13. 多元正态分布#
13.1. 概述#
本讲座介绍概率论、统计学和经济学中的一个重要工具,即多元正态分布。
在本讲座中,你将学习以下公式:
长度为N的随机向量 \(x\) 的联合分布
\(x\)的所有子向量的边缘分布
\(x\)的子向量在其他子向量条件下的条件分布
我们将使用多元正态分布来构建一些有用的模型:
智商(IQ)的因子分析模型
两种独立固有能力(如数学和语言能力)的因子分析模型
更一般的因子分析模型
作为因子分析模型近似的主成分分析(PCA)
由线性随机差分方程生成的时间序列
最优线性滤波理论
13.2. 多元正态分布#
本讲将定义一个Python类MultivariateNormal,用于生成与多元正态分布相关的边缘和条件分布。
对于多元正态分布,非常方便的是:
条件期望等于线性最小二乘投影
条件分布由多元线性回归表征
我们将把我们的Python类应用到一些例子中。
我们使用以下导入:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5) #设置默认图形大小
import numpy as np
from numba import jit
import statsmodels.api as sm
假设 \(N \times 1\) 随机向量 \(z\) 具有多元正态概率密度。
这意味着概率密度的形式为
其中 \(\mu=Ez\) 是随机向量 \(z\) 的均值,\(\Sigma=E\left(z-\mu\right)\left(z-\mu\right)^\prime\) 是 \(z\) 的协方差矩阵。
协方差矩阵 \(\Sigma\) 是对称且正定的。
@jit
def f(z, μ, Σ):
"""
多元正态分布的密度函数。
参数
---------------
z: ndarray(float, dim=2)
随机向量,N x 1
μ: ndarray(float, dim=1 or 2)
z的均值,N x 1
Σ: ndarray(float, dim=2)
z的协方差矩阵,N x 1
"""
z = np.atleast_2d(z)
μ = np.atleast_2d(μ)
Σ = np.atleast_2d(Σ)
N = z.size
temp1 = np.linalg.det(Σ) ** (-1/2)
temp2 = np.exp(-.5 * (z - μ).T @ np.linalg.inv(Σ) @ (z - μ))
return (2 * np.pi) ** (-N/2) * temp1 * temp2
对于某个整数 \(k\in \{1,\dots, N-1\}\),将 \(z\) 分割为
其中 \(z_1\) 是一个 \(\left(N-k\right)\times1\) 向量,\(z_2\) 是一个 \(k\times1\) 向量。
令
为 \(\mu\) 和 \(\Sigma\) 的相应分割。
\(z_1\) 的边缘分布是:
多元正态分布,均值为 \(\mu_1\),协方差矩阵为 \(\Sigma_{11}\)。
\(z_2\) 的边缘分布是:
多元正态分布,均值为 \(\mu_2\),协方差矩阵为 \(\Sigma_{22}\)。
在给定 \(z_2\) 条件下,\(z_1\) 的条件分布是:
多元正态分布,均值为
协方差矩阵为
其中
是一个 \(\left(N-k\right) \times k\) 的总体回归系数矩阵,表示 \((N -k) \times 1\) 随机向量 \(z_1 - \mu_1\) 对 \(k \times 1\) 随机向量 \(z_2 - \mu_2\) 的回归系数。
以下类构造了一个多元正态分布实例,具有两个方法:
partition方法计算 \(\beta\),以 \(k\) 作为输入cond_dist方法计算 \(z_1\) 在给定 \(z_2\) 条件下的分布,或 \(z_2\) 在给定 \(z_1\) 条件下的分布
class MultivariateNormal:
"""
多元正态分布类。
参数
----------
μ: ndarray(float, dim=1)
z的均值,N乘1
Σ: ndarray(float, dim=2)
z的协方差矩阵,N乘1
属性
---------
μ, Σ:
见参数
μs: list(ndarray(float, dim=1))
按顺序排列的均值向量μ1和μ2的列表
Σs: list(list(ndarray(float, dim=2)))
按顺序排列的协方差矩阵Σ11、Σ12、Σ21、Σ22的二维列表
βs: list(ndarray(float, dim=1))
按顺序排列的回归系数β1和β2的列表
"""
def __init__(self, μ, Σ):
"初始化"
self.μ = np.array(μ)
self.Σ = np.atleast_2d(Σ)
def partition(self, k):
"""
给定k,将随机向量z分割为大小为k的向量z1和大小为N-k的向量z2。
相应地将均值向量μ分割为μ1和μ2,将协方差矩阵Σ分割为Σ11、Σ12、
Σ21、Σ22。使用分割后的数组计算回归系数β1和β2。
"""
μ = self.μ
Σ = self.Σ
self.μs = [μ[:k], μ[k:]]
self.Σs = [[Σ[:k, :k], Σ[:k, k:]],
[Σ[k:, :k], Σ[k:, k:]]]
self.βs = [self.Σs[0][1] @ np.linalg.inv(self.Σs[1][1]),
self.Σs[1][0] @ np.linalg.inv(self.Σs[0][0])]
def cond_dist(self, ind, z):
"""
计算在给定z2条件下z1的条件分布,或反之。
参数ind决定我们是计算z1的条件分布(ind=0)还是z2的条件分布(ind=1)。
返回值
---------
μ_hat: ndarray(float, ndim=1)
z1或z2的条件均值。
Σ_hat: ndarray(float, ndim=2)
z1或z2的条件协方差矩阵。
"""
β = self.βs[ind]
μs = self.μs
Σs = self.Σs
μ_hat = μs[ind] + β @ (z - μs[1-ind])
Σ_hat = Σs[ind][ind] - β @ Σs[1-ind][1-ind] @ β.T
return μ_hat, Σ_hat
让我们通过一系列示例来运用这段代码。
我们先从一个简单的二元示例开始;之后我们将转向三元示例。
我们将使用我们的MultivariateNormal类来计算一些条件分布的总体矩。
为了增添趣味,我们还将通过生成模拟数据并计算线性最小二乘回归来计算相关总体回归的样本类比。
我们将比较这些模拟数据的线性最小二乘回归与其总体对应值。
13.3. 二元示例#
我们从由以下参数确定的二元正态分布开始
μ = np.array([.5, 1.])
Σ = np.array([[1., .5], [.5 ,1.]])
# 构建多元正态分布实例
multi_normal = MultivariateNormal(μ, Σ)
k = 1 # 选择分区
# 分区并计算回归系数
multi_normal.partition(k)
multi_normal.βs[0],multi_normal.βs[1]
(array([[0.5]]), array([[0.5]]))
让我们说明一下你可以把任何东西都可以回归到其他任何东西上这个事实。
我们已经计算了所需的一切,可以计算两条回归线,一条是 \(z_2\) 对 \(z_1\) 的回归,另一条是 \(z_1\) 对 \(z_2\) 的回归。
我们将这些回归表示为
和
其中我们有总体最小二乘正交条件
和
让我们计算\(a_1, a_2, b_1, b_2\)。
beta = multi_normal.βs
a1 = μ[0] - beta[0]*μ[1]
b1 = beta[0]
a2 = μ[1] - beta[1]*μ[0]
b2 = beta[1]
让我们打印出截距和斜率。
对于 \(z_1\) 对 \(z_2\) 的回归,我们有
print ("a1 = ", a1)
print ("b1 = ", b1)
a1 = [[0.]]
b1 = [[0.5]]
对于 \(z_2\) 对 \(z_1\) 的回归,我们有
print ("a2 = ", a2)
print ("b2 = ", b2)
a2 = [[0.75]]
b2 = [[0.5]]
现在让我们绘制这两条回归线并仔细观察。
z2 = np.linspace(-4,4,100)
a1 = np.squeeze(a1)
b1 = np.squeeze(b1)
a2 = np.squeeze(a2)
b2 = np.squeeze(b2)
z1 = b1*z2 + a1
z1h = z2/b2 - a2/b2
fig = plt.figure(figsize=(12,12))
ax = fig.add_subplot(1, 1, 1)
ax.set(xlim=(-4, 4), ylim=(-4, 4))
ax.spines['left'].set_position('center')
ax.spines['bottom'].set_position('zero')
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
plt.ylabel('$z_1$', loc = 'top')
plt.xlabel('$z_2$,', loc = 'right')
plt.title('两条回归线')
plt.plot(z2,z1, 'r', label = "$z_1$ 对 $z_2$ 的回归")
plt.plot(z2,z1h, 'b', label = "$z_2$ 对 $z_1$ 的回归")
plt.legend()
plt.show()

红线是在给定 \(z_2\) 条件下 \(z_1\) 的期望值。
红线的截距和斜率是
print("a1 = ", a1)
print("b1 = ", b1)
a1 = 0.0
b1 = 0.5
蓝线是在给定 \(z_1\) 条件下 \(z_2\) 的期望值。
蓝线的截距和斜率是
print("-a2/b2 = ", - a2/b2)
print("1/b2 = ", 1/b2)
-a2/b2 = -1.5
1/b2 = 2.0
我们可以使用这些回归线或我们的代码来计算条件期望。
让我们计算在给定 \(z_1=5\) 条件下 \(z_2\) 分布的均值和方差。
之后我们将对调回归中左右两边的变量。
# compute the cond. dist. of z1
ind = 1
z1 = np.array([5.]) # given z1
μ2_hat, Σ2_hat = multi_normal.cond_dist(ind, z1)
print('μ2_hat, Σ2_hat = ', μ2_hat, Σ2_hat)
μ2_hat, Σ2_hat = [3.25] [[0.75]]
现在让我们计算在 \(z_2=5\) 的条件下 \(z_1\) 的分布的均值和方差。
# 计算 z1 的条件分布
ind = 0
z2 = np.array([5.]) # 给定 z2
μ1_hat, Σ1_hat = multi_normal.cond_dist(ind, z2)
print('μ1_hat, Σ1_hat = ', μ1_hat, Σ1_hat)
μ1_hat, Σ1_hat = [2.5] [[0.75]]
让我们比较(1)前面的总体均值和方差,与(2)从大样本抽取并对 \(z_1 - \mu_1\) 和 \(z_2 - \mu_2\) 进行回归的结果。
我们知道
这可以重新整理为
我们预计,随着样本量越来越大,估计的OLS系数将收敛到 \(\beta\),\(\epsilon\) 的估计方差将收敛到 \(\hat{\Sigma}_1\)。
n = 1_000_000 # 样本量
# 模拟多元正态随机向量
data = np.random.multivariate_normal(μ, Σ, size=n)
z1_data = data[:, 0]
z2_data = data[:, 1]
# OLS回归
μ1, μ2 = multi_normal.μs
results = sm.OLS(z1_data - μ1, z2_data - μ2).fit()
让我们比较前面的总体 \(\beta\) 与 \(z_2 - \mu_2\) 的 OLS 样本估计值
multi_normal.βs[0], results.params
(array([[0.5]]), array([0.50022045]))
让我们将我们的总体 \(\hat{\Sigma}_1\) 与 \(\epsilon\) 的自由度调整后的方差估计进行比较
Σ1_hat, results.resid @ results.resid.T / (n - 1)
(array([[0.75]]), np.float64(0.7484953153220685))
最后,让我们计算 \(\hat{E z_1 | z_2}\) 的估计值并将其与 \(\hat{\mu}_1\) 进行比较
μ1_hat, results.predict(z2 - μ2) + μ1
(array([2.5]), array([2.5008818]))
因此,在每种情况下,对于我们的大样本量,样本类比都与其总体对应值非常接近。
大数定律解释了为什么样本类比会接近总体对象。
13.4. 三变量示例#
让我们将代码应用到一个三变量示例中。
我们将按如下方式指定均值向量和协方差矩阵。
μ = np.random.random(3)
C = np.random.random((3, 3))
Σ = C @ C.T # positive semi-definite
multi_normal = MultivariateNormal(μ, Σ)
μ, Σ
(array([0.40653751, 0.18563275, 0.83766714]),
array([[2.37657072, 2.17536841, 1.51175486],
[2.17536841, 2.01767205, 1.37365633],
[1.51175486, 1.37365633, 0.96720665]]))
k = 1
multi_normal.partition(k)
让我们计算在给定 \(z_{2}=\left[\begin{array}{c} 2\\ 5 \end{array}\right]\) 条件下 \(z_1\) 的分布。
ind = 0
z2 = np.array([2., 5.])
μ1_hat, Σ1_hat = multi_normal.cond_dist(ind, z2)
n = 1_000_000
data = np.random.multivariate_normal(μ, Σ, size=n)
z1_data = data[:, :k]
z2_data = data[:, k:]
μ1, μ2 = multi_normal.μs
results = sm.OLS(z1_data - μ1, z2_data - μ2).fit()
如上所述,我们依次比较总体和样本回归系数、条件协方差矩阵和条件均值向量。
multi_normal.βs[0], results.params
(array([[0.42430555, 0.96039958]]), array([0.42418598, 0.96060712]))
Σ1_hat, results.resid @ results.resid.T / (n - 1)
(array([[0.0016611]]), np.float64(0.001658403599760713))
μ1_hat, results.predict(z2 - μ2) + μ1
(array([5.17388634]), array([5.17453327]))
再一次,样本类比很好地近似了它们的总体对应值。
13.5. 一维智力(IQ)#
让我们来看一个更接近现实生活的例子,即从一系列测试分数中推断出一个称为IQ的一维智力测量值。
第 \(i\) 个测试分数 \(y_i\) 等于未知标量IQ \(\theta\) 和随机变量 \(w_{i}\) 的和。
对于一群人的IQ分布是一个正态随机变量,描述如下:
我们假设测试分数中的噪声 \(\{w_i\}_{i=1}^N\) 是独立同分布的,且与IQ不相关。
我们还假设 \(\{w_i\}_{i=1}^{n+1}\) 是独立同分布的标准正态分布:
以下系统描述了我们感兴趣的 \((n+1) \times 1\) 随机向量 \(X\):
或等价地,
其中 \(X = \begin{bmatrix} y \cr \theta \end{bmatrix}\), \(\boldsymbol{1}_{n+1}\) 是一个大小为 \(n+1\) 的全\(1\)向量, 而 \(D\) 是一个 \((n+1) \times (n+1)\) 的矩阵。
让我们定义一个Python函数来构造我们已知遵循多元正态分布的随机向量 \(X\) 的均值 \(\mu\) 和协方差矩阵 \(\Sigma\)。
该函数的参数是测试次数 \(n\)、IQ分布的均值 \(\mu_{\theta}\) 和标准差 \(\sigma_\theta\),以及测试分数中随机性的标准差 \(\sigma_{y}\)。
def construct_moments_IQ(n, μθ, σθ, σy):
μ_IQ = np.full(n+1, μθ)
D_IQ = np.zeros((n+1, n+1))
D_IQ[range(n), range(n)] = σy
D_IQ[:, n] = σθ
Σ_IQ = D_IQ @ D_IQ.T
return μ_IQ, Σ_IQ, D_IQ
现在让我们考虑这个模型的一个具体实例。
假设我们记录了 \(50\) 个测试分数,并且我们知道 \(\mu_{\theta}=100\),\(\sigma_{\theta}=10\),以及 \(\sigma_{y}=10\)。
我们可以使用construct_moments_IQ函数轻松计算\(X\)的均值向量和协方差矩阵,如下所示。
n = 50
μθ, σθ, σy = 100., 10., 10.
μ_IQ, Σ_IQ, D_IQ = construct_moments_IQ(n, μθ, σθ, σy)
μ_IQ, Σ_IQ, D_IQ
(array([100., 100., 100., 100., 100., 100., 100., 100., 100., 100., 100.,
100., 100., 100., 100., 100., 100., 100., 100., 100., 100., 100.,
100., 100., 100., 100., 100., 100., 100., 100., 100., 100., 100.,
100., 100., 100., 100., 100., 100., 100., 100., 100., 100., 100.,
100., 100., 100., 100., 100., 100., 100.]),
array([[200., 100., 100., ..., 100., 100., 100.],
[100., 200., 100., ..., 100., 100., 100.],
[100., 100., 200., ..., 100., 100., 100.],
...,
[100., 100., 100., ..., 200., 100., 100.],
[100., 100., 100., ..., 100., 200., 100.],
[100., 100., 100., ..., 100., 100., 100.]]),
array([[10., 0., 0., ..., 0., 0., 10.],
[ 0., 10., 0., ..., 0., 0., 10.],
[ 0., 0., 10., ..., 0., 0., 10.],
...,
[ 0., 0., 0., ..., 10., 0., 10.],
[ 0., 0., 0., ..., 0., 10., 10.],
[ 0., 0., 0., ..., 0., 0., 10.]]))
我们现在可以使用我们的MultivariateNormal类来构建一个实例,然后按照我们的需要对均值向量和协方差矩阵进行分割。
我们想要对IQ,即随机变量 \(\theta\)(我们不知道的),测试分数的向量 \(y\)(我们知道的)进行回归。
我们选择k=n,这样 \(z_{1} = y\) 且 \(z_{2} = \theta\)。
multi_normal_IQ = MultivariateNormal(μ_IQ, Σ_IQ)
k = n
multi_normal_IQ.partition(k)
使用生成器 multivariate_normal,我们可以从我们的分布中抽取一次随机向量,然后计算在给定测试分数条件下 \(\theta\) 的分布。
让我们来做这个,然后打印出一些相关的数值。
x = np.random.multivariate_normal(μ_IQ, Σ_IQ)
y = x[:-1] # 测试分数
θ = x[-1] # 智商
# 真实值
θ
np.float64(104.53389406085986)
方法 cond_dist 接收测试分数 \(y\) 作为输入,并返回智商 \(\theta\) 的条件正态分布。
在下面的代码中,ind 设置回归右侧的变量。
根据我们定义向量 \(X\) 的方式,我们需要设置 ind=1 以使 \(\theta\) 成为总体回归中的左侧变量。
ind = 1
multi_normal_IQ.cond_dist(ind, y)
(array([104.0650503]), array([[1.96078431]]))
第一个数字是条件均值 \(\hat{\mu}_{\theta}\),第二个是条件方差 \(\hat{\Sigma}_{\theta}\)。
额外的测试分数如何影响我们的推断?
为了阐明这一点,我们通过将条件集中的测试分数数量从 \(1\) 变化到 \(n\),计算一系列 \(\theta\) 的条件分布。
我们将制作一个漂亮的图表,展示随着更多测试结果的出现,我们对这个人的智商判断是如何变化的。
# 存放矩的数组
μθ_hat_arr = np.empty(n)
Σθ_hat_arr = np.empty(n)
# 循环测试分数的数量
for i in range(1, n+1):
# 构建多元正态分布实例
μ_IQ_i, Σ_IQ_i, D_IQ_i = construct_moments_IQ(i, μθ, σθ, σy)
multi_normal_IQ_i = MultivariateNormal(μ_IQ_i, Σ_IQ_i)
# 分割并计算条件分布
multi_normal_IQ_i.partition(i)
scores_i = y[:i]
μθ_hat_i, Σθ_hat_i = multi_normal_IQ_i.cond_dist(1, scores_i)
# 存储结果
μθ_hat_arr[i-1] = μθ_hat_i[0]
Σθ_hat_arr[i-1] = Σθ_hat_i[0, 0]
# 将方差转换为标准差
σθ_hat_arr = np.sqrt(Σθ_hat_arr)
μθ_hat_lower = μθ_hat_arr - 1.96 * σθ_hat_arr
μθ_hat_higher = μθ_hat_arr + 1.96 * σθ_hat_arr
plt.hlines(θ, 1, n+1, ls='--', label='真实 $θ$')
plt.plot(range(1, n+1), μθ_hat_arr, color='b', label=r'$\hat{μ}_{θ}$')
plt.plot(range(1, n+1), μθ_hat_lower, color='b', ls='--')
plt.plot(range(1, n+1), μθ_hat_higher, color='b', ls='--')
plt.fill_between(range(1, n+1), μθ_hat_lower, μθ_hat_higher,
color='b', alpha=0.2, label='95%')
plt.xlabel('测试分数数量')
plt.ylabel('$\hat{θ}$')
plt.legend()
plt.show()
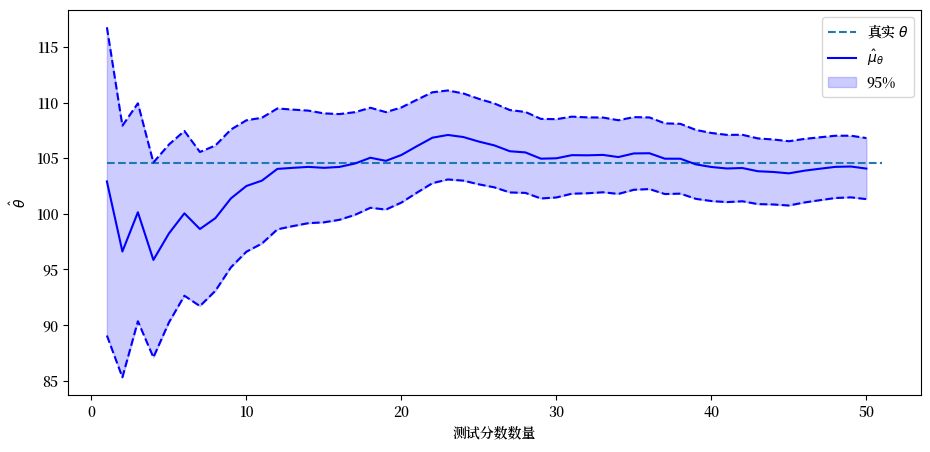
上图中的蓝色实线显示了 \(\hat{\mu}_{\theta}\) 作为我们已记录和条件化的测试分数数量的函数。
蓝色区域显示了从 \(\hat{\mu}_{\theta}\) 加上或减去 \(1.96 \hat{\sigma}_{\theta}\) 所得到的范围。
因此,条件分布的95%概率质量落在这个范围内。
黑色虚线显示了我们抽取的随机 \(\theta\) 的值。
随着越来越多的测试分数出现,我们对这个人的 \(\theta\) 的估计变得越来越可靠。
通过观察条件分布的变化,我们可以看到添加更多的测试分数使 \(\hat{\theta}\) 逐渐稳定并接近 \(\theta\)。
因此,每个 \(y_{i}\) 都提供了关于 \(\theta\) 的信息。
如果我们让测试次数 \(n \rightarrow + \infty\),条件标准差 \(\hat{\sigma}_{\theta}\) 将以 \(\frac{1}{n^{.5}}\) 的速率收敛到 \(0\)。
13.6. 信息即惊奇#
让我们通过使用不同的表示方法,从另一个角度来看这个问题。
我们可以将上述随机向量 \(X\) 表示为
其中\(C\)是\(\Sigma\)的下三角Cholesky因子,使得
且
因此可得
令 \(G=C^{-1}\)
\(G\) 也是下三角矩阵。
我们可以通过以下公式计算 \(\epsilon\)
这个公式证实了正交向量 \(\epsilon\) 包含了与非正交向量 \(\left( X - \mu_{\theta} \boldsymbol{1}_{n+1} \right)\) 相同的信息。
我们可以说 \(\epsilon\) 是 \(\left( X - \mu_{\theta} \boldsymbol{1}_{n+1} \right)\) 的一个正交基。
令 \(c_{i}\) 为 \(C\) 最后一行的第 \(i\) 个元素。
那么我们可以写作
\(\epsilon_i\) 之间的相互正交性为我们提供了一种有启发性的方式来解释方程 (13.1)。
因此,相对于从测试 \(i=1, \ldots, n-1\) 已知的信息而言,\(c_i \epsilon_i\) 是测试编号 \(i\) 带来的关于 \(\theta\) 的新信息量。
这里的新信息意味着惊喜或无法从先前信息预测的内容。
公式 (13.1) 还为我们提供了一种富有启发性的方式来表达我们之前计算的条件均值和条件方差。
具体来说,
和
C = np.linalg.cholesky(Σ_IQ)
G = np.linalg.inv(C)
ε = G @ (x - μθ)
cε = C[n, :] * ε
# 计算基于 y1, y2, ..., yk 的条件μθ和Σθ序列
μθ_hat_arr_C = np.array([np.sum(cε[:k+1]) for k in range(n)]) + μθ
Σθ_hat_arr_C = np.array([np.sum(C[n, i+1:n+1] ** 2) for i in range(n)])
为了确认这些公式给出的答案与我们之前计算的结果相同,我们可以将基于 \(\{y_i\}_{i=1}^k\) 条件下的 \(\theta\) 的均值和方差,与我们之前使用MultivariateNormal类(基于我们对多元正态分布条件分布的原始表示)实现的公式所得到的结果进行比较。
# 条件均值
np.max(np.abs(μθ_hat_arr - μθ_hat_arr_C)) < 1e-10
np.True_
# 条件方差
np.max(np.abs(Σθ_hat_arr - Σθ_hat_arr_C)) < 1e-10
np.True_
13.7. Cholesky因子魔法#
显然,Cholesky分解自动计算了我们的MultivariateNormal类所产生的总体回归系数和相关统计数据。
Cholesky分解递归地计算这些内容。
实际上,在公式(13.1)中,
随机变量 \(c_i \epsilon_i\) 包含了关于 \(\theta\) 的信息,这些信息不包含在 \(\epsilon_1, \epsilon_2, \ldots, \epsilon_{i-1}\) 的信息中
系数 \(c_i\) 是 \(\theta - \mu_\theta\) 对 \(\epsilon_i\) 的简单总体回归系数
13.8. 数学和语言智力#
我们可以修改前面的例子使其更加贴近现实。
有大量证据表明智商不是一个标量。
有些人数学能力强但语言能力差。
其他人语言能力强但数学能力差。
因此现在我们假设智商有两个维度,\(\theta\) 和 \(\eta\)。
这些分别决定了数学和语言测试的平均表现。
我们观察到数学分数 \(\{y_i\}_{i=1}^{n}\) 和语言分数 \(\{y_i\}_{i=n+1}^{2n}\)。
当 \(n=2\) 时,我们假设结果来自一个多元正态分布,其表示为
其中 \(w \begin{bmatrix} w_1 \cr w_2 \cr \vdots \cr w_6 \end{bmatrix}\) 是一个标准正态随机向量。
我们构建一个Python函数construct_moments_IQ2d来构造联合正态分布的均值向量和协方差矩阵。
def construct_moments_IQ2d(n, μθ, σθ, μη, ση, σy):
μ_IQ2d = np.empty(2*(n+1))
μ_IQ2d[:n] = μθ
μ_IQ2d[2*n] = μθ
μ_IQ2d[n:2*n] = μη
μ_IQ2d[2*n+1] = μη
D_IQ2d = np.zeros((2*(n+1), 2*(n+1)))
D_IQ2d[range(2*n), range(2*n)] = σy
D_IQ2d[:n, 2*n] = σθ
D_IQ2d[2*n, 2*n] = σθ
D_IQ2d[n:2*n, 2*n+1] = ση
D_IQ2d[2*n+1, 2*n+1] = ση
Σ_IQ2d = D_IQ2d @ D_IQ2d.T
return μ_IQ2d, Σ_IQ2d, D_IQ2d
我们让函数开始工作。
n = 2
# θ、η和y的均值和方差
μθ, σθ, μη, ση, σy = 100., 10., 100., 10, 10
μ_IQ2d, Σ_IQ2d, D_IQ2d = construct_moments_IQ2d(n, μθ, σθ, μη, ση, σy)
μ_IQ2d, Σ_IQ2d, D_IQ2d
(array([100., 100., 100., 100., 100., 100.]),
array([[200., 100., 0., 0., 100., 0.],
[100., 200., 0., 0., 100., 0.],
[ 0., 0., 200., 100., 0., 100.],
[ 0., 0., 100., 200., 0., 100.],
[100., 100., 0., 0., 100., 0.],
[ 0., 0., 100., 100., 0., 100.]]),
array([[10., 0., 0., 0., 10., 0.],
[ 0., 10., 0., 0., 10., 0.],
[ 0., 0., 10., 0., 0., 10.],
[ 0., 0., 0., 10., 0., 10.],
[ 0., 0., 0., 0., 10., 0.],
[ 0., 0., 0., 0., 0., 10.]]))
# 进行一次抽样
x = np.random.multivariate_normal(μ_IQ2d, Σ_IQ2d)
y1 = x[:n]
y2 = x[n:2*n]
θ = x[2*n]
η = x[2*n+1]
# 真实值
θ, η
(np.float64(95.84541184219867), np.float64(109.12503003062506))
我们首先计算 \(\left(\theta, \eta\right)\) 的联合正态分布。
multi_normal_IQ2d = MultivariateNormal(μ_IQ2d, Σ_IQ2d)
k = 2*n # 数据向量的长度
multi_normal_IQ2d.partition(k)
multi_normal_IQ2d.cond_dist(1, [*y1, *y2])
(array([106.68743472, 110.74995876]),
array([[33.33333333, 0. ],
[ 0. , 33.33333333]]))
现在让我们分别计算基于各种测试分数子集条件下的 \(\theta\) 和 \(\mu\) 的分布。
通过构建一个辅助函数 cond_dist_IQ2d,我们可以有趣地比较各种结果。
def cond_dist_IQ2d(μ, Σ, data):
n = len(μ)
multi_normal = MultivariateNormal(μ, Σ)
multi_normal.partition(n-1)
μ_hat, Σ_hat = multi_normal.cond_dist(1, data)
return μ_hat, Σ_hat
让我们看看这个例子是如何运行的。
for indices, IQ, conditions in [([*range(2*n), 2*n], 'θ', 'y1, y2, y3, y4'),
([*range(n), 2*n], 'θ', 'y1, y2'),
([*range(n, 2*n), 2*n], 'θ', 'y3, y4'),
([*range(2*n), 2*n+1], 'η', 'y1, y2, y3, y4'),
([*range(n), 2*n+1], 'η', 'y1, y2'),
([*range(n, 2*n), 2*n+1], 'η', 'y3, y4')]:
μ_hat, Σ_hat = cond_dist_IQ2d(μ_IQ2d[indices], Σ_IQ2d[indices][:, indices], x[indices[:-1]])
print(f'在{conditions: <15}条件下,{IQ}的均值和方差分别为' +
f'{μ_hat[0]:1.2f}和{Σ_hat[0, 0]:1.2f}')
在y1, y2, y3, y4 条件下,θ的均值和方差分别为106.69和33.33
在y1, y2 条件下,θ的均值和方差分别为106.69和33.33
在y3, y4 条件下,θ的均值和方差分别为100.00和100.00
在y1, y2, y3, y4 条件下,η的均值和方差分别为110.75和33.33
在y1, y2 条件下,η的均值和方差分别为100.00和100.00
在y3, y4 条件下,η的均值和方差分别为110.75和33.33
显然,数学考试不能提供关于 \(\mu\) 的信息,语言考试不能提供关于 \(\eta\) 的信息。
13.9. 单变量时间序列分析#
我们可以使用多元正态分布和一些矩阵代数来介绍单变量线性时间序列分析的基础。
设 \(x_t, y_t, v_t, w_{t+1}\) 对于 \(t \geq 0\) 均为标量。
考虑以下模型:
我们可以计算 \(x_{t}\) 的矩:
\(E x_{t+1}^2 = a^2 E x_{t}^2 + b^2, t \geq 0\),其中 \(E x_{0}^2 = \sigma_{0}^2\)
\(E x_{t+j} x_{t} = a^{j} E x_{t}^2, \forall t \ \forall j\)
给定某个 \(T\),我们可以将序列 \(\{x_{t}\}_{t=0}^T\) 表示为随机向量
协方差矩阵 \(\Sigma_{x}\) 可以用我们上面计算的矩来构建。
类似地,我们可以定义
因此
其中 \(C\) 和 \(D\) 都是对角矩阵,对角线上分别为常数 \(c\) 和 \(d\)。
因此,\(Y\) 的协方差矩阵为
通过将 \(X\) 和 \(Y\) 堆叠,我们可以写成
且
因此,堆叠序列 \(\{x_{t}\}_{t=0}^T\) 和 \(\{y_{t}\}_{t=0}^T\) 共同服从多元正态分布 \(N\left(0, \Sigma_{z}\right)\)。
# 作为示例,考虑 T = 3 的情况
T = 3
# 初始分布 x_0 的方差
σ0 = 1.
# 方程系统的参数
a = .9
b = 1.
c = 1.0
d = .05
# 构建 X 的协方差矩阵
Σx = np.empty((T+1, T+1))
Σx[0, 0] = σ0 ** 2
for i in range(T):
Σx[i, i+1:] = Σx[i, i] * a ** np.arange(1, T+1-i)
Σx[i+1:, i] = Σx[i, i+1:]
Σx[i+1, i+1] = a ** 2 * Σx[i, i] + b ** 2
Σx
array([[1. , 0.9 , 0.81 , 0.729 ],
[0.9 , 1.81 , 1.629 , 1.4661 ],
[0.81 , 1.629 , 2.4661 , 2.21949 ],
[0.729 , 1.4661 , 2.21949 , 2.997541]])
# 构建Y的协方差矩阵
C = np.eye(T+1) * c
D = np.eye(T+1) * d
Σy = C @ Σx @ C.T + D @ D.T
# 构建Z的协方差矩阵
Σz = np.empty((2*(T+1), 2*(T+1)))
Σz[:T+1, :T+1] = Σx
Σz[:T+1, T+1:] = Σx @ C.T
Σz[T+1:, :T+1] = C @ Σx
Σz[T+1:, T+1:] = Σy
Σz
array([[1. , 0.9 , 0.81 , 0.729 , 1. , 0.9 ,
0.81 , 0.729 ],
[0.9 , 1.81 , 1.629 , 1.4661 , 0.9 , 1.81 ,
1.629 , 1.4661 ],
[0.81 , 1.629 , 2.4661 , 2.21949 , 0.81 , 1.629 ,
2.4661 , 2.21949 ],
[0.729 , 1.4661 , 2.21949 , 2.997541, 0.729 , 1.4661 ,
2.21949 , 2.997541],
[1. , 0.9 , 0.81 , 0.729 , 1.0025 , 0.9 ,
0.81 , 0.729 ],
[0.9 , 1.81 , 1.629 , 1.4661 , 0.9 , 1.8125 ,
1.629 , 1.4661 ],
[0.81 , 1.629 , 2.4661 , 2.21949 , 0.81 , 1.629 ,
2.4686 , 2.21949 ],
[0.729 , 1.4661 , 2.21949 , 2.997541, 0.729 , 1.4661 ,
2.21949 , 3.000041]])
# 构建Z的均值向量
μz = np.zeros(2*(T+1))
以下 Python 代码让我们可以对随机向量 \(X\) 和 \(Y\) 进行采样。
这对于在下面有趣的练习中进行条件化处理将非常有用。
z = np.random.multivariate_normal(μz, Σz)
x = z[:T+1]
y = z[T+1:]
13.9.1. 平滑示例#
这是一个经典的平滑计算示例,其目的是计算 \(E X \mid Y\)。
这个示例的解释是:
\(X\) 是一个隐马尔可夫状态变量 \(x_t\) 的随机序列
\(Y\) 是一个包含隐藏状态信息的观测信号 \(y_t\) 序列
# 构建一个多元正态分布实例
multi_normal_ex1 = MultivariateNormal(μz, Σz)
x = z[:T+1]
y = z[T+1:]
# 将Z分割成X和Y
multi_normal_ex1.partition(T+1)
# 计算给定Y=y时X的条件均值和协方差矩阵
print("X = ", x)
print("Y = ", y)
print(" E [ X | Y] = ", )
multi_normal_ex1.cond_dist(0, y)
X = [-1.05658966 -0.89423666 -0.21642017 -0.52923678]
Y = [-1.07625436 -0.87850196 -0.18531493 -0.53035844]
E [ X | Y] =
(array([-1.07337143, -0.87736912, -0.18763125, -0.52945697]),
array([[2.48875094e-03, 5.57449314e-06, 1.24861718e-08, 2.80234724e-11],
[5.57449314e-06, 2.48876343e-03, 5.57452116e-06, 1.25113935e-08],
[1.24861718e-08, 5.57452116e-06, 2.48876346e-03, 5.58575339e-06],
[2.80233614e-11, 1.25113933e-08, 5.58575339e-06, 2.49377812e-03]]))
13.9.2. 滤波练习#
计算 \(E\left[x_{t} \mid y_{t-1}, y_{t-2}, \dots, y_{0}\right]\)。
为此,我们首先需要构建子向量 \(\left[x_{t}, y_{0}, \dots, y_{t-2}, y_{t-1}\right]\) 的均值向量和协方差矩阵。
例如,假设我们想要求 \(x_{3}\) 的条件分布。
t = 3
# 子向量的均值
sub_μz = np.zeros(t+1)
# 子向量的协方差矩阵
sub_Σz = np.empty((t+1, t+1))
sub_Σz[0, 0] = Σz[t, t] # x_t
sub_Σz[0, 1:] = Σz[t, T+1:T+t+1]
sub_Σz[1:, 0] = Σz[T+1:T+t+1, t]
sub_Σz[1:, 1:] = Σz[T+1:T+t+1, T+1:T+t+1]
sub_Σz
array([[2.997541, 0.729 , 1.4661 , 2.21949 ],
[0.729 , 1.0025 , 0.9 , 0.81 ],
[1.4661 , 0.9 , 1.8125 , 1.629 ],
[2.21949 , 0.81 , 1.629 , 2.4686 ]])
multi_normal_ex2 = MultivariateNormal(sub_μz, sub_Σz)
multi_normal_ex2.partition(1)
sub_y = y[:t]
multi_normal_ex2.cond_dist(0, sub_y)
(array([-0.16813975]), array([[1.00201996]]))
13.9.3. 预测练习#
计算 \(E\left[y_{t} \mid y_{t-j}, \dots, y_{0} \right]\)。
如同我们在练习2中所做的那样,我们将构建子向量 \(\left[y_{t}, y_{0}, \dots, y_{t-j-1}, y_{t-j} \right]\) 的均值向量和协方差矩阵。
例如,我们以 \(t=3\) 且 \(j=2\) 的情况为例。
t = 3
j = 2
sub_μz = np.zeros(t-j+2)
sub_Σz = np.empty((t-j+2, t-j+2))
sub_Σz[0, 0] = Σz[T+t+1, T+t+1]
sub_Σz[0, 1:] = Σz[T+t+1, T+1:T+t-j+2]
sub_Σz[1:, 0] = Σz[T+1:T+t-j+2, T+t+1]
sub_Σz[1:, 1:] = Σz[T+1:T+t-j+2, T+1:T+t-j+2]
sub_Σz
array([[3.000041, 0.729 , 1.4661 ],
[0.729 , 1.0025 , 0.9 ],
[1.4661 , 0.9 , 1.8125 ]])
multi_normal_ex3 = MultivariateNormal(sub_μz, sub_Σz)
multi_normal_ex3.partition(1)
sub_y = y[:t-j+1]
multi_normal_ex3.cond_dist(0, sub_y)
(array([-0.7117634]), array([[1.81413617]]))
13.9.4. 构建Wold表示#
现在我们将应用Cholesky分解来分解 \(\Sigma_{y}=H H^{\prime}\) 并形成
然后我们可以将 \(y_{t}\) 表示为
H = np.linalg.cholesky(Σy)
H
array([[1.00124922, 0. , 0. , 0. ],
[0.8988771 , 1.00225743, 0. , 0. ],
[0.80898939, 0.89978675, 1.00225743, 0. ],
[0.72809046, 0.80980808, 0.89978676, 1.00225743]])
ε = np.linalg.inv(H) @ y
ε
array([-1.07491156, 0.08751388, 0.60416942, -0.36140284])
y
array([-1.07625436, -0.87850196, -0.18531493, -0.53035844])
这个例子是时间序列分析中所谓的Wold表示的一个实例。
13.10. 随机差分方程#
考虑二阶线性随机差分方程
其中 \(u_{t} \sim N \left(0, \sigma_{u}^{2}\right)\) 且
它可以写成堆叠系统的形式
我们可以通过求解以下系统来计算 \(y\)
我们有
其中
# 设置参数
T = 80
T = 160
# 二阶差分方程的系数
𝛼0 = 10
𝛼1 = 1.53
𝛼2 = -.9
# u的方差
σu = 1.
σu = 10.
# y_{-1}和y_{0}的分布
μy_tilde = np.array([1., 0.5])
Σy_tilde = np.array([[2., 1.], [1., 0.5]])
# 构建 A 和 A^{\prime}
A = np.zeros((T, T))
for i in range(T):
A[i, i] = 1
if i-1 >= 0:
A[i, i-1] = -𝛼1
if i-2 >= 0:
A[i, i-2] = -𝛼2
A_inv = np.linalg.inv(A)
# 计算b和y的均值向量
μb = np.full(T, 𝛼0)
μb[0] += 𝛼1 * μy_tilde[1] + 𝛼2 * μy_tilde[0]
μb[1] += 𝛼2 * μy_tilde[1]
μy = A_inv @ μb
# 计算b和y的协方差矩阵
Σu = np.eye(T) * σu ** 2
Σb = np.zeros((T, T))
C = np.array([[𝛼2, 𝛼1], [0, 𝛼2]])
Σb[:2, :2] = C @ Σy_tilde @ C.T
Σy = A_inv @ (Σb + Σu) @ A_inv.T
13.11. 应用于股票价格模型#
令
构造
我们得到
β = .96
# 构建 B
B = np.zeros((T, T))
for i in range(T):
B[i, i:] = β ** np.arange(0, T-i)
记
因此,\(\{y_t\}_{t=1}^{T}\) 和 \(\{p_t\}_{t=1}^{T}\) 共同 服从多元正态分布 \(N \left(\mu_{z}, \Sigma_{z}\right)\),其中
D = np.vstack([np.eye(T), B])
μz = D @ μy
Σz = D @ Σy @ D.T
我们可以使用 MultivariateNormal 类来模拟 \(y_{t}\) 和 \(p_{t}\) 的路径,并计算条件期望 \(E \left[p_{t} \mid y_{t-1}, y_{t}\right]\)。
z = np.random.multivariate_normal(μz, Σz)
y, p = z[:T], z[T:]
cond_Ep = np.empty(T-1)
sub_μ = np.empty(3)
sub_Σ = np.empty((3, 3))
for t in range(2, T+1):
sub_μ[:] = μz[[t-2, t-1, T-1+t]]
sub_Σ[:, :] = Σz[[t-2, t-1, T-1+t], :][:, [t-2, t-1, T-1+t]]
multi_normal = MultivariateNormal(sub_μ, sub_Σ)
multi_normal.partition(2)
cond_Ep[t-2] = multi_normal.cond_dist(1, y[t-2:t])[0][0]
plt.plot(range(1, T), y[1:], label='$y_{t}$')
plt.plot(range(1, T), y[:-1], label='$y_{t-1}$')
plt.plot(range(1, T), p[1:], label='$p_{t}$')
plt.plot(range(1, T), cond_Ep, label='$Ep_{t}|y_{t}, y_{t-1}$')
plt.xlabel('t')
plt.legend(loc=1)
plt.show()
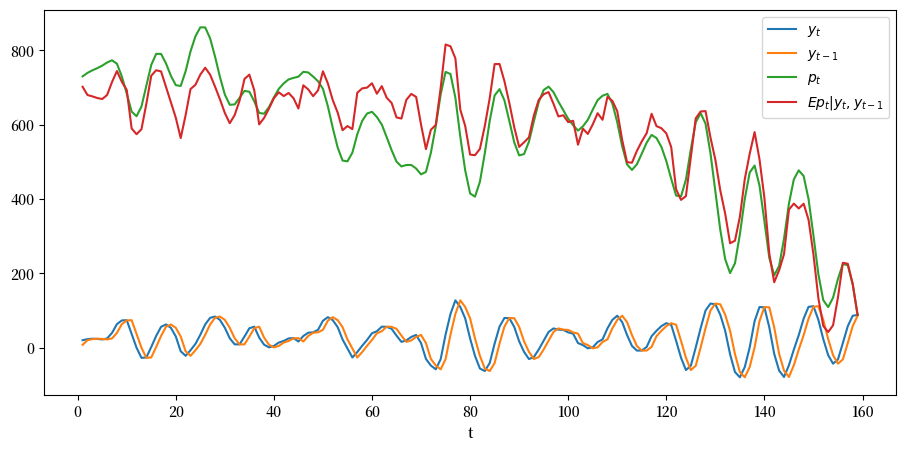
在上图中,绿线表示如果人们对股息路径有完美预见时的股票价格,而绿线表示条件期望 \(E p_t | y_t, y_{t-1}\),这是在人们没有完美预见但基于时间 \(t\) 的信息 \(y_t, y_{t-1}\) 对未来股息进行最优预测时的股票价格。
13.12. 滤波基础#
假设 \(x_0\) 是一个 \(n \times 1\) 随机向量,且 \(y_0\) 是一个由以下观测方程决定的 \(p \times 1\) 随机向量
其中 \(v_0\) 与 \(x_0\) 正交,\(G\) 是一个 \(p \times n\) 矩阵,且 \(R\) 是一个 \(p \times p\) 正定矩阵。
我们考虑这样一个人的问题,他:
观察到 \(y_0\)
没有观察到 \(x_0\)
已知 \(\hat x_0, \Sigma_0, G, R\) 以及向量 \(\begin{bmatrix} x_0 \cr y_0 \end{bmatrix}\) 的联合概率分布
想要根据他所知道的联合概率分布,从 \(y_0\) 推断 \(x_0\)。
因此,这个人想要构建基于随机向量 \(y_0\) 的 \(x_0\) 的条件概率分布。
\(\begin{bmatrix} x_0 \cr y_0 \end{bmatrix}\) 的联合分布是多元正态分布 \({\mathcal N}(\mu, \Sigma)\),其中
通过适当应用上述关于 \(z_1\) 在给定 \(z_2\) 条件下的均值向量 \(\hat \mu_1\) 和协方差矩阵 \(\hat \Sigma_{11}\) 的公式,我们发现 \(x_0\) 在给定 \(y_0\) 条件下的概率分布是 \({\mathcal N}(\tilde x_0, \tilde \Sigma_0)\),其中
我们可以通过将 \(x_0\) 表示为以下形式来表达 \(x_0\) 在 \(y_0\) 条件下的概率分布为 \({\mathcal N}(\tilde x_0, \tilde \Sigma_0)\):
其中\(\zeta_0\)是一个高斯随机向量,它与 \(\tilde x_0\) 和 \(y_0\) 正交,并且具有均值向量 \(0\) 和条件协方差矩阵 \(E [\zeta_0 \zeta_0' | y_0] = \tilde \Sigma_0\)。
13.12.1. 迈向动态分析#
现在假设我们处在时间序列环境中,并且有一步状态转移方程:
其中 \(A\) 是一个 \(n \times n\) 矩阵,\(C\) 是一个 \(n \times m\) 矩阵。
使用方程(13.2),我们也可以将 \(x_1\) 表示为
由此可得
相应的条件协方差矩阵 \(E (x_1 - E x_1| y_0) (x_1 - E x_1| y_0)' \equiv \Sigma_1\) 为
或
我们可以将 \(x_1\) 在 \(y_0\) 条件下的均值写作
或
其中
13.12.2. 动态版本#
现在假设对于 \(t \geq 0\), \(\{x_{t+1}, y_t\}_{t=0}^\infty\) 由以下方程支配
其中如前所述 \(x_0 \sim {\mathcal N}(\hat x_0, \Sigma_0)\), \(w_{t+1}\) 是独立同分布随机过程的第 \(t+1\) 个分量
过程 \(w_{t+1}\) 服从分布 \(w_{t+1} \sim {\mathcal N}(0, I)\),而 \(v_t\) 是独立同分布过程的第 \(t\) 个分量, 服从分布 \(v_t \sim {\mathcal N}(0, R)\),且 \(\{w_{t+1}\}_{t=0}^\infty\) 和 \(\{v_t\}_{t=0}^\infty\) 这两个过程在任意时间点对上都是正交的。
我们上面应用的逻辑和公式表明,在给定 \(y_0, y_1, \ldots , y_{t-1} = y^{t-1}\) 条件下,\(x_t\) 的概率分布为
其中 \(\{\tilde x_t, \tilde \Sigma_t\}_{t=1}^\infty\) 可以 通过从 \(t=1\) 开始迭代以下方程计算得到, 初始条件 \(\tilde x_0, \tilde \Sigma_0\) 按照我们上面的方法计算:
如果我们将第一个方程向前移动一个周期,然后将第五个方程右侧的\(\tilde \Sigma_t\)表达式代入其中,我们得到
这是一个矩阵黎卡提差分方程,它与出现在线性二次控制理论基础的quantecon讲座中的另一个矩阵黎卡提差分方程密切相关。
那个方程的形式为
请仔细观察前面这两个方程片刻,第一个是条件协方差矩阵的矩阵差分方程,第二个是出现在跨期成本值函数二次型中的矩阵的矩阵差分方程。
尽管这两个方程并不完全相同,但它们展现出显著的家族相似性。
第一个方程描述了向前推进的动态过程
第二个方程描述了向后推进的动态过程
虽然许多项都很相似,但一个方程似乎对在另一个方程中扮演相似角色的矩阵进行矩阵变换
这两个方程的家族相似性反映了控制理论和滤波理论之间存在的超越性对偶关系。
13.12.3. 一个例子#
我们可以使用Python类 MultivariateNormal 来构建示例。
这是一个时间为 \(0\) 的单期问题示例
G = np.array([[1., 3.]])
R = np.array([[1.]])
x0_hat = np.array([0., 1.])
Σ0 = np.array([[1., .5], [.3, 2.]])
μ = np.hstack([x0_hat, G @ x0_hat])
Σ = np.block([[Σ0, Σ0 @ G.T], [G @ Σ0, G @ Σ0 @ G.T + R]])
# 构建多元正态分布实例
multi_normal = MultivariateNormal(μ, Σ)
multi_normal.partition(2)
# y的观测值
y0 = 2.3
# x0的条件分布
μ1_hat, Σ11 = multi_normal.cond_dist(0, y0)
μ1_hat, Σ11
(array([-0.078125, 0.803125]),
array([[ 0.72098214, -0.203125 ],
[-0.403125 , 0.228125 ]]))
A = np.array([[0.5, 0.2], [-0.1, 0.3]])
C = np.array([[2.], [1.]])
# x1的条件分布
x1_cond = A @ μ1_hat
Σ1_cond = C @ C.T + A @ Σ11 @ A.T
x1_cond, Σ1_cond
(array([0.1215625, 0.24875 ]),
array([[4.12874554, 1.95523214],
[1.92123214, 1.04592857]]))
13.12.4. 迭代代码#
以下是通过迭代方程来解决动态滤波问题的代码,并附有示例。
def iterate(x0_hat, Σ0, A, C, G, R, y_seq):
p, n = G.shape
T = len(y_seq)
x_hat_seq = np.empty((T+1, n))
Σ_hat_seq = np.empty((T+1, n, n))
x_hat_seq[0] = x0_hat
Σ_hat_seq[0] = Σ0
for t in range(T):
xt_hat = x_hat_seq[t]
Σt = Σ_hat_seq[t]
μ = np.hstack([xt_hat, G @ xt_hat])
Σ = np.block([[Σt, Σt @ G.T], [G @ Σt, G @ Σt @ G.T + R]])
# 滤波
multi_normal = MultivariateNormal(μ, Σ)
multi_normal.partition(n)
x_tilde, Σ_tilde = multi_normal.cond_dist(0, y_seq[t])
# 预测
x_hat_seq[t+1] = A @ x_tilde
Σ_hat_seq[t+1] = C @ C.T + A @ Σ_tilde @ A.T
return x_hat_seq, Σ_hat_seq
iterate(x0_hat, Σ0, A, C, G, R, [2.3, 1.2, 3.2])
(array([[0. , 1. ],
[0.1215625 , 0.24875 ],
[0.18680212, 0.06904689],
[0.75576875, 0.05558463]]),
array([[[1. , 0.5 ],
[0.3 , 2. ]],
[[4.12874554, 1.95523214],
[1.92123214, 1.04592857]],
[[4.08198663, 1.99218488],
[1.98640488, 1.00886423]],
[[4.06457628, 2.00041999],
[1.99943739, 1.00275526]]]))
刚才描述的迭代算法是著名的卡尔曼滤波器的一个版本。
我们在卡尔曼滤波器初探中描述了卡尔曼滤波器及其一些应用。
13.13. 经典因子分析模型#
在心理学和其他领域广泛使用的因子分析模型可以表示为:
其中:
\(Y\) 是 \(n \times 1\) 随机向量, \(E U U^{\prime} = D\) 是一个对角矩阵,
\(\Lambda\) 是 \(n \times k\) 系数矩阵,
\(f\) 是 \(k \times 1\) 随机向量, \(E f f^{\prime} = I\),
\(U\) 是 \(n \times 1\) 随机向量,且 \(U \perp f\)(即 \(E U f' = 0\))
假设 \(k\) 相对于 \(n\) 较小;通常 \(k\) 只有 \(1\) 或 \(2\),就像我们的智商示例中那样。
这意味着:
因此,协方差矩阵 \(\Sigma_Y\) 是一个对角矩阵 \(D\) 和一个秩为 \(k\) 的半正定矩阵 \(\Lambda \Lambda^{\prime}\) 的和。
这意味着 \(Y\) 向量的 \(n\) 个分量之间的所有协方差都是通过它们与 \(k<n\) 个因子的共同依赖关系来中介的。
构造
扩展随机向量 \(Z\) 的协方差矩阵可以计算为
接下来,我们首先构造 \(N=10\) 和 \(k=2\) 情况下的均值向量和协方差矩阵。
N = 10
k = 2
我们设定系数矩阵 \(\Lambda\) 和 \(U\) 的协方差矩阵为
其中 \(\Lambda\) 的第一列前半部分填充为 \(1\),后半部分为 \(0\),第二列则相反。
\(D\) 是一个对角矩阵,对角线上的元素为参数 \(\sigma_{u}^{2}\)。
Λ = np.zeros((N, k))
Λ[:N//2, 0] = 1
Λ[N//2:, 1] = 1
σu = .5
D = np.eye(N) * σu ** 2
# 计算 Σy
Σy = Λ @ Λ.T + D
我们现在可以构建 \(Z\) 的均值向量和协方差矩阵。
μz = np.zeros(k+N)
Σz = np.empty((k+N, k+N))
Σz[:k, :k] = np.eye(k)
Σz[:k, k:] = Λ.T
Σz[k:, :k] = Λ
Σz[k:, k:] = Σy
z = np.random.multivariate_normal(μz, Σz)
f = z[:k]
y = z[k:]
multi_normal_factor = MultivariateNormal(μz, Σz)
multi_normal_factor.partition(k)
让我们计算隐藏因子 \(f\) 在观测值 \(Y\) 上的条件分布,即 \(f \mid Y=y\)。
multi_normal_factor.cond_dist(0, y)
(array([1.3988848 , 1.95750545]),
array([[0.04761905, 0. ],
[0. , 0.04761905]]))
我们可以验证条件期望 \(E \left[f \mid Y=y\right] = B Y\), 其中 \(B = \Lambda^{\prime} \Sigma_{y}^{-1}\)。
B = Λ.T @ np.linalg.inv(Σy)
B @ y
array([1.3988848 , 1.95750545])
类似地,我们可以计算条件分布 \(Y \mid f\)。
multi_normal_factor.cond_dist(1, f)
(array([1.12746316, 1.12746316, 1.12746316, 1.12746316, 1.12746316,
1.9735181 , 1.9735181 , 1.9735181 , 1.9735181 , 1.9735181 ]),
array([[0.25, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ],
[0. , 0.25, 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0.25, 0. , 0. , 0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0.25, 0. , 0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0.25, 0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. , 0.25, 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. , 0. , 0.25, 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.25, 0. , 0. ],
[0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.25, 0. ],
[0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0.25]]))
可以验证该均值为 \(\Lambda I^{-1} f = \Lambda f\)。
Λ @ f
array([1.12746316, 1.12746316, 1.12746316, 1.12746316, 1.12746316,
1.9735181 , 1.9735181 , 1.9735181 , 1.9735181 , 1.9735181 ])
13.14. PCA和因子分析#
要了解主成分分析(PCA),请参阅本讲座奇异值分解。
让我们来做个有趣的练习,对实际上由我们的因子分析模型支配的协方差矩阵 \(\Sigma_y\) 进行PCA分解。
从技术上讲,这意味着PCA模型是错误设定的。(你能解释为什么吗?)
尽管如此,这个练习将让我们研究PCA的前两个主成分如何近似我们假设真实支配Y数据的因子分析模型中两个因子 \(f_i\) (\(i=1,2\))的条件期望 \(E f_i | Y\)。
因此我们计算PCA分解
其中 \(\tilde{\Lambda}\) 是一个对角矩阵。
我们有
和
注意,我们将按特征值降序排列 \(P\) 中的特征向量。
𝜆_tilde, P = np.linalg.eigh(Σy)
# 按特征值排列特征向量
ind = sorted(range(N), key=lambda x: 𝜆_tilde[x], reverse=True)
P = P[:, ind]
𝜆_tilde = 𝜆_tilde[ind]
Λ_tilde = np.diag(𝜆_tilde)
print('𝜆_tilde =', 𝜆_tilde)
𝜆_tilde = [5.25 5.25 0.25 0.25 0.25 0.25 0.25 0.25 0.25 0.25]
# 验证特征向量的正交性
np.abs(P @ P.T - np.eye(N)).max()
np.float64(8.881784197001252e-16)
# 验证特征值分解是否正确
P @ Λ_tilde @ P.T
array([[1.25, 1. , 1. , 1. , 1. , 0. , 0. , 0. , 0. , 0. ],
[1. , 1.25, 1. , 1. , 1. , 0. , 0. , 0. , 0. , 0. ],
[1. , 1. , 1.25, 1. , 1. , 0. , 0. , 0. , 0. , 0. ],
[1. , 1. , 1. , 1.25, 1. , 0. , 0. , 0. , 0. , 0. ],
[1. , 1. , 1. , 1. , 1.25, 0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. , 1.25, 1. , 1. , 1. , 1. ],
[0. , 0. , 0. , 0. , 0. , 1. , 1.25, 1. , 1. , 1. ],
[0. , 0. , 0. , 0. , 0. , 1. , 1. , 1.25, 1. , 1. ],
[0. , 0. , 0. , 0. , 0. , 1. , 1. , 1. , 1.25, 1. ],
[0. , 0. , 0. , 0. , 0. , 1. , 1. , 1. , 1. , 1.25]])
ε = P.T @ y
print("ε = ", ε)
ε = [ 4.59597101 3.28440158 -0.48215927 -0.08783363 0.16894719 -0.77034464
0.44493959 -0.18817693 -0.09929539 0.58865147]
# 打印两个因子的值
print('f = ', f)
f = [1.12746316 1.9735181 ]
下面我们将绘制几个图:
\(N\) 个 \(y\) 值
\(N\) 个主成分 \(\epsilon\) 值
第一个因子 \(f_1\) 的值,仅绘制前 \(N/2\) 个在 \(\Lambda\) 中具有非零载荷的 \(y\) 观测值
第二个因子 \(f_2\) 的值,仅绘制最后 \(N/2\) 个在 \(\Lambda\) 中具有非零载荷的观测值
plt.scatter(range(N), y, label='y')
plt.scatter(range(N), ε, label='$\epsilon$')
plt.hlines(f[0], 0, N//2-1, ls='--', label='$f_{1}$')
plt.hlines(f[1], N//2, N-1, ls='-.', label='$f_{2}$')
plt.legend()
plt.show()
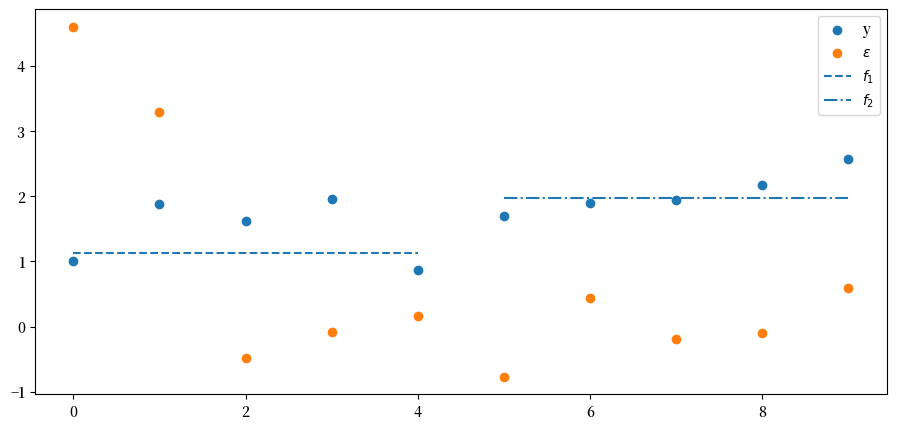
因此,前两个 \(\epsilon_{j}\) 对应于最大的两个特征值。
让我们来看看它们,之后我们将查看 \(E f | y = B y\)
ε[:2]
array([4.59597101, 3.28440158])
# 与 Ef|y 比较
B @ y
array([1.3988848 , 1.95750545])
\(y_{t}\) 中由前两个主成分解释的方差比例可以按如下方式计算。
𝜆_tilde[:2].sum() / 𝜆_tilde.sum()
np.float64(0.8400000000000001)
计算
其中 \(P_{j}\) 和 \(P_{k}\) 对应最大的两个特征值。
y_hat = P[:, :2] @ ε[:2]
在这个例子中,\(Y\) 在前两个主成分上的投影 \(\hat{Y}\) 很好地近似了 \(Ef \mid y\)。
我们通过下面的图来确认这一点,图中展示了 \(f\)、\(E y \mid f\)、\(E f \mid y\) 和 \(\hat{y}\)(在坐标轴上)与 \(y\)(在纵轴上)的关系。
plt.scatter(range(N), Λ @ f, label='$Ey|f$')
plt.scatter(range(N), y_hat, label=r'$\hat{y}$')
plt.hlines(f[0], 0, N//2-1, ls='--', label='$f_{1}$')
plt.hlines(f[1], N//2, N-1, ls='-.', label='$f_{2}$')
Efy = B @ y
plt.hlines(Efy[0], 0, N//2-1, ls='--', color='b', label='$Ef_{1}|y$')
plt.hlines(Efy[1], N//2, N-1, ls='-.', color='b', label='$Ef_{2}|y$')
plt.legend()
plt.show()
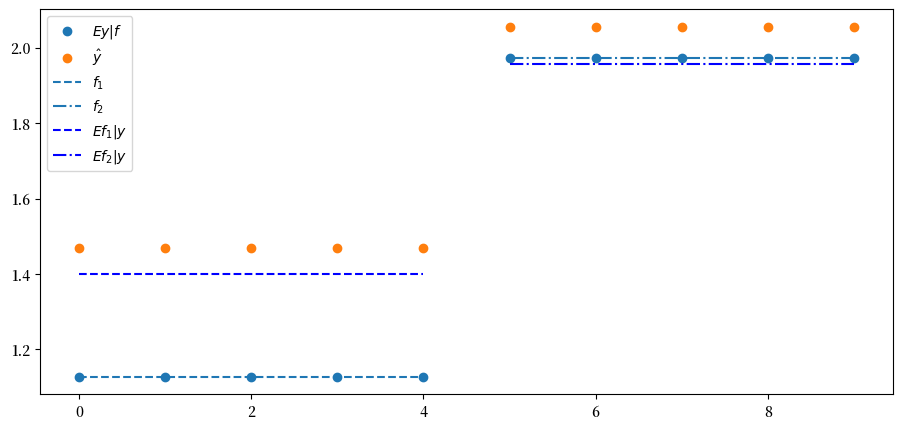
\(\hat{Y}\) 的协方差矩阵可以通过先构建 \(\epsilon\) 的协方差矩阵,然后使用 \(\epsilon_{1}\) 和 \(\epsilon_{2}\) 的左上角块来计算。
Σεjk = (P.T @ Σy @ P)[:2, :2]
Pjk = P[:, :2]
Σy_hat = Pjk @ Σεjk @ Pjk.T
print('Σy_hat = \n', Σy_hat)
Σy_hat =
[[1.05 1.05 1.05 1.05 1.05 0. 0. 0. 0. 0. ]
[1.05 1.05 1.05 1.05 1.05 0. 0. 0. 0. 0. ]
[1.05 1.05 1.05 1.05 1.05 0. 0. 0. 0. 0. ]
[1.05 1.05 1.05 1.05 1.05 0. 0. 0. 0. 0. ]
[1.05 1.05 1.05 1.05 1.05 0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 1.05 1.05 1.05 1.05 1.05]
[0. 0. 0. 0. 0. 1.05 1.05 1.05 1.05 1.05]
[0. 0. 0. 0. 0. 1.05 1.05 1.05 1.05 1.05]
[0. 0. 0. 0. 0. 1.05 1.05 1.05 1.05 1.05]
[0. 0. 0. 0. 0. 1.05 1.05 1.05 1.05 1.05]]