γ=1.5, # 相对风险厌恶程度
α=0.4, # 生产力参数
x_grid_min=1e-3, # 为了数值稳定性排除零
x_grid_max=2.5, # 蛋糕大小
x_grid_size=120):
self.α = α
CakeEating.__init__(self, β, γ, x_grid_min, x_grid_max, x_grid_size)
def state_action_value(self, c, x, v_array):
"""
在给定 x 和 c 的情况下,贝尔曼方程右侧的值。
"""
u, β, α = self.u, self.β, self.α
v = lambda x: np.interp(x, self.x_grid, v_array)
return u(c) + β * v((x - c)**α)
og = OptimalGrowth()
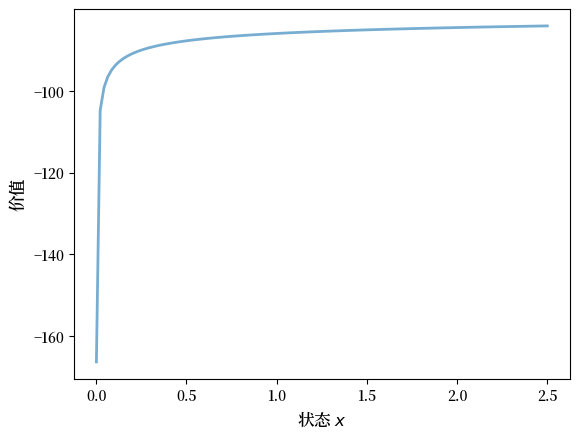
以下是计算得到的价值函数:
v = compute_value_function(og, verbose=False)
fig, ax = plt.subplots()
ax.plot(x_grid, v, lw=2, alpha=0.6)
ax.set_ylabel('价值', fontsize=12)
ax.set_xlabel('状态 $x$', fontsize=12)
plt.show()
下面是计算得到的策略函数,并与我们在标准吃蛋糕问题(\(\alpha = 1\))情况下推导出的解进行比较:
c_new = σ(og, v)
fig, ax = plt.subplots()
ax.plot(ce.x_grid, c_analytical, label=r'$\alpha=1$ 的解')
ax.plot(ce.x_grid, c_new, label=fr'$\alpha={og.α}$ 的解')
ax.set_ylabel('消费', fontsize=12)
ax.set_xlabel('$x$', fontsize=12)
ax.legend(fontsize=12)
plt.show()
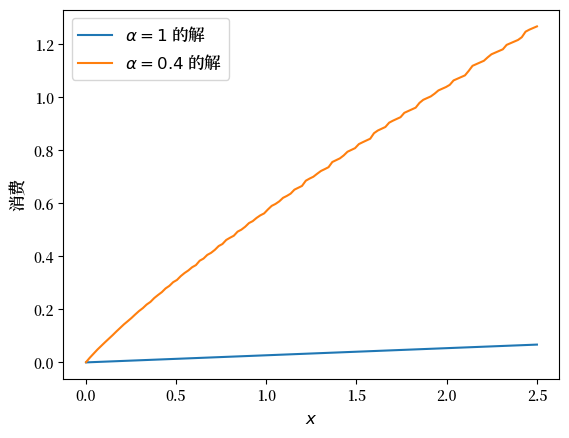
当 \(\alpha < 1\) 时,消费水平更高,因为对于较大的 \(x\),储蓄的回报较低。
练习 56.2
在原始设定下实现时间迭代(即,去掉上述练习中的修改)。
解答 练习 56.2
下面是一种实现时间迭代的方法:
def K(σ_array, ce):
"""
策略函数算子。给定策略函数,
使用欧拉方程更新最优消费。
* σ_array 是网格上策略函数值的数组
* ce 是 CakeEating 的一个实例
"""
u_prime, β, x_grid = ce.u_prime, ce.β, ce.x_grid
σ_new = np.empty_like(σ_array)
σ = lambda x: np.interp(x, x_grid, σ_array)
def euler_diff(c, x):
return u_prime(c) - β * u_prime(σ(x - c))
for i, x in enumerate(x_grid):
# 单独处理小的 x --- 有助于数值稳定性
if x < 1e-12:
σ_new[i] = 0.0
# 处理其他 x
else:
σ_new[i] = bisect(euler_diff, 1e-10, x - 1e-10, x)
return σ_new
def iterate_euler_equation(ce,
max_iter=500,
tol=1e-5,
verbose=True,
print_skip=25):
x_grid = ce.x_grid
σ = np.copy(x_grid) # 初始猜测
i = 0
error = tol + 1
while i < max_iter and error > tol:
σ_new = K(σ, ce)
error = np.max(np.abs(σ_new - σ))
i += 1
if verbose and i % print_skip == 0:
print(f"第 {i} 次迭代的误差是{error}。")
σ = σ_new
if error > tol:
print("未能收敛!")
elif verbose:
print(f"\n在 {i} 次迭代后收敛。")
return σ
ce = CakeEating(x_grid_min=0.0)
c_euler = iterate_euler_equation(ce)
第 25 次迭代的误差是0.0036456675931543225。
第 50 次迭代的误差是0.0008283185047067848。
第 75 次迭代的误差是0.00030791132300957147。
第 100 次迭代的误差是0.00013555502390599772。
第 125 次迭代的误差是6.417740905302616e-05。
第 150 次迭代的误差是3.1438019047758115e-05。
第 175 次迭代的误差是1.5658492883291464e-05。
在 192 次迭代后收敛。
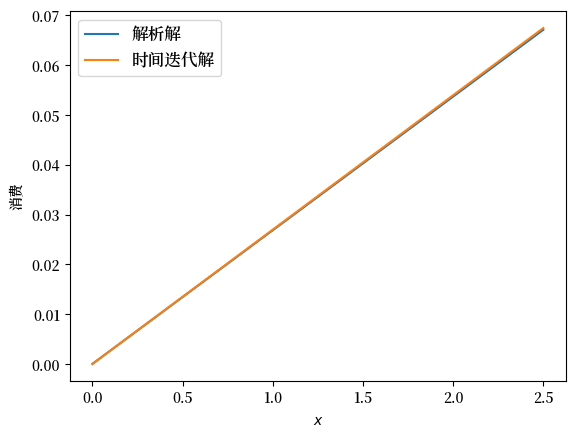
fig, ax = plt.subplots()
ax.plot(ce.x_grid, c_analytical, label='解析解')
ax.plot(ce.x_grid, c_euler, label='时间迭代解')
ax.set_ylabel('消费')
ax.set_xlabel('$x$')
ax.legend(fontsize=12)
plt.show()