40. 初见卡尔曼滤波器#
除了Anaconda中已有的库外,本课程还需要以下库:
!pip install quantecon
40.1. 概述#
本讲座为卡尔曼滤波器提供了一个简单直观的介绍,适合以下读者:
听说过卡尔曼滤波器但不知道它如何运作的人,或者
知道卡尔曼滤波的方程但不知道这些方程从何而来的人
关于卡尔曼滤波的更多(进阶)阅读材料,请参见:
第二个参考文献对卡尔曼滤波器进行了全面的阐述。
所需知识:熟悉矩阵运算、多元正态分布、协方差矩阵等。
我们需要以下导入:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5) #set default figure size
from scipy import linalg
import numpy as np
import matplotlib.cm as cm
from quantecon import Kalman, LinearStateSpace
from scipy.stats import norm
from scipy.integrate import quad
from scipy.linalg import eigvals
40.2. 基本概念#
卡尔曼滤波器在经济学中有许多应用,但现在让我们假装我们是火箭科学家。
一枚导弹从Y国发射,我们的任务是追踪它。
让 \(x \in \mathbb{R}^2\) 表示导弹的当前位置——一个表示地图上经纬度坐标的数对。
在当前时刻,精确位置 \(x\) 是未知的,但我们对 \(x\) 有一些认知。
总结我们知识的一种方式是点预测 \(\hat x\)
然而,点预测可能不够用。例如,我们可能需要回答”导弹目前在日本海上空的概率是多少”这样的问题。
为了回答这类问题,我们需要用二元概率密度函数 \(p\) 来描述我们对导弹位置的认知。
对于任意区域 \(E\),积分 \(\int_E p(x)dx\) 给出了我们认为导弹在该区域内的概率。
密度 \(p\) 被称为随机变量 \(x\) 的先验分布。
为了使我们的例子便于处理,我们假设我们的先验分布是高斯分布。
特别地,我们采用
其中 \(\hat x\) 是分布的均值,\(\Sigma\) 是一个 \(2 \times 2\) 的协方差矩阵。在我们的模拟中,我们假设
这个密度 \(p(x)\) 在下面以等高线图的形式显示,其中红色椭圆的中心等于 \(\hat x\)。
# 设定高斯先验分布 p
Σ = [[0.4, 0.3], [0.3, 0.45]]
Σ = np.matrix(Σ)
x_hat = np.matrix([0.2, -0.2]).T
# 从方程 y = G x + N(0, R) 定义矩阵 G 和 R
G = [[1, 0], [0, 1]]
G = np.matrix(G)
R = 0.5 * Σ
# 矩阵 A 和 Q
A = [[1.2, 0], [0, -0.2]]
A = np.matrix(A)
Q = 0.3 * Σ
# y 的观测值
y = np.matrix([2.3, -1.9]).T
# 设定绘图网格
x_grid = np.linspace(-1.5, 2.9, 100)
y_grid = np.linspace(-3.1, 1.7, 100)
X, Y = np.meshgrid(x_grid, y_grid)
def bivariate_normal(x, y, σ_x=1.0, σ_y=1.0, μ_x=0.0, μ_y=0.0, σ_xy=0.0):
"""
计算并返回二元正态分布的概率密度函数
参数
----------
x : array_like(float)
随机变量
y : array_like(float)
随机变量
σ_x : array_like(float)
随机变量 x 的标准差
σ_y : array_like(float)
随机变量 y 的标准差
μ_x : scalar(float)
随机变量 x 的均值
μ_y : scalar(float)
随机变量 y 的均值
σ_xy : array_like(float)
随机变量 x 和 y 的协方差
"""
x_μ = x - μ_x
y_μ = y - μ_y
ρ = σ_xy / (σ_x * σ_y)
z = x_μ**2 / σ_x**2 + y_μ**2 / σ_y**2 - 2 * ρ * x_μ * y_μ / (σ_x * σ_y)
denom = 2 * np.pi * σ_x * σ_y * np.sqrt(1 - ρ**2)
return np.exp(-z / (2 * (1 - ρ**2))) / denom
def gen_gaussian_plot_vals(μ, C):
"用于绘制二元高斯 N(μ, C) 的 Z 值"
m_x, m_y = float(μ[0].item()), float(μ[1].item())
s_x, s_y = np.sqrt(C[0, 0]), np.sqrt(C[1, 1])
s_xy = C[0, 1]
return bivariate_normal(X, Y, s_x, s_y, m_x, m_y, s_xy)
# 绘制图形
fig, ax = plt.subplots(figsize=(10, 8))
ax.grid()
Z = gen_gaussian_plot_vals(x_hat, Σ)
ax.contourf(X, Y, Z, 6, alpha=0.6, cmap=cm.jet)
cs = ax.contour(X, Y, Z, 6, colors="black")
ax.clabel(cs, inline=1, fontsize=10)
plt.show()
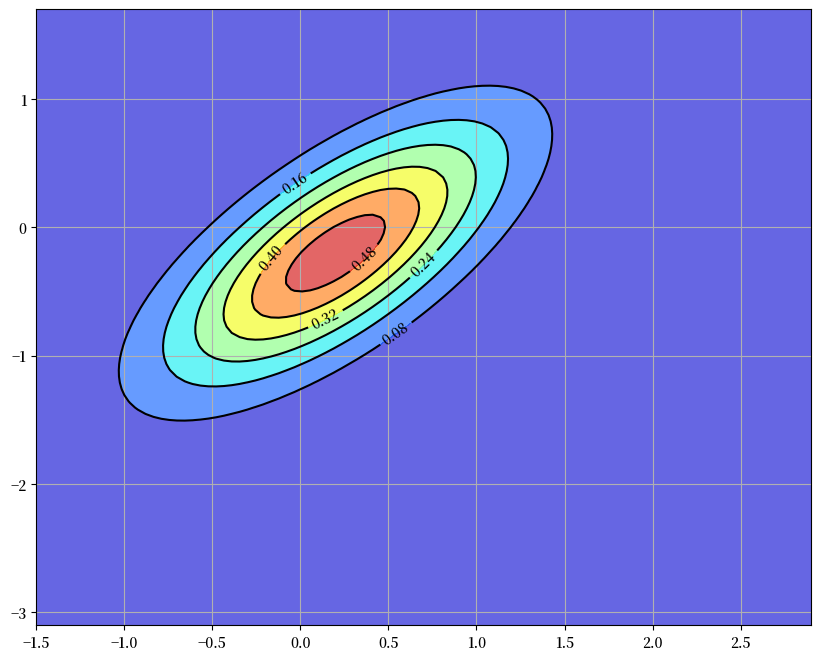
40.2.1. 滤波步骤#
现在我们有一些好消息和坏消息。
好消息是我们的传感器已经定位到导弹,报告显示当前位置是\(y = (2.3, -1.9)\)。
下图显示了原始先验分布\(p(x)\)和新报告的位置\(y\)
fig, ax = plt.subplots(figsize=(10, 8))
ax.grid()
Z = gen_gaussian_plot_vals(x_hat, Σ)
ax.contourf(X, Y, Z, 6, alpha=0.6, cmap=cm.jet)
cs = ax.contour(X, Y, Z, 6, colors="black")
ax.clabel(cs, inline=1, fontsize=10)
ax.text(float(y[0]), float(y[1]), "$y$", fontsize=20, color="black")
plt.show()
/tmp/ipykernel_9724/3470248806.py:8: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
ax.text(float(y[0]), float(y[1]), "$y$", fontsize=20, color="black")

坏消息是我们的传感器并不精确。
具体来说,我们不应该将传感器的输出理解为\(y=x\),而是
这里 \(G\) 和 \(R\) 是 \(2 \times 2\) 矩阵,其中 \(R\) 是正定矩阵。两者都被假定为已知,且噪声项 \(v\) 被假定与 \(x\) 独立。
那么,我们应该如何将我们的先验分布 \(p(x) = N(\hat x, \Sigma)\) 和这个新信息 \(y\) 结合起来,以提高我们对导弹位置的了解呢?
你可能已经猜到了,答案是使用贝叶斯定理,它告诉我们通过以下方式将先验分布 \(p(x)\) 更新为 \(p(x \,|\, y)\):
其中 \(p(y) = \int p(y \,|\, x) \, p(x) dx\)。
在求解 \(p(x \,|\, y)\) 时,我们观察到:
\(p(x) = N(\hat x, \Sigma)\)。
根据 (40.3),条件密度 \(p(y \,|\, x)\) 是 \(N(Gx, R)\)。
\(p(y)\) 不依赖于 \(x\),在计算中仅作为归一化常数出现。
由于我们处在线性和高斯框架中,可以通过计算总体线性回归来得到更新后的密度。
具体来说,我们可以得出解[1]为
其中
这里 \(\Sigma G' (G \Sigma G' + R)^{-1}\) 是隐藏对象 \(x - \hat x\) 对意外值 \(y - G \hat x\) 的总体回归系数矩阵。
下图通过等高线和色彩图展示了这个新的密度 \(p(x \,|\, y) = N(\hat x^F, \Sigma^F)\)。
原始密度以等高线的形式保留作为对比
fig, ax = plt.subplots(figsize=(10, 8))
ax.grid()
Z = gen_gaussian_plot_vals(x_hat, Σ)
cs1 = ax.contour(X, Y, Z, 6, colors="black")
ax.clabel(cs1, inline=1, fontsize=10)
M = Σ * G.T * linalg.inv(G * Σ * G.T + R)
x_hat_F = x_hat + M * (y - G * x_hat)
Σ_F = Σ - M * G * Σ
new_Z = gen_gaussian_plot_vals(x_hat_F, Σ_F)
cs2 = ax.contour(X, Y, new_Z, 6, colors="black")
ax.clabel(cs2, inline=1, fontsize=10)
ax.contourf(X, Y, new_Z, 6, alpha=0.6, cmap=cm.jet)
ax.text(float(y[0].item()), float(y[1].item()), "$y$", fontsize=20, color="black")
plt.show()
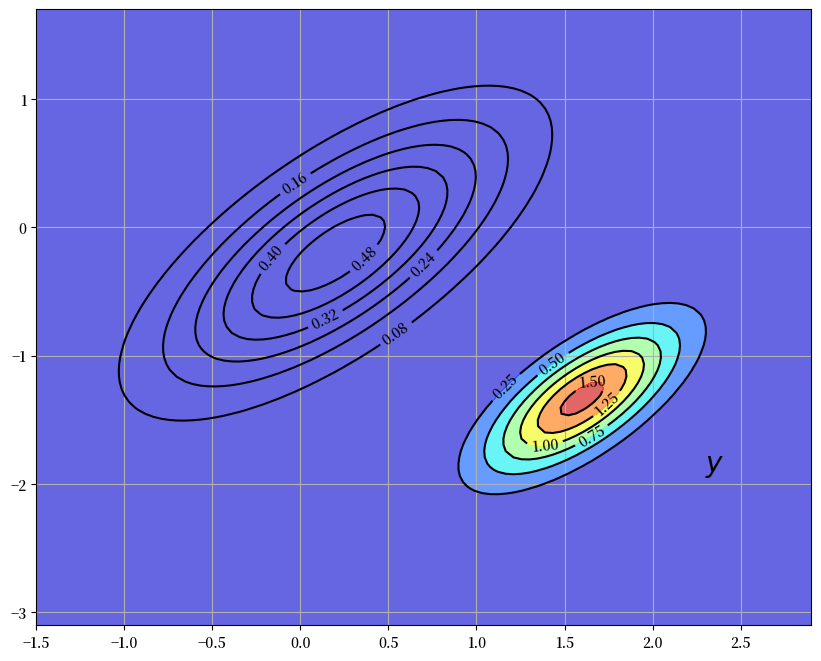
我们的新密度函数按照由新信息 \(y - G \hat x\) 决定的方向扭转了先验分布 \(p(x)\)。
在生成图形时,我们将 \(G\) 设为单位矩阵,将 \(R\) 设为 \(0.5 \Sigma\),其中 \(\Sigma\) 在(40.2)中定义。
40.2.2. 预测步骤#
到目前为止我们取得了什么成果?
我们在给定先验分布和当前信息的情况下,已经获得了状态(导弹)当前位置的概率。
这被称为”滤波”而不是预测,因为我们是在过滤噪声而不是展望未来。
\(p(x \,|\, y) = N(\hat x^F, \Sigma^F)\) 被称为滤波分布
但现在假设我们有另一个任务:预测导弹在一个时间单位后(无论是什么单位)的位置。
为此我们需要一个状态演化的模型。
让我们假设我们有这样一个模型,而且它是线性高斯的。具体来说,
我们的目标是将这个运动定律和我们当前的分布 \(p(x \,|\, y) = N(\hat x^F, \Sigma^F)\) 结合起来,得出一个新的一个时间单位后位置的预测分布。
根据(40.5),我们只需要引入一个随机向量 \(x^F \sim N(\hat x^F, \Sigma^F)\) 并计算出 \(A x^F + w\) 的分布,其中 \(w\) 与 \(x^F\) 独立且服从分布 \(N(0, Q)\)。
由于高斯分布的线性组合仍是高斯分布,\(A x^F + w\) 也是高斯分布。
基本计算和(40.4)中的表达式告诉我们:
和
矩阵 \(A \Sigma G' (G \Sigma G' + R)^{-1}\) 通常写作 \(K_{\Sigma}\) 并称为卡尔曼增益。
添加下标 \(\Sigma\) 是为了提醒我们 \(K_{\Sigma}\) 依赖于 \(\Sigma\),而不依赖于 \(y\) 或 \(\hat x\)。
使用这个符号,我们可以将结果总结如下。
我们更新后的预测是密度 \(N(\hat x_{new}, \Sigma_{new})\),其中
密度 \(p_{new}(x) = N(\hat x_{new}, \Sigma_{new})\) 被称为预测分布
预测分布是下图中显示的新密度,其中更新使用了以下参数。
fig, ax = plt.subplots(figsize=(10, 8))
ax.grid()
# Density 1
Z = gen_gaussian_plot_vals(x_hat, Σ)
cs1 = ax.contour(X, Y, Z, 6, colors="black")
ax.clabel(cs1, inline=1, fontsize=10)
# Density 2
M = Σ * G.T * linalg.inv(G * Σ * G.T + R)
x_hat_F = x_hat + M * (y - G * x_hat)
Σ_F = Σ - M * G * Σ
Z_F = gen_gaussian_plot_vals(x_hat_F, Σ_F)
cs2 = ax.contour(X, Y, Z_F, 6, colors="black")
ax.clabel(cs2, inline=1, fontsize=10)
# Density 3
new_x_hat = A * x_hat_F
new_Σ = A * Σ_F * A.T + Q
new_Z = gen_gaussian_plot_vals(new_x_hat, new_Σ)
cs3 = ax.contour(X, Y, new_Z, 6, colors="black")
ax.clabel(cs3, inline=1, fontsize=10)
ax.contourf(X, Y, new_Z, 6, alpha=0.6, cmap=cm.jet)
ax.text(float(y[0].item()), float(y[1].item()), "$y$", fontsize=20, color="black")
plt.show()

40.2.3. 递归程序#
让我们回顾一下我们所做的工作。
我们以导弹位置\(x\)的先验分布\(p(x)\)开始当前周期。
然后我们使用当前测量值\(y\)更新为\(p(x \,|\, y)\)。
最后,我们使用\(\{x_t\}\)的运动方程(40.5)将其更新为\(p_{new}(x)\)。
如果我们现在进入下一个周期,我们就可以再次循环,将\(p_{new}(x)\)作为当前的先验分布。
将符号\(p_t(x)\)替换为\(p(x)\),将\(p_{t+1}(x)\)替换为\(p_{new}(x)\),完整的递归程序为:
以先验分布\(p_t(x) = N(\hat x_t, \Sigma_t)\)开始当前周期。
观察当前测量值\(y_t\)。
根据\(p_t(x)\)和\(y_t\)计算滤波分布\(p_t(x \,|\, y) = N(\hat x_t^F, \Sigma_t^F)\),应用贝叶斯法则和条件分布(40.3)。
根据滤波分布和(40.5)计算预测分布 \(p_{t+1}(x) = N(\hat x_{t+1}, \Sigma_{t+1})\)。
将 \(t\) 加一并返回步骤1。
重复(40.6),\(\hat x_t\) 和 \(\Sigma_t\) 的动态方程如下
这些是卡尔曼滤波的标准动态方程(参见,例如,[Ljungqvist and Sargent, 2018],第58页)。
40.3. 收敛性#
矩阵 \(\Sigma_t\) 是我们对 \(x_t\) 的预测 \(\hat x_t\) 的不确定性的度量。
除了特殊情况外,无论经过多长时间,这种不确定性都永远不会完全消除。
其中一个原因是我们的预测 \(\hat x_t\) 是基于 \(t-1\) 时刻的信息而不是 \(t\) 时刻的信息。
即使我们知道 \(x_{t-1}\) 的精确值(实际上我们并不知道),转移方程 (40.5) 表明 \(x_t = A x_{t-1} + w_t\)。
由于冲击项 \(w_t\) 在 \(t-1\) 时不可观测,任何在 \(t-1\) 时对 \(x_t\) 的预测都会产生一些误差(除非 \(w_t\) 是退化的)。
然而,\(\Sigma_t\) 在 \(t \to \infty\) 时收敛到一个常数矩阵是完全可能的。
为了研究这个问题,让我们展开 (40.7) 中的第二个方程:
这是一个关于 \(\Sigma_t\) 的非线性差分方程。
(40.8) 的固定点是满足以下条件的常数矩阵 \(\Sigma\):
方程 (40.8) 被称为离散时间黎卡提差分方程。
方程 (40.9) 被称为离散时间代数黎卡提方程。
关于固定点存在的条件以及序列 \(\{\Sigma_t\}\) 收敛到该固定点的条件在 [Anderson et al., 1996] 和 [Anderson and Moore, 2005] 第4章中有详细讨论。
一个充分(但非必要)条件是 \(A\) 的所有特征值 \(\lambda_i\) 满足 \(|\lambda_i| < 1\)(参见 [Anderson and Moore, 2005],第77页)。
(这个强条件确保了 \(x_t\) 的无条件分布在 \(t \rightarrow + \infty\) 时收敛。)
在这种情况下,对于任何非负且对称的初始 \(\Sigma_0\) 选择,(40.8) 中的序列 \(\{\Sigma_t\}\) 都会收敛到一个非负对称矩阵 \(\Sigma\),该矩阵是 (40.9) 的解。
40.4. 实现#
QuantEcon.py 包的 Kalman 类实现了卡尔曼滤波器
实例数据包括:
当前先验分布的矩 \((\hat x_t, \Sigma_t)\)
来自 QuantEcon.py 的 LinearStateSpace 类的一个实例
后者表示形式如下的线性状态空间模型
其中冲击项 \(w_t\) 和 \(v_t\) 是独立同分布的标准正态分布。
为了与本章节的符号保持一致,我们设定
QuantEcon.py 包的
Kalman类有许多方法,其中一些我们会等到后续章节中学习更高级的应用时再使用。与本讲座相关的方法有:
prior_to_filtered,将 \((\hat x_t, \Sigma_t)\) 更新为 \((\hat x_t^F, \Sigma_t^F)\)filtered_to_forecast,将滤波分布更新为预测分布 – 成为新的先验分布 \((\hat x_{t+1}, \Sigma_{t+1})\)update,结合上述两种方法stationary_values,计算(40.9)的解和相应的(稳态)卡尔曼增益
你可以在GitHub上查看程序。
40.5. 练习#
练习 40.1
考虑以下卡尔曼滤波的简单应用,大致基于[Ljungqvist and Sargent, 2018]第2.9.2节。
假设
所有变量都是标量
隐藏状态 \(\{x_t\}\) 实际上是常数,等于建模者未知的某个 \(\theta \in \mathbb{R}\)
因此,状态动态由(40.5)给出,其中 \(A=1\),\(Q=0\) 且 \(x_0 = \theta\)。
测量方程为 \(y_t = \theta + v_t\),其中 \(v_t\) 服从 \(N(0,1)\) 且独立同分布。
本练习的任务是模拟该模型,并使用 kalman.py 中的代码绘制前五个预测密度 \(p_t(x) = N(\hat x_t, \Sigma_t)\)。
如 [Ljungqvist and Sargent, 2018] 第2.9.1–2.9.2节所示,这些分布渐近地将所有质量集中在未知值 \(\theta\) 上。
在模拟中,取 \(\theta = 10\),\(\hat x_0 = 8\) 和 \(\Sigma_0 = 1\)。
你的图形应该 – 除去随机性 – 看起来像这样

解答 练习 40.1
# 参数
θ = 10 # 状态 x_t 的常数值
A, C, G, H = 1, 0, 1, 1
ss = LinearStateSpace(A, C, G, H, mu_0=θ)
# 设定先验分布,初始化卡尔曼滤波器
x_hat_0, Σ_0 = 8, 1
kalman = Kalman(ss, x_hat_0, Σ_0)
# 从状态空间模型中抽取 y 的观测值
N = 5
x, y = ss.simulate(N)
y = y.flatten()
# 设定图形
fig, ax = plt.subplots(figsize=(10,8))
xgrid = np.linspace(θ - 5, θ + 2, 200)
for i in range(N):
# 记录当前预测的均值和方差
m, v = [float(z) for z in (kalman.x_hat, kalman.Sigma)]
# 绘图,更新滤波器
ax.plot(xgrid, norm.pdf(xgrid, loc=m, scale=np.sqrt(v)), label=f'$t={i}$')
kalman.update(y[i])
ax.set_title(f'当 $\\theta = {θ:.1f}$ 时的前 {N} 个密度')
ax.legend(loc='upper left')
plt.show()
/tmp/ipykernel_9724/3457786953.py:21: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
m, v = [float(z) for z in (kalman.x_hat, kalman.Sigma)]

练习 40.2
前面的图形支持了概率质量收敛到 \(\theta\) 的观点。
为了更好地理解这一点,选择一个小的 \(\epsilon > 0\) 并计算
其中 \(t = 0, 1, 2, \ldots, T\)。
绘制 \(z_t\) 与 \(T\) 的关系图,设定 \(\epsilon = 0.1\) 和 \(T = 600\)。
你的图应该显示误差不规则地下降,类似这样

解答 练习 40.2
ϵ = 0.1
θ = 10 # 状态x_t的常数值
A, C, G, H = 1, 0, 1, 1
ss = LinearStateSpace(A, C, G, H, mu_0=θ)
x_hat_0, Σ_0 = 8, 1
kalman = Kalman(ss, x_hat_0, Σ_0)
T = 600
z = np.empty(T)
x, y = ss.simulate(T)
y = y.flatten()
for t in range(T):
# 记录当前预测的均值和方差并绘制其密度
m, v = [float(temp.item()) for temp in (kalman.x_hat, kalman.Sigma)]
f = lambda x: norm.pdf(x, loc=m, scale=np.sqrt(v))
integral, error = quad(f, θ - ϵ, θ + ϵ)
z[t] = 1 - integral
kalman.update(y[t])
fig, ax = plt.subplots(figsize=(9, 7))
ax.set_ylim(0, 1)
ax.set_xlim(0, T)
ax.plot(range(T), z)
ax.fill_between(range(T), np.zeros(T), z, color="blue", alpha=0.2)
plt.show()

练习 40.3
如上文所述,如果冲击序列 \(\{w_t\}\) 不是退化的,那么在 \(t-1\) 时刻通常无法无误地预测 \(x_t\)(即使我们能观察到 \(x_{t-1}\) ,情况也是如此)。
让我们现在将在卡尔曼滤波器得到的预测值 \(\hat x_t\) 与一个被允许观察 \(x_{t-1}\) 的竞争者进行比较。
这个竞争者将使用条件期望 \(\mathbb E[ x_t \,|\, x_{t-1}]\),在这种情况下等于 \(A x_{t-1}\)。
条件期望被认为是在最小化均方误差方面的最优预测方法。
(更准确地说, \(\mathbb E \, \| x_t - g(x_{t-1}) \|^2\) 关于 \(g\) 的最小值是 \(g^*(x_{t-1}) := \mathbb E[ x_t \,|\, x_{t-1}]\))
因此,我们是在将卡尔曼滤波器与一个拥有更多信息(能够观察潜在状态)的竞争者进行比较,并且
在最小化平方误差方面表现最优。
我们的赛马式竞争将以平方误差来评估。
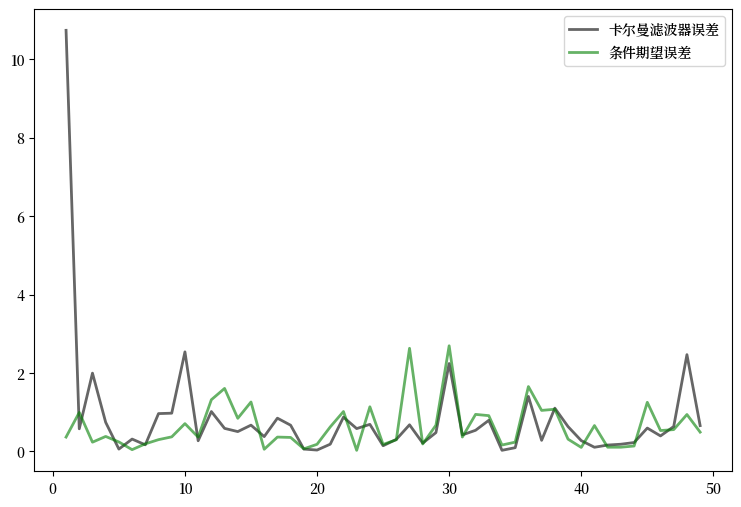
具体来说,你的任务是生成一个图表,绘制 \(\| x_t - A x_{t-1} \|^2\) 和 \(\| x_t - \hat x_t \|^2\) 对 \(t\) 的观测值,其中 \(t = 1, \ldots, 50\)。
对于参数,设定 \(G = I, R = 0.5 I\) 和 \(Q = 0.3 I\),其中 \(I\) 是 \(2 \times 2\) 单位矩阵。
设定
要初始化先验分布,设定
且 \(\hat x_0 = (8, 8)\)。
最后,设定 \(x_0 = (0, 0)\)。
你最终应该得到一个类似下图的图表(考虑随机性的影响)

观察可以发现,在初始学习期之后,卡尔曼滤波器表现得相当好,即使与那些在已知潜在状态的情况下进行最优预测的竞争者相比也是如此。
解答 练习 40.3
# 定义 A, C, G, H
G = np.identity(2)
H = np.sqrt(0.5) * np.identity(2)
A = [[0.5, 0.4],
[0.6, 0.3]]
C = np.sqrt(0.3) * np.identity(2)
# 设定状态空间模型,初始值 x_0 设为零
ss = LinearStateSpace(A, C, G, H, mu_0 = np.zeros(2))
# 定义先验分布
Σ = [[0.9, 0.3],
[0.3, 0.9]]
Σ = np.array(Σ)
x_hat = np.array([8, 8])
# 初始化卡尔曼滤波器
kn = Kalman(ss, x_hat, Σ)
# 打印 A 的特征值
print("A 的特征值:")
print(eigvals(A))
# 打印平稳 Σ
S, K = kn.stationary_values()
print("平稳的预测误差方差:")
print(S)
# 生成图表
T = 50
x, y = ss.simulate(T)
e1 = np.empty(T-1)
e2 = np.empty(T-1)
for t in range(1, T):
kn.update(y[:,t])
e1[t-1] = np.sum((x[:, t] - kn.x_hat.flatten())**2)
e2[t-1] = np.sum((x[:, t] - A @ x[:, t-1])**2)
fig, ax = plt.subplots(figsize=(9,6))
ax.plot(range(1, T), e1, 'k-', lw=2, alpha=0.6,
label='卡尔曼滤波器误差')
ax.plot(range(1, T), e2, 'g-', lw=2, alpha=0.6,
label='条件期望误差')
ax.legend()
plt.show()
A 的特征值:
[ 0.9+0.j -0.1+0.j]
平稳的预测误差方差:
[[0.40329108 0.1050718 ]
[0.1050718 0.41061709]]
练习 40.4
尝试上下调整\(Q = 0.3 I\) 中的系数 \(0.3\)。
观察平稳解 \(\Sigma\) (参见 (40.9)) 中的对角线值如何随这个系数增减而变化。
这说明 \(x_t\) 运动规律中的随机性越大,会导致预测中的(永久性)不确定性越大。