55. 吃蛋糕问题 I:最优储蓄导论#
55.1. 概述#
在本讲中,我们介绍一个简单的“吃蛋糕”问题。
这里的跨期问题是:今天要享受多少,为未来留下多少?
尽管这个主题听起来很平凡,但这种“当前效用与未来效用的权衡”正是许多储蓄与消费问题的核心。
一旦我们在这个简单环境中掌握了相关思想,我们就会逐步把它们应用到更具挑战性——也更有用——的问题中。
我们用来解决吃蛋糕问题的主要工具是动态规划。
在阅读本讲之前,读者可能会发现复习以下讲座会有帮助:
在接下来的内容中,我们需要导入以下模块:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
import numpy as np
55.2. 模型#
我们考虑一个无限期的时间区间 \(t=0, 1, 2, 3...\)
在 \(t=0\) 时,决策者获得一个大小为 \(\bar x\) 的完整蛋糕。
令 \(x_t\) 表示每一期开始时的蛋糕大小。特别地,\(x_0 = \bar{x}\)。
我们选择在任何给定时期 \(t\) 吃掉多少蛋糕。
如果在第 \(t\) 期选择消费 \(c_t\) 单位的蛋糕,那么在第 \(t+1\) 期剩余的蛋糕量为
消费数量为 \(c\) 的蛋糕会带来当期效用 \(u(c)\)。
我们采用CRRA效用函数
在 Python 中表示为:
def u(c, γ):
return c**(1 - γ) / (1 - γ)
未来的蛋糕消费效用按照折现因子 \(\beta \in (0,1)\) 进行折现。
具体来说,\(t\) 期后的 \(c\) 单位消费的现值是 \(\beta^t u(c)\)。
决策者的问题可以写作
约束条件为,对所有 \(t\),
一个满足(55.3)的消费路径 \({c_t}\)(其中 \(x_0 = \bar{x}\))被称为可行的。
在这个问题中,以下术语是标准的:
\(x_t\) 被称为状态变量
\(c_t\) 被称为控制变量或行动
\(\beta\) 和 \(\gamma\) 是参数
55.2.1. 权衡#
吃蛋糕问题中的关键权衡是:
推迟消费是有代价的,因为存在折现因子。
但推迟部分消费也具有吸引力,因为效用函数 \(u\) 是凹的。
\(u\) 的凹性意味着消费平滑,即将消费分散在不同时期,给消费者带来价值。
这是因为凹性意味着边际效用递减——在同一时期内,每多消费一勺蛋糕所带来的效用增加会逐渐减少。
55.2.2. 直观理解#
上述推理表明,贴现因子 \(\beta\) 和曲率参数 \(\gamma\) 在决定消费率时将起到关键作用。
我们可以合理猜测这些参数的影响:
首先,较高的 \(\beta\) 意味着较少的折现,因此个体更有耐心,这应该会降低消费率。
其次,较高的 \(\gamma\) 意味着边际效用 \(u'(c) = c^{-\gamma}\) 随着 \(c\) 的增加下降得更快。这意味着会有更多的消费平滑,因此消费率会更低。
总之,我们预期消费率会随着这两个参数的增加而减少。
让我们看看这是否正确。
55.3. 价值函数#
我们动态规划处理的第一步是得到贝尔曼方程。
下一步是使用它来计算解。
55.3.1. 贝尔曼方程#
为此,我们令 \(v(x)\) 表示当剩余 \(x\) 单位蛋糕时,从当前时刻起可获得的最大终身效用。
即,
其中最大化是针对从 \(x_0 = x\) 开始所有可行的路径 \(\{ c_t \}\)。
此时,我们还没有 \(v\) 的表达式,但我们仍然可以对它进行推断。
例如,就像在McCall模型中一样,价值函数将满足某种形式的贝尔曼方程。
在当前情形下,该方程表明 \(v\) 满足
这里的直观理解本质上与McCall模型相同。
最优地选择 \(c\) 意味着要在当前和未来回报之间进行权衡。
选择 \(c\) 带来的当前回报就是 \(u(c)\)。
在当前蛋糕大小为 \(x\) 的情况下,假设采取最优行为,从下一期开始计算的未来回报是 \(v(x-c)\)。
经过适当的折现之后,这两项就是 (55.5) 右边的两项。
如果使用这种权衡策略最优地选择 \(c\),那么我们就能从当前状态 \(x\) 获得最大的终身回报。
因此,正如我们声称的,\(v(x)\) 等于 (55.5) 的右边。
55.3.2. 一个解析解#
已经证明,当 \(u\) 是 (55.1) 中的 CRRA 效用函数时,函数
是贝尔曼方程的解,因此等于价值函数。
在下面的练习中,你需要验证这一点。
解 (55.6) 严重依赖于 CRRA 效用函数。
事实上,如果我们不使用CRRA效用函数,通常就完全没有解析解。
换句话说,在CRRA效用函数之外,我们知道价值函数仍然满足贝尔曼方程,但我们无法显式地写出它,作为状态变量和参数的函数。
在那种情况下,我们会在需要时通过数值方法来处理。
下面是价值函数的一个 Python 表示:
def v_star(x, β, γ):
return (1 - β**(1 / γ))**(-γ) * u(x, γ)
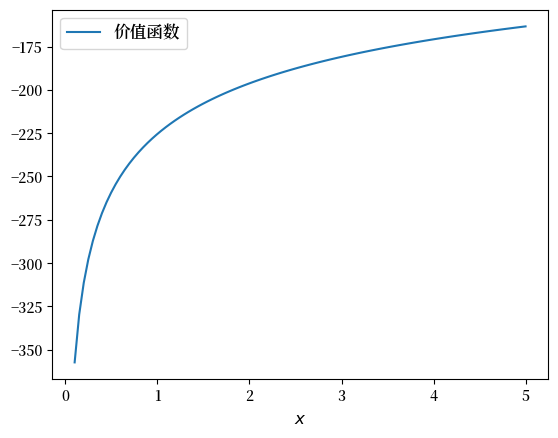
下面的图,展示了在固定参数下该函数的形状:
β, γ = 0.95, 1.2
x_grid = np.linspace(0.1, 5, 100)
fig, ax = plt.subplots()
ax.plot(x_grid, v_star(x_grid, β, γ), label='价值函数')
ax.set_xlabel('$x$', fontsize=12)
ax.legend(fontsize=12)
plt.show()
55.4. 最优策略#
既然我们已经得到了价值函数,那么在每个状态下计算最优行动就很直接了。
我们应该选择一个消费水平,使得贝尔曼方程(55.5)的右侧最大化:
我们可以将这个最优选择视为状态 \(x\) 的函数,此时称之为最优策略 (optimal policy)。
我们用 \(\sigma^*\) 表示最优策略,因此
如果我们将价值函数的解析表达式(55.6)代入右侧并计算最优值,可以得到
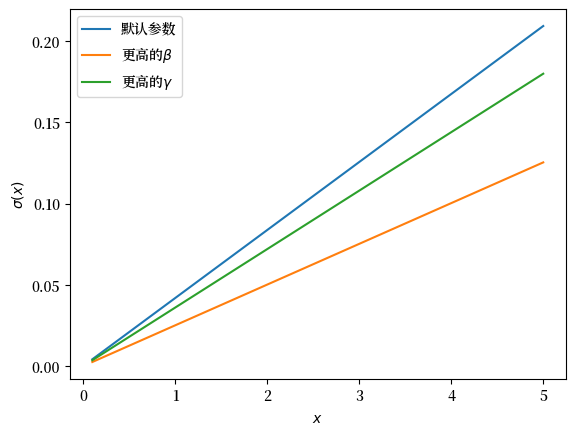
现在让我们回顾一下关于参数影响的直觉。
我们之前猜测,消费率会随着这两个参数的增加而减少。
从(55.7)可以看出,事实确实如此。 这里有一些图表来说明。
def c_star(x, β, γ):
return (1 - β ** (1/γ)) * x
继续使用前面给定的参数 \(\beta\) 和 \(\gamma\),绘制出的图形如下:
fig, ax = plt.subplots()
ax.plot(x_grid, c_star(x_grid, β, γ), label='默认参数')
ax.plot(x_grid, c_star(x_grid, β + 0.02, γ), label=r'更高的$\beta$')
ax.plot(x_grid, c_star(x_grid, β, γ + 0.2), label=r'更高的$\gamma$')
ax.set_ylabel(r'$\sigma(x)$')
ax.set_xlabel('$x$')
ax.legend()
plt.show()
55.5. 欧拉方程#
在上面的讨论中,我们已经在 CRRA 效用的情形下给出了吃蛋糕问题的完整解。
事实上,还有另一种方法可以求解最优策略,即基于所谓的欧拉方程(Euler equation)。
尽管我们已经得到了完整解,但现在正是研究欧拉方程的好时机。
这是因为,对于更复杂的问题,这个方程能够提供一些通过其他方法难以获得的关键洞见。
55.5.1. 陈述和含义#
当前问题的欧拉方程可以表述为
这是最优路径的必要条件。
它表明,在最优路径上,经过适当折现之后,跨期边际收益是相等的。
这很合理:最优性是通过平滑消费直到没有额外的边际收益为止得到的。
我们也可以用策略函数来表述欧拉方程。 可行消费策略是一个满足 \(0 \leq \sigma(x) \leq x\) 的映射 \(x \mapsto \sigma(x)\)。
这里的约束条件表明,我们不能消费超过剩余蛋糕的数量。
如果一个可行消费策略 \(\sigma\) 对于所有 \(x > 0\) 满足以下条件,则称其满足欧拉方程:
事实证明,一个可行策略当且仅当满足欧拉方程时才是最优的。
在练习中,你需要验证最优策略(55.7)确实满足这个泛函方程。
备注
泛函方程是一个未知对象为函数的方程。
关于欧拉方程在更一般情况下充分性的证明,请参见[Ma et al., 2020]中的命题2.2。
下面的论证将聚焦于必要性,解释为什么任何最优路径或最优策略都必须满足欧拉方程。S
55.5.2. 推导 I:扰动法#
我们把 \(c\) 作为消费路径 \(\left\{{c_t}\right\}_{t=0}^\infty\) 的简写。
整个吃蛋糕的最大化问题可以写作
其中 \(F\) 是所有可行消费路径的集合。
我们知道,可微函数在极大值点的梯度为零。
因此最优路径 \(c^* := \{c^*_t\}_{t=0}^\infty\) 必须满足 \(U'(c^*) = 0\)。
备注
如果你想确切了解导数 \(U'(c^*)\) 是如何定义的,考虑到参自变量 \(c^*\) 是一个无限长的向量,你可以从学习加托导数开始。不过,下文并不假定需要这些知识。
换句话说,对于任何无穷小的(且可行的)偏离最优路径的扰动,\(U\) 的变化率必须为零。
因此,考虑这样一个可行的扰动:在 \(t\) 期把消费减少为 \(c_t^* - h\),并在下一期把消费增加为 \(c_{t+1}^* + h\)。
在其他时期消费不发生变化。
我们称这种扰动路径为 \(c^h\)。
根据前面关于零梯度的论证,我们有
注意到消费只在 \(t\) 和 \(t+1\) 时刻发生变化,上式可以写为
经过整理,相同的式子可以写作
或者,取极限后得到
这就是欧拉方程。
55.5.3. 推导 II:使用贝尔曼方程#
另一种推导欧拉方程的方法是使用贝尔曼方程(55.5)。
对贝尔曼方程右侧关于 \(c\) 求导并令其等于零,我们得到
为了得到 \(v^{\prime}(x - c)\),我们设 \(g(c,x) = u(c) + \beta v(x - c)\),这样,在最优消费选择下,
对等式两边求导,同时考虑到最优消费会依赖于 \(x\),我们得到
当 \(g(c,x)\) 在 \(c\) 处取得最大值时,我们有 \(\frac{\partial }{\partial c} g(c,x) = 0\)。
因此导数简化为
(这个推导是包络定理的一个例子。)
结合(55.10)得到
因此,价值函数的导数等于边际效用。
将这一事实与(55.12)结合,就可以得到欧拉方程。
55.6. 练习#
练习 55.1
如何得到(55.6)和(55.7)中给出的价值函数和最优策略的表达式?
第一步是对消费策略的函数形式作一个猜测。
假设我们不知道解,并从一个假设出发:最优策略是线性的。
换句话说,我们猜测存在一个正的 \(\theta\),使得令使得对所有 \(t\),设定\(c_t^*=\theta x_t\)会产生一个最优路径。
从这个猜想出发,尝试获得解 (55.6) 和 (55.7)。
在此过程中,你需要使用价值函数的定义和贝尔曼方程。
解答 练习 55.1
我们从猜想 \(c_t^*=\theta x_t\) 开始,这会导致状态变量(蛋糕大小)的路径为
那么 \(x_t = x_{0}(1-\theta)^t\),因此
从贝尔曼方程可得,
根据一阶条件,我们得到
或
代入 \(c = \theta x\) 我们得到
经过一些整理得到
这证实了我们之前得到的最优策略表达式:
将 \(\theta\) 代入上面的价值函数得到
重新整理得到
我们的论述现已得到验证。