35. 库存动态#
35.1. 概述#
在本讲座中,我们将研究企业的库存时间路径,其遵循所谓的s-S库存动态。
这些企业遵循以下补货规则:
当库存水平下降至某个临界值\(s\)以下时,
企业会订购足够数量的产品,将库存补充到目标水平\(S\)。
这种管理库存的方式在实践中很常见,并且在某些情况下也是最优的。
早期文献和其对宏观经济的影响可以在[Caplin, 1985]中找到。
我们的本节的目标是学习更多关于模拟、时间序列和马尔可夫动态的知识。
尽管我们的马尔可夫环境和涉及的概念与有限马尔可夫链讲座的概念是相关的,但在当前应用中状态空间是连续的。
让我们从导入一些库开始
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5) #设置默认图形大小
import numpy as np
from numba import jit, float64, prange
from numba.experimental import jitclass
35.2. 样本路径#
假设有一个公司,拥有库存 \(X_t\)。
当库存 \(X_t \leq s\) 时,公司会补货至 \(S\) 单位。
公司面临随机需求 \(\{ D_t \}\),我们假设这是独立同分布的。
使用符号 \(a^+ := \max\{a, 0\}\),库存动态可以写作
在下文中,我们将假设每个 \(D_t\) 都是对数正态分布的,即
其中 \(\mu\) 和 \(\sigma\) 是参数,\(\{Z_t\}\) 是独立同分布的标准正态分布。
下面是一个类,它用于存储参数并生成库存的时间路径。
firm_data = [
('s', float64), # 触发补货水平
('S', float64), # 库存总容量
('mu', float64), # 冲击位置参数
('sigma', float64) # 冲击规模参数
]
@jitclass(firm_data)
class Firm:
def __init__(self, s=10, S=100, mu=1.0, sigma=0.5):
self.s, self.S, self.mu, self.sigma = s, S, mu, sigma
def update(self, x):
"根据当前状态x更新t到t+1的状态。"
Z = np.random.randn()
D = np.exp(self.mu + self.sigma * Z)
if x <= self.s:
return max(self.S - D, 0)
else:
return max(x - D, 0)
def sim_inventory_path(self, x_init, sim_length):
X = np.empty(sim_length)
X[0] = x_init
for t in range(sim_length-1):
X[t+1] = self.update(X[t])
return X
让我们运行第一个模拟,模拟单个路径:
firm = Firm()
s, S = firm.s, firm.S
sim_length = 100
x_init = 50
X = firm.sim_inventory_path(x_init, sim_length)
fig, ax = plt.subplots()
bbox = (0., 1.02, 1., .102)
legend_args = {'ncol': 3,
'bbox_to_anchor': bbox,
'loc': 3,
'mode': 'expand'}
ax.plot(X, label="库存")
ax.plot(np.full(sim_length, s), 'k--', label="$s$")
ax.plot(np.full(sim_length, S), 'k-', label="$S$")
ax.set_ylim(0, S+10)
ax.set_xlabel("时间")
ax.legend(**legend_args)
plt.show()
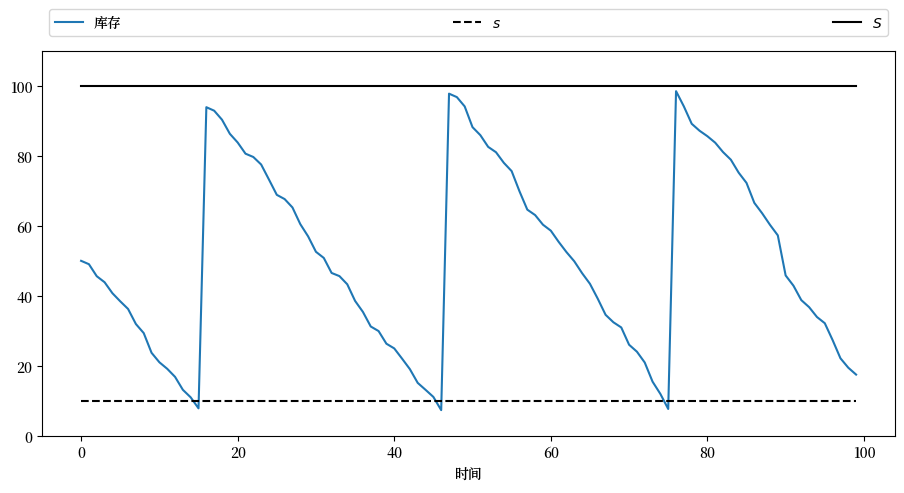
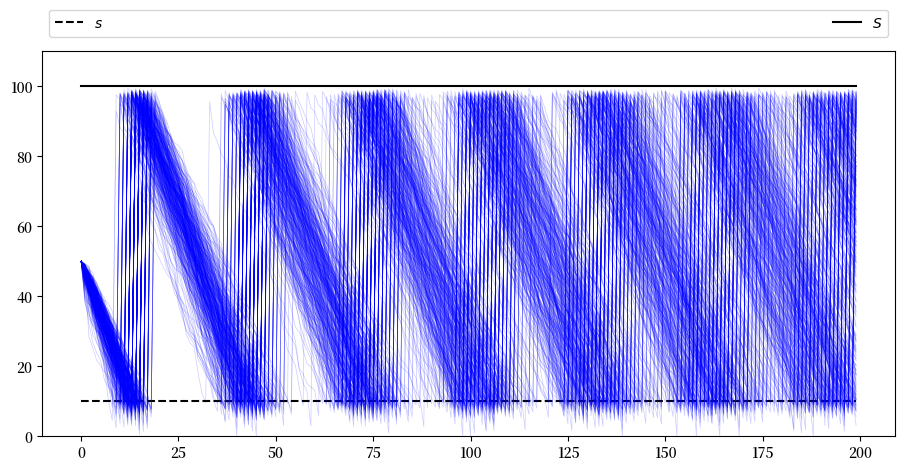
现在让我们模拟多条路径,这样可以更好地了解库存动态的整体行为和可能的库存分布:
sim_length=200
fig, ax = plt.subplots()
ax.plot(np.full(sim_length, s), 'k--', label="$s$")
ax.plot(np.full(sim_length, S), 'k-', label="$S$")
ax.set_ylim(0, S+10)
ax.legend(**legend_args)
for i in range(400):
X = firm.sim_inventory_path(x_init, sim_length)
ax.plot(X, 'b', alpha=0.2, lw=0.5)
plt.show()
35.3. 边际分布#
现在让我们来看看某一固定时间点 \(T\) 时 \(X_T\) 的边际分布 \(\psi_T\)。
我们将通过在给定初始条件 \(X_0\) 的情况下,生成多个 \(X_T\) 的样本来实现。
通过这些 \(X_T\) 的样本,我们可以构建其分布 \(\psi_T\) 的图像。
下面是\(T=50\)的情况下的一个可视化示例。
T = 50
M = 200 # 样本数量
ymin, ymax = 0, S + 10
fig, axes = plt.subplots(1, 2, figsize=(11, 6))
for ax in axes:
ax.grid(alpha=0.4)
ax = axes[0]
ax.set_ylim(ymin, ymax)
ax.set_ylabel('$X_t$', fontsize=16)
ax.vlines((T,), -1.5, 1.5)
ax.set_xticks((T,))
ax.set_xticklabels((r'$T$',))
sample = np.empty(M)
for m in range(M):
X = firm.sim_inventory_path(x_init, 2 * T)
ax.plot(X, 'b-', lw=1, alpha=0.5)
ax.plot((T,), (X[T+1],), 'ko', alpha=0.5)
sample[m] = X[T+1]
axes[1].set_ylim(ymin, ymax)
axes[1].hist(sample,
bins=16,
density=True,
orientation='horizontal',
histtype='bar',
alpha=0.5)
plt.show()
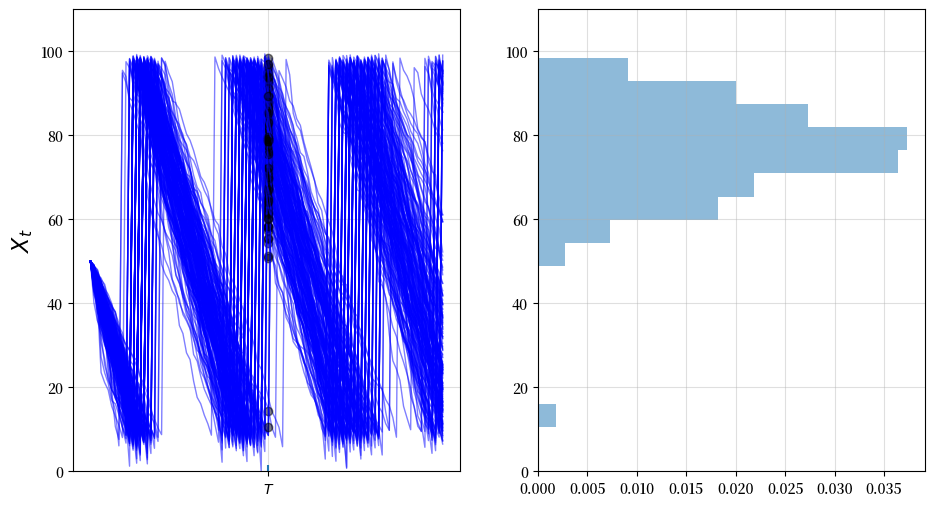
通过抽取更多样本,我们可以得到一个更清晰的图像
T = 50
M = 50_000
fig, ax = plt.subplots()
sample = np.empty(M)
for m in range(M):
X = firm.sim_inventory_path(x_init, T+1)
sample[m] = X[T]
ax.hist(sample,
bins=36,
density=True,
histtype='bar',
alpha=0.75)
plt.show()
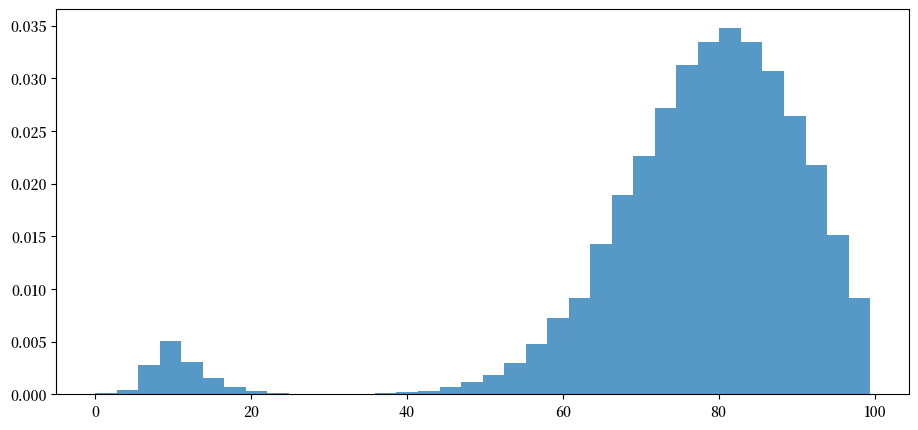
注意到分布呈双峰
大多数公司已经补了两次货,但也有少部分公司只补货一次(见上图路径)。
第二种公司的库存较少。
我们还可以使用核密度估计来近似这个分布。
核密度估计可以被理解为平滑的直方图。
当我们认为底层分布是平滑的时候,核密度估计通常比直方图提供更准确的图像。
我们将使用scikit-learn中的核密度估计量
from sklearn.neighbors import KernelDensity
def plot_kde(sample, ax, label=''):
xmin, xmax = 0.9 * min(sample), 1.1 * max(sample)
xgrid = np.linspace(xmin, xmax, 200)
kde = KernelDensity(kernel='gaussian').fit(sample[:, None])
log_dens = kde.score_samples(xgrid[:, None])
ax.plot(xgrid, np.exp(log_dens), label=label)
fig, ax = plt.subplots()
plot_kde(sample, ax)
plt.show()
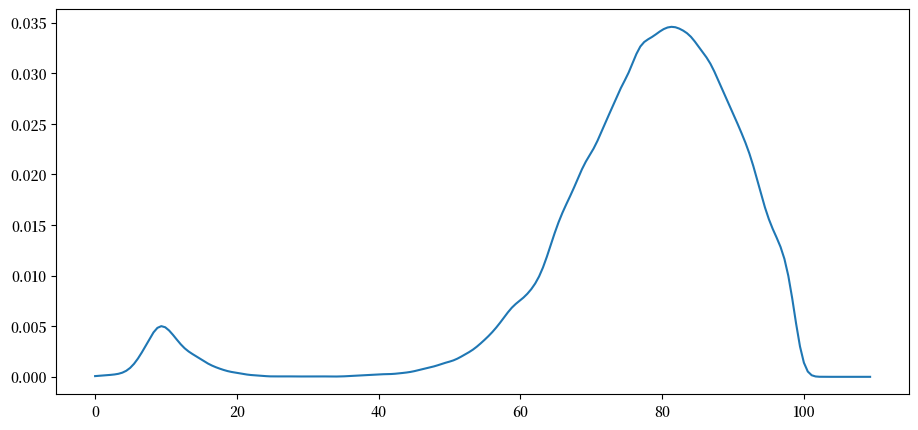
概率密度的分配与上面直方图所显示的类似。
35.4. 练习#
练习 35.1
这个模型是渐近平稳的,具有唯一的平稳分布。
(作为背景知识,有关平稳性的讨论,请参见我们关于AR(1)过程的讲座——基本概念是相同的。)
特别是,边际分布序列\(\{\psi_t\}\)正在收敛到一个唯一的极限分布,且该分布不依赖于初始条件。
虽然我们不会在此证明这一点,但我们可以通过模拟来研究这一性质。
你的任务是,根据上述讨论,在时间点\(t = 10, 50, 250, 500, 750\)生成并绘制序列\(\{\psi_t\}\)。
(核密度估计量可能是呈现每个分布最佳的方式。)
你应该能看到收敛性,体现在两个连续分布之间的差异越来越小。
尝试使用不同的初始条件来验证,无论从哪个初始状态开始,长期分布都会收敛到相同的平稳分布。
解答 练习 35.1
以下是其中一种解法:
由于这个计算需要大量的计算资源,我们需要编写更高效的代码。
为此,我们将创建一个专门的函数来替代之前使用的类,以提高计算效率。
s, S, mu, sigma = firm.s, firm.S, firm.mu, firm.sigma
@jit(parallel=True)
def shift_firms_forward(current_inventory_levels, num_periods):
num_firms = len(current_inventory_levels)
new_inventory_levels = np.empty(num_firms)
for f in prange(num_firms):
x = current_inventory_levels[f]
for t in range(num_periods):
Z = np.random.randn()
D = np.exp(mu + sigma * Z)
if x <= s:
x = max(S - D, 0)
else:
x = max(x - D, 0)
new_inventory_levels[f] = x
return new_inventory_levels
x_init = 50
num_firms = 50_000
sample_dates = 0, 10, 50, 250, 500, 750
first_diffs = np.diff(sample_dates)
fig, ax = plt.subplots()
X = np.full(num_firms, x_init)
current_date = 0
for d in first_diffs:
X = shift_firms_forward(X, d)
current_date += d
plot_kde(X, ax, label=f't = {current_date}')
ax.set_xlabel('库存')
ax.set_ylabel('概率')
ax.legend()
plt.show()
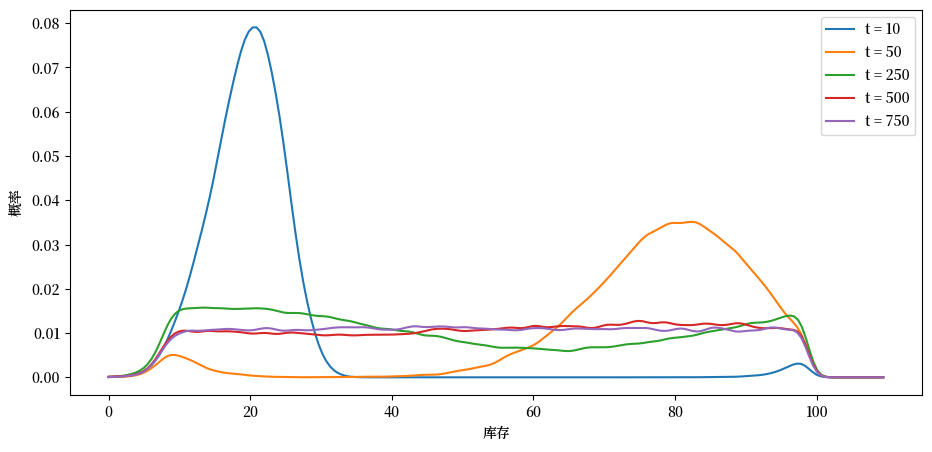
从图中可以看出,随着时间的推移,分布逐渐收敛到一个稳定状态。
在 t=500 和 t=750 时的分布几乎完全重合,表明我们已经得到了平稳密度的良好近似。
你可以通过测试多个不同的初始条件,来确定初始条件确实不重要。
例如,你可以尝试将所有公司的初始库存设置为 \(X_0 = 20\) 或 \(X_0 = 80\),然后重新运行上面的代码,观察分布最终是否收敛到相同的稳态分布。
练习 35.2
使用模拟的方法,估计一家初始库存为 \(X_0 = 70\) 的公司在前50个时期内至少需要补充库存两次的概率。
为了获得统计上可靠的结果,请确保使用足够大的样本量。
解答 练习 35.2
这里是一种解法。
同样地,由于计算量相对较大,我们编写了一个专门的函数而不是使用上面的类。
我们将利用并行计算来同时处理多家公司的模拟,以提高计算效率。
@jit(parallel=True)
def compute_freq(sim_length=50, x_init=70, num_firms=1_000_000):
firm_counter = 0 # 记录补货2次或以上的公司数量
for m in prange(num_firms):
x = x_init
restock_counter = 0 # 将记录公司m的补货次数
for t in range(sim_length):
Z = np.random.randn()
D = np.exp(mu + sigma * Z)
if x <= s:
x = max(S - D, 0)
restock_counter += 1
else:
x = max(x - D, 0)
if restock_counter > 1:
firm_counter += 1
return firm_counter / num_firms
记录程序运行所需的时间和输出结果。
%%time
freq = compute_freq()
print(f"至少发生两次缺货的频率 = {freq}")
至少发生两次缺货的频率 = 0.447659
CPU times: user 2.59 s, sys: 1.95 ms, total: 2.6 s
Wall time: 923 ms
尝试将上面@jit装饰器中的parallel参数改为False。
根据你的系统配置,运行速度的差异可能会很大。
(在我们的系统上运行速度提升了5倍!)