9. 一些概率分布#
本讲座是这个关于矩阵统计的讲座的补充内容。
它描述了一些常见的分布,并使用Python从这些分布中进行采样。
它还描述了一种通过转换均匀概率分布的样本来从你自己设计的任意概率分布中采样的方法。
除了Anaconda中已有的库外,本讲座还需要以下库:
!pip install prettytable
像往常一样,我们先导入一些库
import numpy as np
import matplotlib.pyplot as plt
import prettytable as pt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib_inline.backend_inline import set_matplotlib_formats
set_matplotlib_formats('retina')
9.1. 一些离散概率分布#
让我们编写一些Python代码来计算单变量随机变量的均值和方差。
我们将使用代码来
从概率分布计算总体均值和方差
生成N个独立同分布的样本并计算样本均值和方差
比较总体和样本的均值和方差
9.2. 几何分布#
离散几何分布的概率质量函数为
其中\(k = 1, 2, \ldots\)是第一次成功之前的试验次数。
这个单参数概率分布的均值和方差为
让我们使用Python从该分布中抽取观测值,并将样本均值和方差与理论结果进行比较。
# 指定参数
p, n = 0.3, 1_000_000
# 从分布中抽取观测值
x = np.random.geometric(p, n)
# 计算样本均值和方差
μ_hat = np.mean(x)
σ2_hat = np.var(x)
print("样本均值为:", μ_hat, "\n样本方差为:", σ2_hat)
# 与理论结果比较
print("\n总体均值为:", 1/p)
print("总体方差为:", (1-p)/(p**2))
样本均值为: 3.330987
样本方差为: 7.766918605831001
总体均值为: 3.3333333333333335
总体方差为: 7.777777777777778
9.3. 帕斯卡(负二项)分布#
考虑一个独立伯努利试验序列。
设 \(p\) 为成功的概率。
设 \(X\) 为在获得 \(r\) 次成功之前失败的次数的随机变量。
其分布为
这里,我们从 \(k+r-1\) 个可能的结果中选择,因为最后一次抽取根据定义必须是成功的。
我们计算得到均值和方差为
# specify parameters
r, p, n = 10, 0.3, 1_000_000
# draw observations from the distribution
x = np.random.negative_binomial(r, p, n)
# compute sample mean and variance
μ_hat = np.mean(x)
σ2_hat = np.var(x)
print("The sample mean is: ", μ_hat, "\nThe sample variance is: ", σ2_hat)
print("\nThe population mean is: ", r*(1-p)/p)
print("The population variance is: ", r*(1-p)/p**2)
The sample mean is: 23.33395
The sample variance is: 77.63014139749997
The population mean is: 23.333333333333336
The population variance is: 77.77777777777779
9.4. 纽科姆-本福特分布#
纽科姆-本福特定律适用于许多数据集,例如向税务机关报告的收入,其中首位数字更可能是小数而不是大数。
参见 https://en.wikipedia.org/wiki/Benford’s_law
本福特概率分布为
其中 \(d\in\{1,2,\cdots,9\}\) 可以被视为数字序列中的首位数字。
这是一个定义明确的离散分布,因为我们可以验证概率是非负的且和为 \(1\)。
本福特分布的均值和方差为
我们使用numpy来验证上述结果并计算均值和方差。
Benford_pmf = np.array([np.log10(1+1/d) for d in range(1,10)])
k = np.arange(1, 10)
# mean
mean = k @ Benford_pmf
# variance
var = ((k - mean) ** 2) @ Benford_pmf
# verify sum to 1
print(np.sum(Benford_pmf))
print(mean)
print(var)
0.9999999999999999
3.440236967123206
6.056512631375668
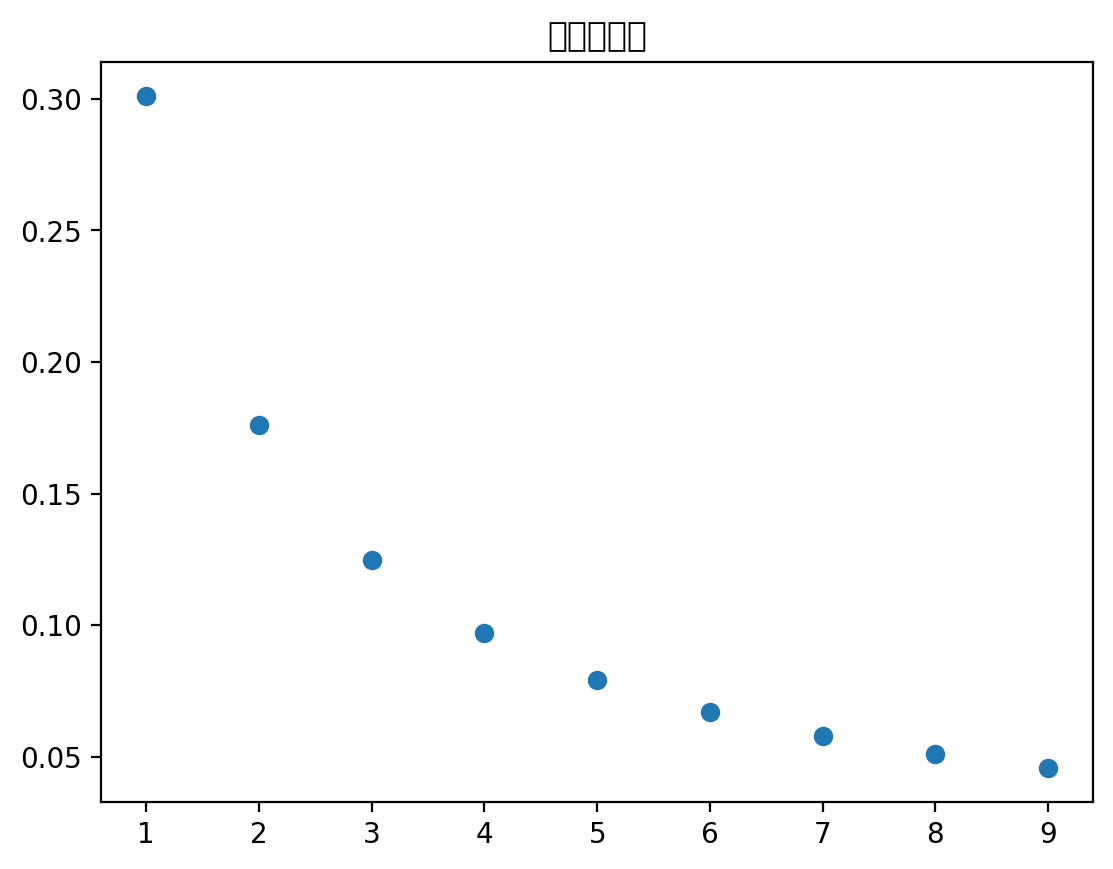
# 绘制分布图
plt.plot(range(1,10), Benford_pmf, 'o')
plt.title('本福特分布')
plt.show()
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 26412 (\N{CJK UNIFIED IDEOGRAPH-672C}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 31119 (\N{CJK UNIFIED IDEOGRAPH-798F}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 29305 (\N{CJK UNIFIED IDEOGRAPH-7279}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20998 (\N{CJK UNIFIED IDEOGRAPH-5206}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 24067 (\N{CJK UNIFIED IDEOGRAPH-5E03}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
现在让我们来看看一些连续型随机变量。
9.5. 一元高斯分布#
我们用
来表示概率分布
在下面的例子中,我们设定 \(\mu = 0, \sigma = 0.1\)。
# 指定参数
μ, σ = 0, 0.1
# 指定抽样次数
n = 1_000_000
# 从分布中抽取观测值
x = np.random.normal(μ, σ, n)
# 计算样本均值和方差
μ_hat = np.mean(x)
σ_hat = np.std(x)
print("样本均值为:", μ_hat)
print("样本标准差为:", σ_hat)
样本均值为: 1.2830896661547425e-05
样本标准差为: 0.10006393302760301
# 比较
print(μ-μ_hat < 1e-3)
print(σ-σ_hat < 1e-3)
True
True
9.6. 均匀分布#
总体均值和方差为
# 指定参数
a, b = 10, 20
# 指定抽样次数
n = 1_000_000
# 从分布中抽取观测值
x = a + (b-a)*np.random.rand(n)
# 计算样本均值和方差
μ_hat = np.mean(x)
σ2_hat = np.var(x)
print("样本均值为:", μ_hat, "\n样本方差为:", σ2_hat)
print("\n总体均值为:", (a+b)/2)
print("总体方差为:", (b-a)**2/12)
样本均值为: 15.000651886326272
样本方差为: 8.344469246550144
总体均值为: 15.0
总体方差为: 8.333333333333334
9.7. 混合离散-连续分布#
让我们用一个小故事来说明这个例子。
假设你去参加一个工作面试,你要么通过要么失败。
你有5%的机会通过面试,而且你知道如果通过的话,你的日薪会在300~400之间均匀分布。
我们可以用以下概率来描述你的日薪这个离散-连续变量:
让我们先生成一个随机样本并计算样本矩。
x = np.random.rand(1_000_000)
# x[x > 0.95] = 100*x[x > 0.95]+300
x[x > 0.95] = 100*np.random.rand(len(x[x > 0.95]))+300
x[x <= 0.95] = 0
μ_hat = np.mean(x)
σ2_hat = np.var(x)
print("样本均值是: ", μ_hat, "\n样本方差是: ", σ2_hat)
样本均值是: 17.53244291889172
样本方差是: 5870.046883934029
可以计算解析均值和方差:
mean = 0.0005*0.5*(400**2 - 300**2)
var = 0.95*17.5**2+0.0005/3*((400-17.5)**3-(300-17.5)**3)
print("mean: ", mean)
print("variance: ", var)
mean: 17.5
variance: 5860.416666666666
9.8. 从特定分布中抽取随机数#
假设我们有一个可以生成均匀随机变量的伪随机数,即具有如下概率分布:
我们如何将\(\tilde{X}\)转换为随机变量\(X\),使得\(\textrm{Prob}\{X=i\}=f_i,\quad i=0,\ldots,I-1\), 其中\(f_i\)是在\(i=0,1,\dots,I-1\)上的任意离散概率分布?
关键工具是累积分布函数(CDF)的逆函数。
注意,分布的CDF是单调且非递减的,取值在\(0\)和\(1\)之间。
我们可以按以下方式抽取具有已知CDF的随机变量\(X\)的样本:
从\([0,1]\)上的均匀分布中抽取随机变量\(u\)
将\(u\)的样本值代入目标CDF的**“逆函数”**得到\(X\)
\(X\)具有目标CDF
因此,知道分布的**“逆”**CDF就足以从这个分布中进行模拟。
备注
这个方法要求”逆”CDF必须存在。
逆CDF定义为:
这里我们使用下确界是因为CDF是非递减且右连续的函数。
因此,假设:
\(U\)是一个均匀随机变量\(U\in[0,1]\)
我们想要采样CDF为\(F\)的随机变量\(X\)
事实证明,如果我们抽取均匀随机数\(U\),然后通过以下方式计算\(X\):
那么\(X\)是一个随机变量,其累积分布函数为\(F_X(x)=F(x)=\textrm{Prob}\{X\le x\}\)。
我们将在\(F\)连续且双射的特殊情况下验证这一点,因此其反函数存在,可以表示为\(F^{-1}\)。
注意到
其中最后一个等式成立是因为\(U\)在\([0,1]\)上均匀分布,而给定\(x\)时,\(F(x)\)是一个也位于\([0,1]\)上的常数。
让我们用numpy来计算一些例子。
例子:连续几何(指数)分布
设\(X\)服从几何分布,参数为\(\lambda>0\)。
其密度函数为
其累积分布函数为
设\(U\)服从\([0,1]\)上的均匀分布。
\(X\)是一个随机变量,满足\(U=F(X)\)。
可以从以下推导得出\(X\)的分布:
让我们从\(U[0,1]\)中抽取\(u\)并计算\(x=\frac{log(1-U)}{-\lambda}\)。
我们将检验\(X\)是否似乎服从连续几何(指数)分布。
让我们用numpy来检验。
n, λ = 1_000_000, 0.3
# 生成均匀分布随机数
u = np.random.rand(n)
# 转换
x = -np.log(1-u)/λ
# 生成指数分布
x_g = np.random.exponential(1 / λ, n)
# 绘图并比较
plt.hist(x, bins=100, density=True)
plt.show()

plt.hist(x_g, bins=100, density=True, alpha=0.6)
plt.show()

几何分布
设 \(X\) 服从几何分布,即
其累积分布函数为
再次,设 \(\tilde{U}\) 服从均匀分布,我们要找到满足 \(F(X)=\tilde{U}\) 的 \(X\)。
让我们从以下推导 \(X\) 的分布:
然而,对于任何 \(x\geq0\),\(\tilde{U}=F^{-1}(X)\) 可能不是整数。
所以令
其中 \(\lceil . \rceil\) 是向上取整函数。
因此 \(x\) 是使离散几何累积分布函数大于或等于 \(\tilde{U}\) 的最小整数。
我们可以通过以下 numpy 程序验证 \(x\) 确实服从几何分布。
备注
指数分布是几何分布的连续模拟。
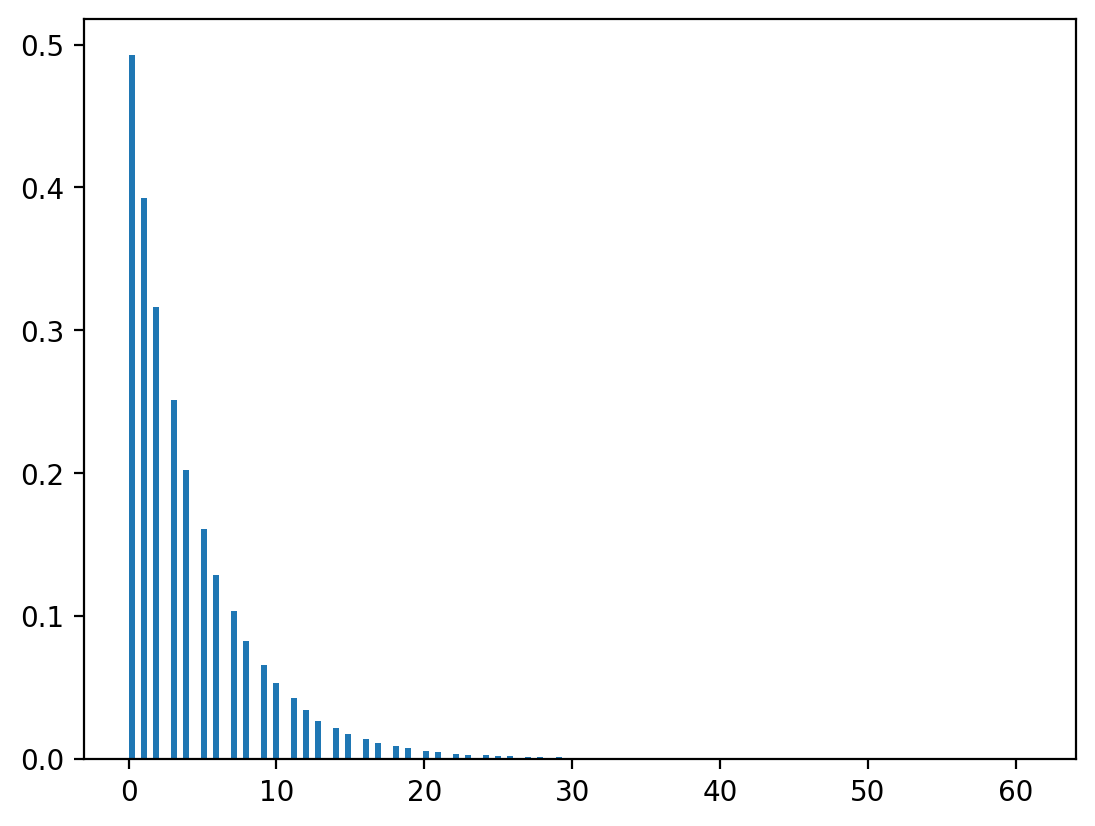
n, λ = 1_000_000, 0.8
# 生成均匀分布随机数
u = np.random.rand(n)
# 转换
x = np.ceil(np.log(1-u)/np.log(λ) - 1)
# 生成几何分布
x_g = np.random.geometric(1-λ, n)
# 绘图并比较
plt.hist(x, bins=150, density=True)
plt.show()
np.random.geometric(1-λ, n).max()
np.int64(79)
np.log(0.4)/np.log(0.3)
np.float64(0.7610560044063083)
plt.hist(x_g, bins=150, density=True, alpha=0.6)
plt.show()
