47. 工作搜寻 VI:在职搜索#
47.1. 概述#
在本节中,我们将解决一个简单的在职搜索模型
本讲基于 [Ljungqvist and Sargent, 2018] 的练习 6.18 和 [Jovanovic, 1979]
让我们从一些导入开始:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
import numpy as np
import scipy.stats as stats
from numba import jit, prange
47.1.1. 模型特点#
模型结合了在职搜索和工作岗位特定的人力资本积累
这是一个包含一个状态变量和两个控制变量的无限期动态规划问题
47.2. 模型#
设 \(x_t\) 为劳动者在当前公司和工作岗位的人力资本水平,\(w_t\) 为其当前工资。
工资由以下公式决定:\(w_t = x_t(1 - s_t - \phi_t)\),其中
\(\phi_t\) 表示劳动者在当前岗位为提高人力资本而付出的时间
\(s_t\) 表示寻找新工作机会的时间
只要劳动者继续留在当前工作,\(\{x_t\}\) 的演变由 \(x_{t+1} = g(x_t, \phi_t)\) 给出。
当 \(t\) 时刻的搜索努力为 \(s_t\) 时,劳动者以概率 \(\pi(s_t) \in [0, 1]\) 得到新的工作机会。
这个机会的价值(以力资本衡量)是 \(u_{t+1}\),其中 \(\{u_t\}\) 是具有共同分布 \(f\) 的独立同分布序列。
劳动者可以拒绝当前的工作机会并继续现有的工作。
因此,若劳动者接受了新的工作机会,则\(x_{t+1} = u_{t+1}\),否则 \(x_{t+1} = g(x_t, \phi_t)\)。
令 \(b_{t+1} \in \{0,1\}\) 为二元随机变量,其中 \(b_{t+1} = 1\) 表示劳动者在时间 \(t\) 结束时收到一个工作机会。
我们可以写成
模型中每个劳动者的目标:通过控制变量 \(\{s_t\}\) 和 \(\{\phi_t\}\) 来最大化预期折现工资总和。
对 \(v(x_{t+1})\) 取期望并使用 (47.1), 这个问题的贝尔曼方程可以写成
这里默认 \(s\) 和 \(\phi\) 非负,而 \(a \vee b := \max\{a, b\}\)。
47.2.1. 参数化#
在下面的实现中,我们将给以上模型添加参数化设定
默认参数值为
\(A = 1.4\)
\(\alpha = 0.6\)
\(\beta = 0.96\)
\(\text{Beta}(2,2)\) 分布的支撑集是 \((0,1)\) - 它具有单峰、对称的密度函数,峰值在0.5。
47.2.2. 粗略计算#
在求解模型之前,让我们先做一些简单的计算,帮助我们直观理解模型的解。
我们可以看到,劳动者有两种途径来积累资本并提高工资:
通过 \(\phi\) 投资于适用于当前工作人力资本
通过 \(s\) 搜寻更匹配岗位特定人力资本的新工作
由于工资是 \(x (1 - s - \phi)\),通过 \(\phi\) 或 \(s\) 进行投资的边际成本是相同的。
我们的风险中性劳动者应该专注于预期回报最高的方式。
相对预期回报将取决于\(x\)。
例如,假设\(x = 0.05\)
如果\(s=1\)且\(\phi = 0\),由于\(g(x,\phi) = 0\), 对(47.1)取期望值得到下一期的预期资本等于\(\pi(s) \mathbb{E} u = \mathbb{E} u = 0.5\)。
如果\(s=0\)且\(\phi=1\),那么下一期资本是\(g(x, \phi) = g(0.05, 1) \approx 0.23\)。
两种回报率都不错,但搜索的回报更好。
接下来,假设\(x = 0.4\)
如果\(s=1\)且\(\phi = 0\),那么下一期的预期资本仍然是\(0.5\)
如果\(s=0\)且\(\phi = 1\),那么\(g(x, \phi) = g(0.4, 1) \approx 0.8\)
在这种情况下,投资于岗位特定人力资本的回报高于搜索新工作的预期回报。
综合这些观察,我们得到两个非正式的预测:
在任何给定状态\(x\)下,两个控制变量\(\phi\)和\(s\)主要呈现替代关系 — 且劳动者会专注于预期回报较高的工具。
对于足够小的 \(x\),工作搜寻将优于岗位特定人力资本投资。而当\(x\)值较大时,结论则相反。
现在让我们转向模型实现,并验证是否与预测结果一致。
47.3. 模型实现#
我们将设置一个JVWorker类来保存上述模型的参数
class JVWorker:
r"""
一个Jovanovic类型的就业模型,包含在职搜索。
"""
def __init__(self,
A=1.4,
α=0.6,
β=0.96, # 折现因子
π=np.sqrt, # 搜索努力函数
a=2, # f的参数
b=2, # f的参数
grid_size=50,
mc_size=100,
ɛ=1e-4):
self.A, self.α, self.β, self.π = A, α, β, π
self.mc_size, self.ɛ = mc_size, ɛ
self.g = jit(lambda x, ϕ: A * (x * ϕ)**α) # 转移函数
self.f_rvs = np.random.beta(a, b, mc_size)
# 网格的最大值是f的大分位数值和固定点y = g(y, 1)的最大值
ɛ = 1e-4
grid_max = max(A**(1 / (1 - α)), stats.beta(a, b).ppf(1 - ɛ))
# 人力资本
self.x_grid = np.linspace(ɛ, grid_max, grid_size)
函数operator_factory接收这个类的实例并返回jit编译的贝尔曼算子T,即:
其中
当我们表示\(v\)时,将使用NumPy数组v在网格x_grid上给出值。
但要计算(47.3)右侧,我们需要一个函数,所以我们用函数v_func替换数组v和x_grid,该函数在x_grid上对v进行线性插值。
在for循环内部,对状态空间网格中的每个x,我们设置函数\(w(z) = w(s, \phi)\),如(47.3)中定义。
该函数在所有可行的\((s, \phi)\)对上最大化。
另一个函数get_greedy在给定值函数的情况下,返回每个\(x\)处\(s\)和\(\phi\)的最优选择。
def operator_factory(jv, parallel_flag=True):
"""
返回Bellman算子T的jit编译版本
jv是JVWorker的一个实例
"""
π, β = jv.π, jv.β
x_grid, ɛ, mc_size = jv.x_grid, jv.ɛ, jv.mc_size
f_rvs, g = jv.f_rvs, jv.g
@jit
def state_action_values(z, x, v):
s, ϕ = z
v_func = lambda x: np.interp(x, x_grid, v)
integral = 0
for m in range(mc_size):
u = f_rvs[m]
integral += v_func(max(g(x, ϕ), u))
integral = integral / mc_size
q = π(s) * integral + (1 - π(s)) * v_func(g(x, ϕ))
return x * (1 - ϕ - s) + β * q
@jit(parallel=parallel_flag)
def T(v):
"""
Bellman算子
"""
v_new = np.empty_like(v)
for i in prange(len(x_grid)):
x = x_grid[i]
# 在网格上搜索
search_grid = np.linspace(ɛ, 1, 15)
max_val = -1
for s in search_grid:
for ϕ in search_grid:
current_val = state_action_values((s, ϕ), x, v) if s + ϕ <= 1 else -1
if current_val > max_val:
max_val = current_val
v_new[i] = max_val
return v_new
@jit
def get_greedy(v):
"""
计算给定函数v的v-贪婪策略
"""
s_policy, ϕ_policy = np.empty_like(v), np.empty_like(v)
for i in range(len(x_grid)):
x = x_grid[i]
# 在网格上搜索
search_grid = np.linspace(ɛ, 1, 15)
max_val = -1
for s in search_grid:
for ϕ in search_grid:
current_val = state_action_values((s, ϕ), x, v) if s + ϕ <= 1 else -1
if current_val > max_val:
max_val = current_val
max_s, max_ϕ = s, ϕ
s_policy[i], ϕ_policy[i] = max_s, max_ϕ
return s_policy, ϕ_policy
return T, get_greedy
为了求解模型,我们将编写一个使用贝尔曼算子并通过迭代寻找不动点的函数。
def solve_model(jv,
use_parallel=True,
tol=1e-4,
max_iter=1000,
verbose=True,
print_skip=25):
"""
通过值函数迭代求解模型
* jv 是 JVWorker 的一个实例
"""
T, _ = operator_factory(jv, parallel_flag=use_parallel)
# 设置循环
v = jv.x_grid * 0.5 # 初始条件
i = 0
error = tol + 1
while i < max_iter and error > tol:
v_new = T(v)
error = np.max(np.abs(v - v_new))
i += 1
if verbose and i % print_skip == 0:
print(f"第{i}次迭代的误差为{error}。")
v = v_new
if error > tol:
print("未能收敛!")
elif verbose:
print(f"\n在第{i}次迭代后收敛。")
return v_new
47.4. 策略求解#
让我们生成最优政策并看看它们是什么样子。
jv = JVWorker()
T, get_greedy = operator_factory(jv)
v_star = solve_model(jv)
s_star, ϕ_star = get_greedy(v_star)
第25次迭代的误差为0.15111196170913566。
第50次迭代的误差为0.05446025485224126。
第75次迭代的误差为0.01962729704800026。
第100次迭代的误差为0.007073613416901381。
第125次迭代的误差为0.0025493070517743632。
第150次迭代的误差为0.0009187618917252394。
第175次迭代的误差为0.00033111876935265627。
第200次迭代的误差为0.00011933411736819721。
在第205次迭代后收敛。
我们绘制以下图表:
plots = [s_star, ϕ_star, v_star]
titles = [r"$s$策略", r"$\phi$策略", "价值函数"]
fig, axes = plt.subplots(3, 1, figsize=(12, 12))
for ax, plot, title in zip(axes, plots, titles):
ax.plot(jv.x_grid, plot)
ax.set(title=title)
ax.grid()
axes[-1].set_xlabel("x")
plt.show()
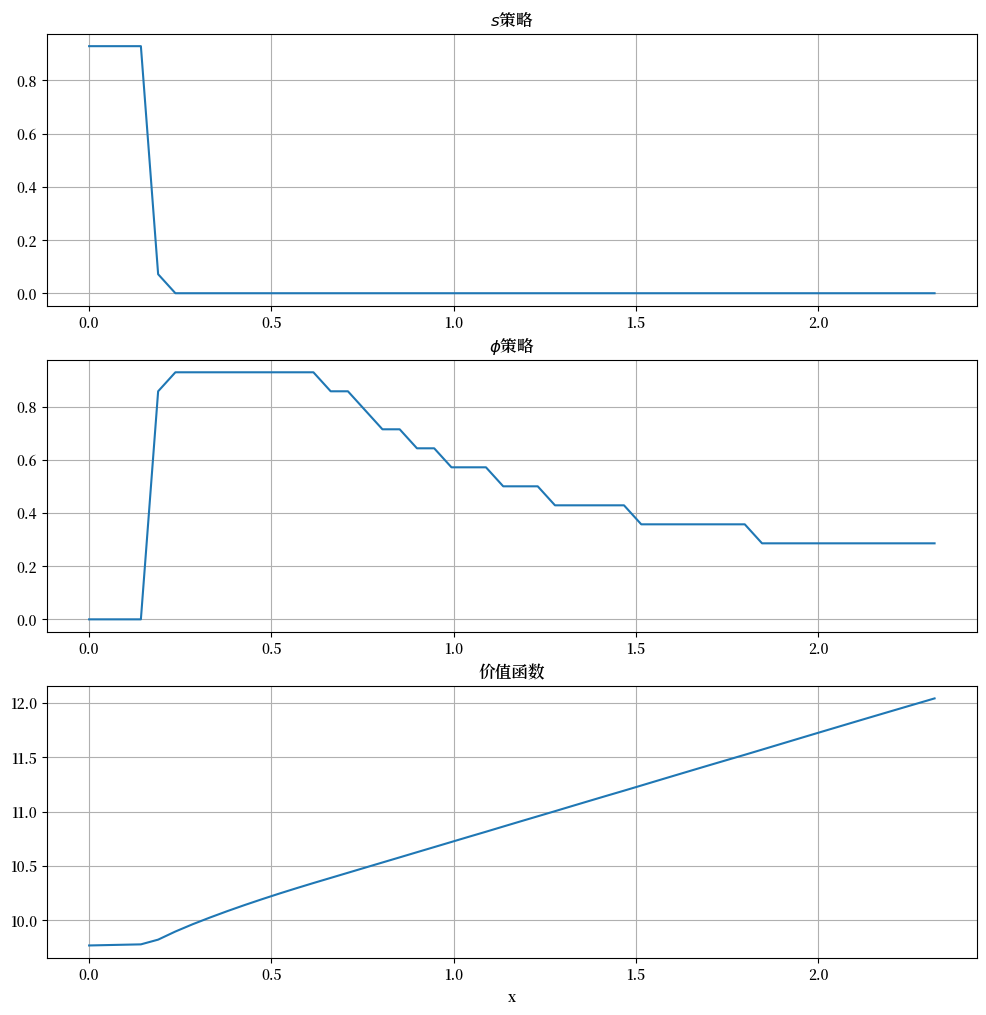
横轴表示状态变量 \(x\),纵轴表示 \(s(x)\) 和 \(\phi(x)\)。
总的来说,这些策略与我们在上文中的预测相符
劳动者根据相对回报在两种投资策略之间切换。
对于较低的 \(x\) 值,最佳选择是寻找新工作。
一旦 \(x\) 变大,劳动者通过投资于当前职位的特定人力资本会获得更好的回报。
47.5. 练习#
练习 47.1
让我们看看与这些策略相关的状态过程 \(\{x_t\}\) 的动态特征。
当根据最优策略选择 \(\phi_t\) 和 \(s_t\),且 \(\mathbb{P}\{b_{t+1} = 1\} = \pi(s_t)\) 时,动态特征由(47.1)给出。
由于动态是随机的,分析会有些微妙。
一种方法是对一个相对精细的网格(称为plot_grid)中的每个 \(x\),绘制大量(\(K\)个)在给定 \(x_t = x\) 条件下 \(x_{t+1}\) 的实现值。
用以下方式绘制每个实现对应一个点的45度图,设置
jv = JVWorker(grid_size=25, mc_size=50)
plot_grid_max, plot_grid_size = 1.2, 100
plot_grid = np.linspace(0, plot_grid_max, plot_grid_size)
fig, ax = plt.subplots()
ax.set_xlim(0, plot_grid_max)
ax.set_ylim(0, plot_grid_max)
通过观察图表,可以论证在最优策略下,状态 \(x_t\) 将收敛到接近1的常数值 \(\bar x\)。
论证在稳态时, \(s_t \approx 0\) 且 \(\phi_t \approx 0.6\)。
解答 练习 47.1
以下是生成45度图的代码
jv = JVWorker(grid_size=25, mc_size=50)
π, g, f_rvs, x_grid = jv.π, jv.g, jv.f_rvs, jv.x_grid
T, get_greedy = operator_factory(jv)
v_star = solve_model(jv, verbose=False)
s_policy, ϕ_policy = get_greedy(v_star)
# 将策略函数数组转换为实际函数
s = lambda y: np.interp(y, x_grid, s_policy)
ϕ = lambda y: np.interp(y, x_grid, ϕ_policy)
def h(x, b, u):
return (1 - b) * g(x, ϕ(x)) + b * max(g(x, ϕ(x)), u)
plot_grid_max, plot_grid_size = 1.2, 100
plot_grid = np.linspace(0, plot_grid_max, plot_grid_size)
fig, ax = plt.subplots(figsize=(8, 8))
ticks = (0.25, 0.5, 0.75, 1.0)
ax.set(xticks=ticks, yticks=ticks,
xlim=(0, plot_grid_max),
ylim=(0, plot_grid_max),
xlabel='$x_t$', ylabel='$x_{t+1}$')
ax.plot(plot_grid, plot_grid, 'k--', alpha=0.6) # 45度线
for x in plot_grid:
for i in range(jv.mc_size):
b = 1 if np.random.uniform(0, 1) < π(s(x)) else 0
u = f_rvs[i]
y = h(x, b, u)
ax.plot(x, y, 'go', alpha=0.25)
plt.show()
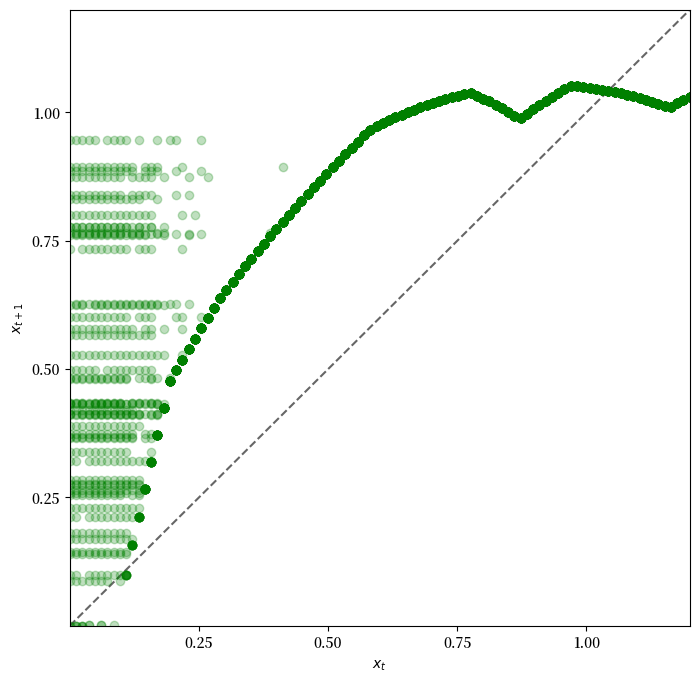
观察动态变化,我们可以看到
如果 \(x_t\) 低于约0.2,动态变化是随机的,但 \(x_{t+1} > x_t\) 的可能性很大。
随着 \(x_t\) 增加,动态变化变得确定性,并且 \(x_t\) 收敛到接近1的稳态值。
参考回 这里 的图表,我们看到 \(x_t \approx 1\) 意味着 \(s_t = s(x_t) \approx 0\) 且 \(\phi_t = \phi(x_t) \approx 0.6\)。
练习 47.2
在 练习 47.1 中,我们发现 \(s_t\) 收敛到零, 而 \(\phi_t\) 收敛到约0.6。
由于这些结果是在 \(\beta\) 接近1的情况下计算的, 让我们将它们与无限耐心的劳动者的最佳选择进行比较。
直观地说,无限耐心的劳动者会希望最大化稳态工资, 而稳态工资是稳态资本的函数。
你可以认为这是既定事实——这确实是真的——无限耐心的劳动者 在长期内不会搜索(即,对于较大的 \(t\),\(s_t = 0\))。
因此,给定 \(\phi\),稳态资本是映射 \(x \mapsto g(x, \phi)\) 的正固定点 \(x^*(\phi)\)。
稳态工资可以写作 \(w^*(\phi) = x^*(\phi) (1 - \phi)\)。
绘制 \(w^*(\phi)\) 关于 \(\phi\) 的图像,并研究 \(\phi\) 的最佳选择。
你能对你看到的值给出一个大致的解释吗?
解答 练习 47.2
可以用以下方法生成图像
jv = JVWorker()
def xbar(ϕ):
A, α = jv.A, jv.α
return (A * ϕ**α)**(1 / (1 - α))
ϕ_grid = np.linspace(0, 1, 100)
fig, ax = plt.subplots(figsize=(9, 7))
ax.set(xlabel=r'$\phi$')
ax.plot(ϕ_grid, [xbar(ϕ) * (1 - ϕ) for ϕ in ϕ_grid], label=r'$w^*(\phi)$')
ax.legend()
plt.show()
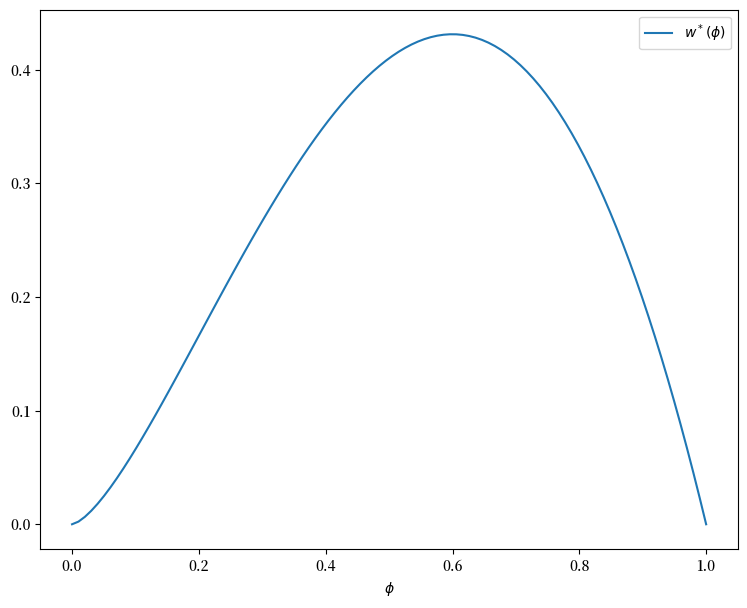
观察到最大值约在0.6处。
这与练习 47.1中得到的\(\phi\)的长期值相似。
因此,无限耐心的劳动者的行为与\(\beta = 0.96\)的劳动者的行为相似。
这看起来是合理的,并且帮助我们确认我们的动态规划解可能是正确的。