7. 使用牛顿法求解经济模型#
7.1. 概述#
例如,在简单的供需模型中,均衡价格是使超额需求为零的价格。
换句话说,均衡是超额需求函数的零点。
有各种算法可用于求解不动点和零点。
在本讲中,我们将学习一种重要的基于梯度的技术,称为牛顿法。
牛顿法并非总是有效,但在适用的情况下,其收敛速度通常比其他方法更快。
本讲将在一维和多维环境中应用牛顿法来解决不动点和零点计算问题。
牛顿法的基本思路是:
对于不动点问题,通过对函数 \(f\) 进行线性近似来寻找不动点。
对于零点问题,通过求解函数 \(f\) 的线性近似的零点,不断更新当前的估计值,直到收敛到真实的零点。
为了建立直观认识,我们首先考虑一个简单的一维不动点问题,其中我们已知解,并使用连续近似和牛顿法来求解。
然后我们将牛顿法应用到多维环境中,求解多种商品的市场均衡问题。
最后,我们将使用 autograd 包提供的自动微分功能来处理一个高维均衡问题。
!pip install autograd
我们在本讲中使用以下导入语句
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
from collections import namedtuple
from scipy.optimize import root
from autograd import jacobian
# 经过简单封装的numpy,以支持自动微分
import autograd.numpy as np
plt.rcParams["figure.figsize"] = (10, 5.7)
7.2. 用牛顿法计算不动点#
在本节中,我们将在索洛增长模型的框架下求解资本运动规律的不动点。
我们将通过可视化方式检查不动点,用连续逼近法求解,然后应用牛顿法来实现更快的收敛。
7.2.1. 索洛模型#
在索洛增长模型中,假设采用柯布-道格拉斯生产技术且人口零增长,资本的运动规律为
其中
\(k_t\) 是人均资本存量
\(A, \alpha>0\) 是生产参数,\(\alpha<1\)
\(s>0\) 是储蓄率
\(\delta \in(0,1)\) 是折旧率
在这个例子中,我们希望计算资本运动规律\(g\)的唯一严格正不动点。
换句话说,我们要寻找一个 \(k^* > 0\) 使得 \(g(k^*)=k^*\)。
这样的 \(k^*\) 被称为稳态, 因为当 \(k_t = k^*\) 时,\(k_{t+1} = k^*\)。
用纸笔解方程 \(g(k)=k\),你可以验证
7.2.2. 实现#
让我们使用 namedtuple 来存储我们的参数,这有助于保持代码的整洁和简洁。
SolowParameters = namedtuple("SolowParameters", ('A', 's', 'α', 'δ'))
此函数创建一个带有默认参数值的适当的namedtuple。
def create_solow_params(A=2.0, s=0.3, α=0.3, δ=0.4):
"创建一个带有默认值的索洛模型参数化。"
return SolowParameters(A=A, s=s, α=α, δ=δ)
接下来的两个函数实现运动定律(7.1)并存储真实的不动点\(k^*\)。
def g(k, params):
A, s, α, δ = params
return A * s * k**α + (1 - δ) * k
def exact_fixed_point(params):
A, s, α, δ = params
return ((s * A) / δ)**(1/(1 - α))
这是一个用于绘制45度动态图的函数。
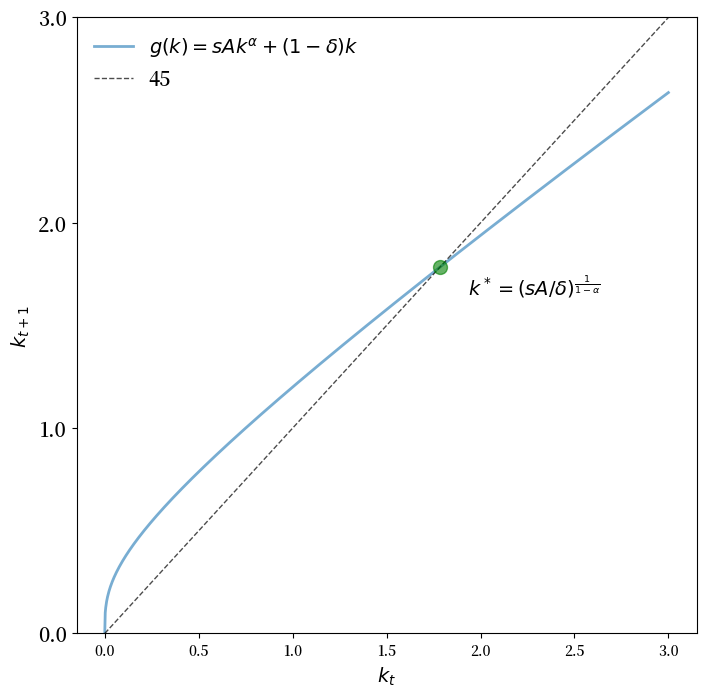
def plot_45(params, ax, fontsize=14):
k_min, k_max = 0.0, 3.0
k_grid = np.linspace(k_min, k_max, 1200)
# 绘制函数
lb = r"$g(k) = sAk^{\alpha} + (1 - \delta)k$"
ax.plot(k_grid, g(k_grid, params), lw=2, alpha=0.6, label=lb)
ax.plot(k_grid, k_grid, "k--", lw=1, alpha=0.7, label="45")
# 显示并标注固定点
kstar = exact_fixed_point(params)
fps = (kstar,)
ax.plot(fps, fps, "go", ms=10, alpha=0.6)
ax.annotate(r"$k^* = (sA / \delta)^{\frac{1}{1-\alpha}}$",
xy=(kstar, kstar),
xycoords="data",
xytext=(20, -20),
textcoords="offset points",
fontsize=fontsize)
ax.legend(loc="upper left", frameon=False, fontsize=fontsize)
ax.set_yticks((0, 1, 2, 3))
ax.set_yticklabels((0.0, 1.0, 2.0, 3.0), fontsize=fontsize)
ax.set_ylim(0, 3)
ax.set_xlabel("$k_t$", fontsize=fontsize)
ax.set_ylabel("$k_{t+1}$", fontsize=fontsize)
让我们看看两个参数化的45度图。
params = create_solow_params()
fig, ax = plt.subplots(figsize=(8, 8))
plot_45(params, ax)
plt.show()
params = create_solow_params(α=0.05, δ=0.5)
fig, ax = plt.subplots(figsize=(8, 8))
plot_45(params, ax)
plt.show()
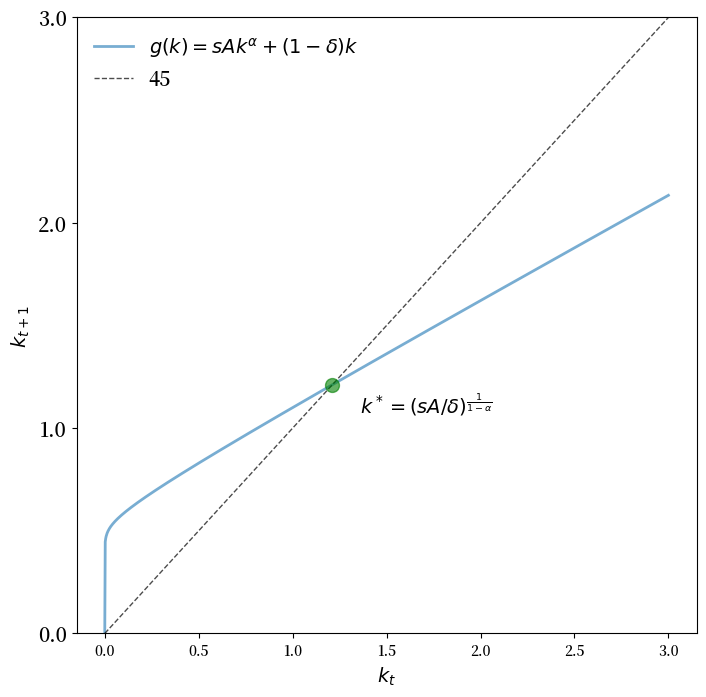
我们看到 \(k^*\) 确实是唯一的正固定点。
7.2.2.1. 连续近似法#
首先让我们用连续近似法来计算固定点。
在这种情况下,连续近似法意味着从某个初始状态 \(k_0\) 开始,使用运动规律反复更新资本。
这里是以特定的 \(k_0\) 为初始值得到的时间序列。
def compute_iterates(k_0, f, params, n=25):
"计算由任意函数f生成的长度为n的时间序列。"
k = k_0
k_iterates = []
for t in range(n):
k_iterates.append(k)
k = f(k, params)
return k_iterates
params = create_solow_params()
k_0 = 0.25
k_series = compute_iterates(k_0, g, params)
k_star = exact_fixed_point(params)
fig, ax = plt.subplots()
ax.plot(k_series, 'o')
ax.plot([k_star] * len(k_series), 'k--')
ax.set_ylim(0, 3)
plt.show()
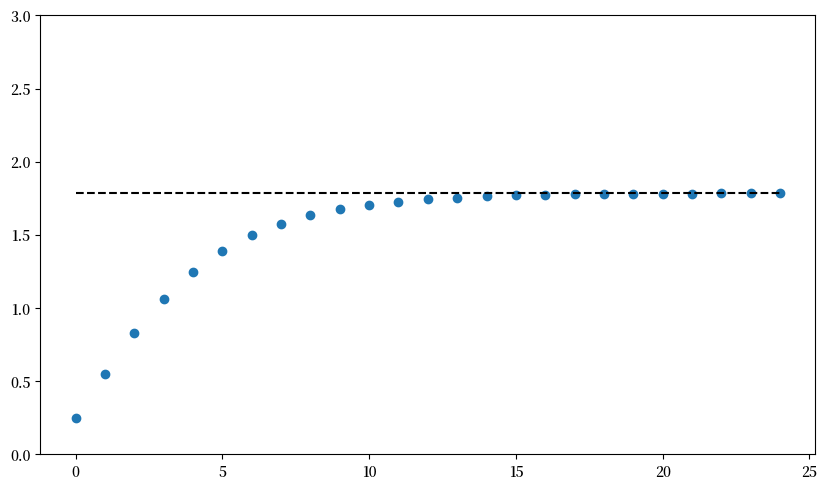
让我们看看长时间序列的输出。
k_series = compute_iterates(k_0, g, params, n=10_000)
k_star_approx = k_series[-1]
k_star_approx
1.7846741842265788
这接近真实值。
k_star
1.7846741842265788
7.2.2.2. 牛顿法#
一般来说,当对某个函数\(g\)应用牛顿不动点法时,我们从一个不动点的猜测值\(x_0\)开始,然后通过求解\(x_0\)处切线的不动点来更新。
首先,我们回顾一下\(g\)在\(x_0\)处的一阶近似(即\(g\)在\(x_0\)处的一阶泰勒近似)是以下函数:
我们通过计算满足以下等式的\(x_1\)来求解\(\hat g\)的不动点:
推广上述过程,牛顿不动点法的迭代公式为:
要实现牛顿法,我们观察到资本运动定律(7.1)的导数为:
让我们定义这个函数
def Dg(k, params):
A, s, α, δ = params
return α * A * s * k**(α-1) + (1 - δ)
下面的函数 \(q\) 表示 (7.3)。
def q(k, params):
return (g(k, params) - Dg(k, params) * k) / (1 - Dg(k, params))
现在让我们绘制一些轨迹。
def plot_trajectories(params,
k0_a=0.8, # 第一个初始条件
k0_b=3.1, # 第二个初始条件
n=20, # 时间序列长度
fs=14): # 字体大小
fig, axes = plt.subplots(2, 1, figsize=(10, 6))
ax1, ax2 = axes
ks1 = compute_iterates(k0_a, g, params, n)
ax1.plot(ks1, "-o", label="连续近似")
ks2 = compute_iterates(k0_b, g, params, n)
ax2.plot(ks2, "-o", label="连续近似")
ks3 = compute_iterates(k0_a, q, params, n)
ax1.plot(ks3, "-o", label="牛顿法")
ks4 = compute_iterates(k0_b, q, params, n)
ax2.plot(ks4, "-o", label="牛顿法")
for ax in axes:
ax.plot(k_star * np.ones(n), "k--")
ax.legend(fontsize=fs, frameon=False)
ax.set_ylim(0.6, 3.2)
ax.set_yticks((k_star,))
ax.set_yticklabels(("$k^*$",), fontsize=fs)
ax.set_xticks(np.linspace(0, 19, 20))
plt.show()
params = create_solow_params()
plot_trajectories(params)
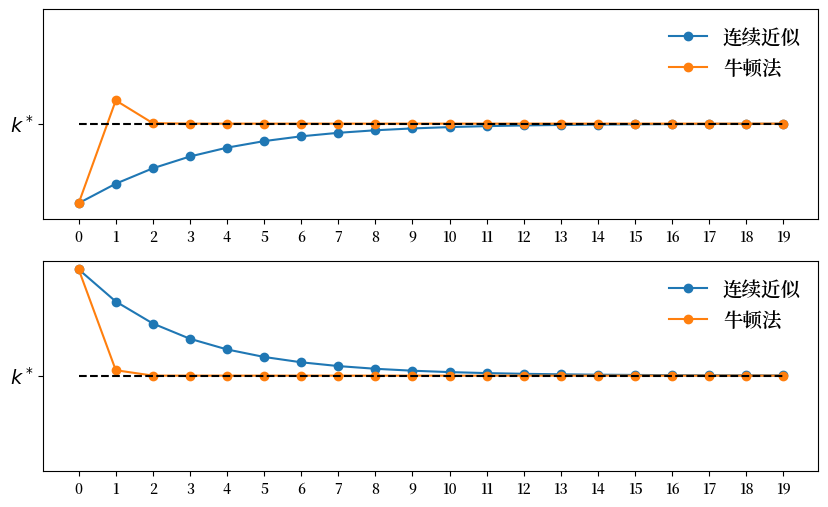
我们可以看到牛顿法比连续逼近法收敛得更快。
7.3. 一维求根#
在上一节中我们计算了不动点。
事实上,牛顿法更常与寻找函数零点的问题相关联。
让我们讨论这个”求根”问题,然后说明它与寻找不动点的问题是如何联系的。
7.3.1. 牛顿法求零点#
假设我们想要找到一个 \(x\) 使得对某个光滑函数 \(f\) (从实数映射到实数)有 \(f(x)=0\)。
假设我们有一个猜测值 \(x_0\) 并且想要将其更新为新的点 \(x_1\)。
作为第一步,我们取 \(f\) 在 \(x_0\) 处的一阶近似:
现在我们求解 \(\hat f\) 的零点。
具体来说,我们令 \(\hat{f}(x_1) = 0\) 并求解 \(x_1\),得到
对于一维零点查找问题,牛顿法的迭代公式可以概括为
以下代码实现了迭代公式 (7.5)
def newton(f, Df, x_0, tol=1e-7, max_iter=100_000):
x = x_0
# 实现零点查找公式
def q(x):
return x - f(x) / Df(x)
error = tol + 1
n = 0
while error > tol:
n += 1
if(n > max_iter):
raise Exception('达到最大迭代次数但未收敛')
y = q(x)
error = np.abs(x - y)
x = y
print(f'迭代 {n}, 误差 = {error:.5f}')
return x
许多库都实现了一维牛顿法,包括SciPy,所以这里的代码仅作说明用途。
(话虽如此,当我们想要使用自动微分或GPU加速等技术来应用牛顿法时,了解如何自己实现牛顿法会很有帮助。)
7.3.2. 在寻找不动点中的应用#
现在再次考虑索洛不动点计算,我们要求解满足\(g(k) = k\)的\(k\)值。
我们可以通过设定\(f(x) := g(x)-x\)将其转换为零点寻找问题。
显然,\(f\)的任何零点都是\(g\)的不动点。
让我们将这个想法应用到索洛问题中
params = create_solow_params()
k_star_approx_newton = newton(f=lambda x: g(x, params) - x,
Df=lambda x: Dg(x, params) - 1,
x_0=0.8)
迭代 1, 误差 = 1.27209
迭代 2, 误差 = 0.28180
迭代 3, 误差 = 0.00561
迭代 4, 误差 = 0.00000
迭代 5, 误差 = 0.00000
k_star_approx_newton
1.7846741842265788
结果证实了我们在上面图表中看到的收敛情况:仅需5次迭代就达到了非常精确的结果。
7.4. 多元牛顿法#
在本节中,我们将介绍一个双商品问题,可视化问题,并使用SciPy中的零点查找器和牛顿法来求解这个双商品市场的均衡。
然后,我们将这个概念扩展到一个包含5,000种商品的更大市场,并再次比较这两种方法的性能。
我们将看到使用牛顿法时能获得显著的性能提升。
7.4.1. 双商品市场均衡#
让我们从计算双商品问题的市场均衡开始。
我们考虑一个包含两种相关产品的市场,商品0和商品1,价格向量为\(p = (p_0, p_1)\)
在价格\(p\)下,商品\(i\)的供给为,
在价格\(p\)下,商品\(i\)的需求为,
这里的\(c_i\)、\(b_i\)和\(a_{ij}\)都是参数。
例如,这两种商品可能是通常一起使用的计算机组件,在这种情况下它们是互补品。因此需求取决于两种组件的价格。
超额需求函数为,
均衡价格向量\(p^*\)满足\(e_i(p^*) = 0\)。
我们设定
用于这个特定问题。
7.4.1.1. 图形化探索#
由于我们的问题只是二维的,我们可以使用图形分析来可视化并帮助理解这个问题。
我们的第一步是定义超额需求函数
下面的函数计算给定参数的超额需求
def e(p, A, b, c):
return np.exp(- A @ p) + c - b * np.sqrt(p)
我们的默认参数值将是
A = np.array([
[0.5, 0.4],
[0.8, 0.2]
])
b = np.ones(2)
c = np.ones(2)
在价格水平 \(p = (1, 0.5)\) 时,超额需求为
ex_demand = e((1.0, 0.5), A, b, c)
print(f'商品0的超额需求为 {ex_demand[0]:.3f} \n'
f'商品1的超额需求为 {ex_demand[1]:.3f}')
商品0的超额需求为 0.497
商品1的超额需求为 0.699
接下来我们在\((p_0, p_1)\)值的网格上绘制两个函数\(e_0\)和\(e_1\)的等高线图和曲面图。
我们将使用以下函数来构建等高线图
def plot_excess_demand(ax, good=0, grid_size=100, grid_max=4, surface=True):
# 创建一个100x100的网格
p_grid = np.linspace(0, grid_max, grid_size)
z = np.empty((100, 100))
for i, p_1 in enumerate(p_grid):
for j, p_2 in enumerate(p_grid):
z[i, j] = e((p_1, p_2), A, b, c)[good]
if surface:
cs1 = ax.contourf(p_grid, p_grid, z.T, alpha=0.5)
plt.colorbar(cs1, ax=ax, format="%.6f")
ctr1 = ax.contour(p_grid, p_grid, z.T, levels=[0.0])
ax.set_xlabel("$p_0$")
ax.set_ylabel("$p_1$")
ax.set_title(f'超额需求函数 {good}')
plt.clabel(ctr1, inline=1, fontsize=13)
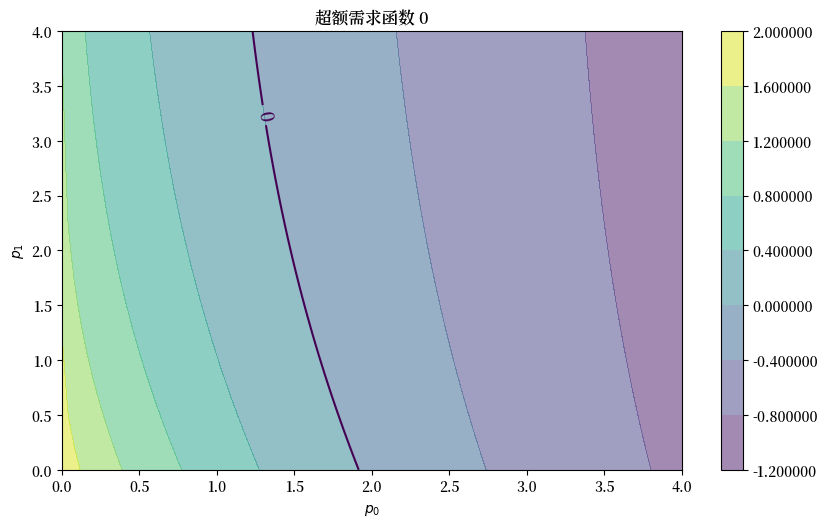
这是 \(e_0\) 的图
fig, ax = plt.subplots()
plot_excess_demand(ax, good=0)
plt.show()
这是 \(e_1\) 的图
fig, ax = plt.subplots()
plot_excess_demand(ax, good=1)
plt.show()
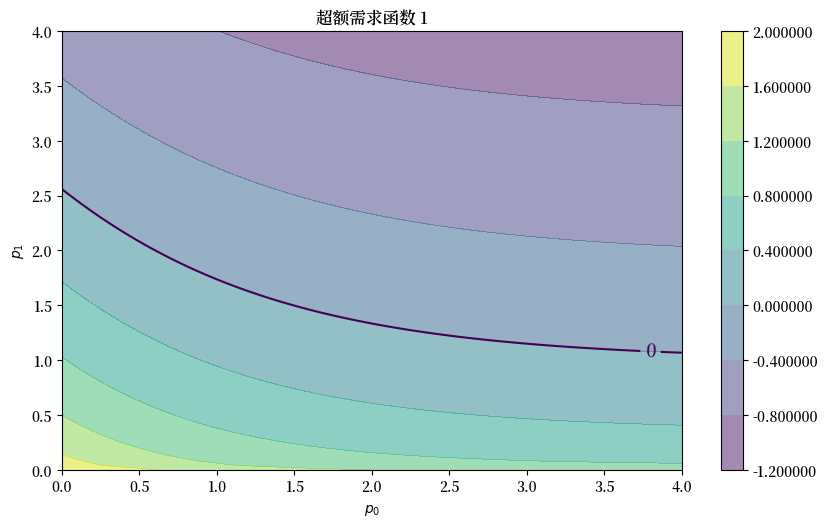
我们看到黑色的零等高线,它告诉我们何时\(e_i(p)=0\)。
对于使得\(e_i(p)=0\)的价格向量\(p\),我们知道商品\(i\)处于均衡状态(需求等于供给)。
如果这两条等高线在某个价格向量\(p^*\)处相交,那么\(p^*\)就是一个均衡价格向量。
fig, ax = plt.subplots(figsize=(10, 5.7))
for good in (0, 1):
plot_excess_demand(ax, good=good, surface=False)
plt.show()
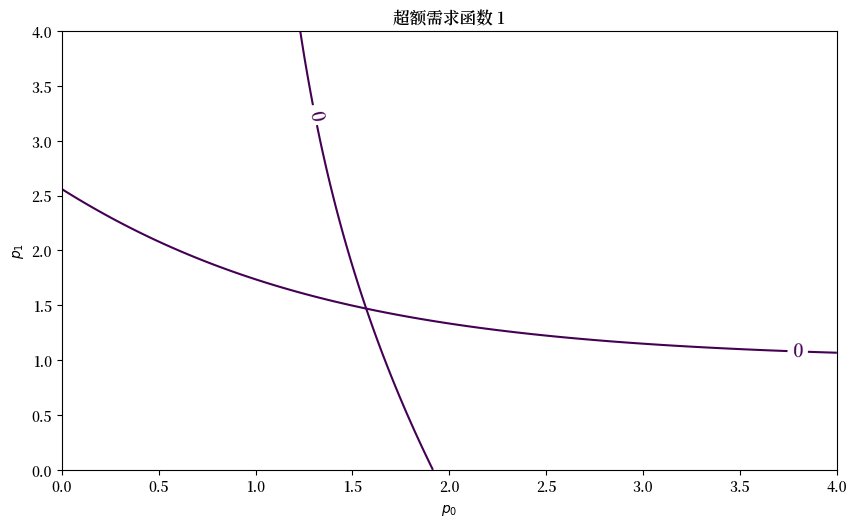
看起来在 \(p = (1.6, 1.5)\) 附近存在一个均衡点。
7.4.1.2. 使用多维根查找器#
为了更精确地求解 \(p^*\),我们使用 scipy.optimize 中的零点查找算法。
我们以 \(p = (1, 1)\) 作为初始猜测值。
init_p = np.ones(2)
这个算法使用改进的Powell方法来寻找零点
%%time
solution = root(lambda p: e(p, A, b, c), init_p, method='hybr')
CPU times: user 158 μs, sys: 16 μs, total: 174 μs
Wall time: 180 μs
这是得到的值
p = solution.x
p
array([1.57080182, 1.46928838])
这个结果看起来和我们从图中观察到的猜测很接近。我们可以把它代回到 \(e\) 中验证 \(e(p) \approx 0\)
np.max(np.abs(e(p, A, b, c)))
np.float64(2.0383694732117874e-13)
这确实是一个很小的误差。
7.4.1.3. 添加梯度信息#
在许多情况下,对于应用于光滑函数的零点查找算法,提供函数的雅可比矩阵可以带来更好的收敛性质。
这里我们手动计算雅可比矩阵的元素
def jacobian_e(p, A, b, c):
p_0, p_1 = p
a_00, a_01 = A[0, :]
a_10, a_11 = A[1, :]
j_00 = -a_00 * np.exp(-a_00 * p_0) - (b[0]/2) * p_0**(-1/2)
j_01 = -a_01 * np.exp(-a_01 * p_1)
j_10 = -a_10 * np.exp(-a_10 * p_0)
j_11 = -a_11 * np.exp(-a_11 * p_1) - (b[1]/2) * p_1**(-1/2)
J = [[j_00, j_01],
[j_10, j_11]]
return np.array(J)
%%time
solution = root(lambda p: e(p, A, b, c),
init_p,
jac=lambda p: jacobian_e(p, A, b, c),
method='hybr')
CPU times: user 211 μs, sys: 22 μs, total: 233 μs
Wall time: 236 μs
现在的解更加精确了(尽管在这个低维问题中,差异非常小):
p = solution.x
np.max(np.abs(e(p, A, b, c)))
np.float64(1.3322676295501878e-15)
7.4.1.4. 使用牛顿法#
现在让我们使用牛顿法来计算均衡价格,采用多变量版本的牛顿法
这是(7.5)的多变量版本
(这里的\(J_e(p_n)\)是在\(p_n\)处计算的\(e\)的雅可比矩阵。)
迭代从价格向量\(p_0\)的某个初始猜测开始。
在这里,我们不手动编写雅可比矩阵,而是使用autograd库中的jacobian()函数来自动求导并计算雅可比矩阵。
只需稍作修改,我们就可以将我们之前的尝试推广到多维问题
def newton(f, x_0, tol=1e-5, max_iter=10):
x = x_0
q = lambda x: x - np.linalg.solve(jacobian(f)(x), f(x))
error = tol + 1
n = 0
while error > tol:
n+=1
if(n > max_iter):
raise Exception('Max iteration reached without convergence')
y = q(x)
if(any(np.isnan(y))):
raise Exception('Solution not found with NaN generated')
error = np.linalg.norm(x - y)
x = y
print(f'iteration {n}, error = {error:.5f}')
print('\n' + f'Result = {x} \n')
return x
def e(p, A, b, c):
return np.exp(- np.dot(A, p)) + c - b * np.sqrt(p)
我们发现算法在4步内终止
%%time
p = newton(lambda p: e(p, A, b, c), init_p)
iteration 1, error = 0.62515
iteration 2, error = 0.11152
iteration 3, error = 0.00258
iteration 4, error = 0.00000
Result = [1.57080182 1.46928838]
CPU times: user 2.56 ms, sys: 0 ns, total: 2.56 ms
Wall time: 2.18 ms
np.max(np.abs(e(p, A, b, c)))
np.float64(1.461053500406706e-13)
结果非常准确。
7.4.2. 高维问题#
我们的下一步是研究一个有3,000种商品的大型市场。
使用GPU加速线性代数和自动微分的JAX版本可在此处获取
超额需求函数基本相同,但现在矩阵 \(A\) 是 \(3000 \times 3000\) 的,参数向量 \(b\) 和 \(c\) 是 \(3000 \times 1\) 的。
dim = 3000
np.random.seed(123)
# 创建随机矩阵A并将行归一化使其和为1
A = np.random.rand(dim, dim)
A = np.asarray(A)
s = np.sum(A, axis=0)
A = A / s
# 设置b和c
b = np.ones(dim)
c = np.ones(dim)
这是我们的初始条件
init_p = np.ones(dim)
%%time
p = newton(lambda p: e(p, A, b, c), init_p)
iteration 1, error = 23.22267
iteration 2, error = 3.94538
iteration 3, error = 0.08500
iteration 4, error = 0.00004
iteration 5, error = 0.00000
Result = [1.50185286 1.49865815 1.50028285 ... 1.50875149 1.48724784 1.48577532]
CPU times: user 32.4 s, sys: 192 ms, total: 32.6 s
Wall time: 30.7 s
np.max(np.abs(e(p, A, b, c)))
np.float64(1.5543122344752192e-15)
在相同的容差条件下,我们比较牛顿法与SciPy的root函数的运行时间和精确度
%%time
solution = root(lambda p: e(p, A, b, c),
init_p,
jac=lambda p: jacobian(e)(p, A, b, c),
method='hybr',
tol=1e-5)
CPU times: user 34.8 s, sys: 67.6 ms, total: 34.9 s
Wall time: 34.6 s
p = solution.x
np.max(np.abs(e(p, A, b, c)))
np.float64(8.295585953721485e-07)
7.5. 练习#
练习 7.1
考虑索洛固定点问题的三维扩展,其中
和之前一样,运动方程为
但现在 \(k_t\) 是一个 \(3 \times 1\) 向量。
使用牛顿法求解固定点,初始值如下:
提示
固定点的计算等价于计算满足 \(f(k^*) - k^* = 0\) 的 \(k^*\)。
如果你对你的解决方案不确定,可以从已解决的示例开始:
其中 \(s = 0.3\)、\(α = 0.3\) 和 \(δ = 0.4\),初始值为:
结果应该收敛到解析解。
解答 练习 7.1
让我们首先定义这个问题的参数
A = np.array([[2.0, 3.0, 3.0],
[2.0, 4.0, 2.0],
[1.0, 5.0, 1.0]])
s = 0.2
α = 0.5
δ = 0.8
initLs = [np.ones(3),
np.array([3.0, 5.0, 5.0]),
np.repeat(50.0, 3)]
然后定义(7.1)的多元版本
def multivariate_solow(k, A=A, s=s, α=α, δ=δ):
return (s * np.dot(A, k**α) + (1 - δ) * k)
让我们遍历每个初始值并查看输出结果
attempt = 1
for init in initLs:
print(f'尝试 {attempt}: 初始值为 {init} \n')
%time k = newton(lambda k: multivariate_solow(k) - k, \
init)
print('-'*64)
attempt += 1
尝试 1: 初始值为 [1. 1. 1.]
iteration 1, error = 50.49630
iteration 2, error = 41.10937
iteration 3, error = 4.29413
iteration 4, error = 0.38543
iteration 5, error = 0.00544
iteration 6, error = 0.00000
Result = [3.84058108 3.87071771 3.41091933]
CPU times: user 3.37 ms, sys: 3 μs, total: 3.37 ms
Wall time: 3.06 ms
----------------------------------------------------------------
尝试 2: 初始值为 [3. 5. 5.]
iteration 1, error = 2.07011
iteration 2, error = 0.12642
iteration 3, error = 0.00060
iteration 4, error = 0.00000
Result = [3.84058108 3.87071771 3.41091933]
CPU times: user 1.88 ms, sys: 0 ns, total: 1.88 ms
Wall time: 1.75 ms
----------------------------------------------------------------
尝试 3: 初始值为 [50. 50. 50.]
iteration 1, error = 73.00943
iteration 2, error = 6.49379
iteration 3, error = 0.68070
iteration 4, error = 0.01620
iteration 5, error = 0.00001
iteration 6, error = 0.00000
Result = [3.84058108 3.87071771 3.41091933]
CPU times: user 2.71 ms, sys: 0 ns, total: 2.71 ms
Wall time: 2.52 ms
----------------------------------------------------------------
我们发现,由于这个问题具有明确定义的性质,结果与初始值无关。
但是收敛所需的迭代次数取决于初始值。
让我们把输出结果代回公式中验证我们的最终结果
multivariate_solow(k) - k
array([-4.4408921e-16, -4.4408921e-16, 4.4408921e-16])
注意误差非常小。
我们也可以在已知解上测试我们的结果
A = np.array([[2.0, 0.0, 0.0],
[0.0, 2.0, 0.0],
[0.0, 0.0, 2.0]])
s = 0.3
α = 0.3
δ = 0.4
init = np.repeat(1.0, 3)
%time k = newton(lambda k: multivariate_solow(k, A=A, s=s, α=α, δ=δ) - k, \
init)
iteration 1, error = 1.57459
iteration 2, error = 0.21345
iteration 3, error = 0.00205
iteration 4, error = 0.00000
Result = [1.78467418 1.78467418 1.78467418]
CPU times: user 1.99 ms, sys: 0 ns, total: 1.99 ms
Wall time: 1.86 ms
结果与真实值非常接近,但仍有细微差异。
%time k = newton(lambda k: multivariate_solow(k, A=A, s=s, α=α, δ=δ) - k, \
init,\
tol=1e-7)
iteration 1, error = 1.57459
iteration 2, error = 0.21345
iteration 3, error = 0.00205
iteration 4, error = 0.00000
iteration 5, error = 0.00000
Result = [1.78467418 1.78467418 1.78467418]
CPU times: user 2.86 ms, sys: 0 ns, total: 2.86 ms
Wall time: 2.57 ms
我们可以看到它正在朝着更精确的解迈进。
练习 7.2
在这个练习中,让我们尝试不同的初始值,看看牛顿法对不同起始点的反应如何。
让我们定义一个具有以下默认值的三商品问题:
对于这个练习,使用以下极端价格向量作为初始值:
将容差设置为\(0.0\)以获得更精确的输出。
解答 练习 7.2
定义参数和初始值
A = np.array([
[0.2, 0.1, 0.7],
[0.3, 0.2, 0.5],
[0.1, 0.8, 0.1]
])
b = np.array([1.0, 1.0, 1.0])
c = np.array([1.0, 1.0, 1.0])
initLs = [np.repeat(5.0, 3),
np.ones(3),
np.array([4.5, 0.1, 4.0])]
让我们检查每个初始猜测值并查看输出结果
attempt = 1
for init in initLs:
print(f'尝试 {attempt}: 初始值为 {init} \n')
%time p = newton(lambda p: e(p, A, b, c), \
init, \
tol=1e-15, \
max_iter=15)
print('-'*64)
attempt += 1
尝试 1: 初始值为 [5. 5. 5.]
iteration 1, error = 9.24381
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/autograd/tracer.py:54: RuntimeWarning: invalid value encountered in sqrt
return f_raw(*args, **kwargs)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/autograd/numpy/numpy_vjps.py:184: RuntimeWarning: invalid value encountered in power
defvjp(anp.sqrt, lambda ans, x: lambda g: g * 0.5 * x**-0.5)
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
File <timed exec>:1
Cell In[34], line 12, in newton(f, x_0, tol, max_iter)
10 y = q(x)
11 if(any(np.isnan(y))):
---> 12 raise Exception('Solution not found with NaN generated')
13 error = np.linalg.norm(x - y)
14 x = y
Exception: Solution not found with NaN generated
----------------------------------------------------------------
尝试 2: 初始值为 [1. 1. 1.]
iteration 1, error = 0.73419
iteration 2, error = 0.12472
iteration 3, error = 0.00269
iteration 4, error = 0.00000
iteration 5, error = 0.00000
iteration 6, error = 0.00000
Result = [1.49744442 1.49744442 1.49744442]
CPU times: user 3.37 ms, sys: 2 μs, total: 3.37 ms
Wall time: 2.99 ms
----------------------------------------------------------------
尝试 3: 初始值为 [4.5 0.1 4. ]
iteration 1, error = 4.89202
iteration 2, error = 1.21206
iteration 3, error = 0.69421
iteration 4, error = 0.16895
iteration 5, error = 0.00521
iteration 6, error = 0.00000
iteration 7, error = 0.00000
iteration 8, error = 0.00000
Result = [1.49744442 1.49744442 1.49744442]
CPU times: user 3.93 ms, sys: 3 μs, total: 3.93 ms
Wall time: 3.47 ms
----------------------------------------------------------------
我们可以发现牛顿法对某些初始值可能会失败。
有时可能需要尝试几个初始猜测值才能实现收敛。
将结果代回公式中检验我们的结果
e(p, A, b, c)
array([ 0.00000000e+00, 0.00000000e+00, -2.22044605e-16])
我们可以看到结果非常精确。