69. 就业与失业的湖泊模型#
除了Anaconda环境中自带的库之外,本讲义还需要安装以下库:
!pip install quantecon
69.1. 概述#
本讲义介绍了一种被称为湖泊模型的框架。
湖泊模型是用于刻画失业动态的基础分析工具。
它使我们能够系统地研究:
失业与就业之间的流动
这些流动如何影响稳态就业率和失业率
本模型有助于解释劳动部门每月关于毛额与净额的岗位创造与岗位流失的统计报告。
模型中的”湖泊”是就业者与失业者的群体池。
而”流动”则对应于下列行为所导致的转换:
解雇和雇佣
劳动力市场的进入和退出
在本讲义的前半部分,我们假定失业和就业之间的转换参数是外生的。
之后,我们将通过McCall搜索模型内生化这些转移率。
此外,我们还将引入一些重要的概念,如遍历性(ergodicity),它为横截面分布与长期时间序列分布之间提供了基本的理论联系。
这些概念将帮助我们建立一个均衡模型,该模型描述了事前同质的个体,由于不同的运气,在事后经历上表现出差异。
首先,我们导入所需的程序库:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5) #设置默认图形大小
import numpy as np
from quantecon import MarkovChain
import scipy.stats as stats
from scipy.optimize import brentq
from quantecon.distributions import BetaBinomial
from numba import jit
69.1.1. 前置知识#
在学习本讲义内容之前,我们建议先阅读有限马尔可夫链讲座。
此外,你还需要具备一些线性代数和概率论的基础知识。
69.2. 模型#
假设经济体中存在大量的事前同质的劳动者
这些劳动者被设定为寿命无限,并且不断地在失业与就业之间转换。
就业与失业之间的转换由以下几个参数所刻画:
\(\lambda\):当前失业者的求职成功率
\(\alpha\):当前就业者的解雇率
\(b\):劳动力市场进入率
\(d\):劳动力市场退出率
劳动力的增长率显然等于 \(g=b-d\)。
69.2.1. 总量变量#
我们想要推导以下总量变量的动态演化:
\(E_t\):\(t\) 时刻的就业者总数
\(U_t\):\(t\) 时刻的失业者总数
\(N_t\):\(t\) 时刻的劳动力总数
此外,我们还关心以下比率变量的值:
就业率 \(e_t := E_t/N_t\)
失业率 \(u_t := U_t/N_t\)
(在这里及下文中,大写字母代表总量,小写字母代表比率)
69.2.2. 存量变量的运动规律#
我们首先构建总量变量 \(E_t,U_t, N_t\) 的运动规律。
对于 \(t\) 时刻就业的劳动者群体 \(E_t\):
\((1-d)E_t\) 将留在劳动力市场中
其中,\((1-\alpha)(1-d)E_t\) 将保持就业
对于 \(t\) 时刻失业的劳动者群体 \(U_t\):
\((1-d)U_t\) 将留在劳动力市场中
其中,\((1-d) \lambda U_t\) 将找到工作
因此,\(t+1\) 时刻的就业者总量是:
类似地,
其中,\(b(E_t+U_t)\) 表示新进入劳动力市场且尚未就业的个体数量。
劳动者总量 \(N_t=E_t+U_t\) 的演变如下:
令 \(X_t := \left(\begin{matrix}U_t\\E_t\end{matrix}\right)\),其运动规律为:
该动态系统清晰地描述了总失业量与就业量随时间演化的规律。
69.2.3. 比率的运动规律#
现在让我们推导比率的运动规律。
我们可以将 \(X_{t+1} = A X_t\) 的两边都除以 \(N_{t+1}\) 得到:
令
我们也可以将其写为
可以验证,由于\(e_t + u_t = 1\),因此 \(e_{t+1}+u_{t+1} = 1\)。
这一结果来源于矩阵 \(\hat A\) 的各列之和为1。
69.3. 实现#
让我们将这些方程编写成代码。
为此,我们将使用一个名为 LakeModel 的类。
该类将:
存储原始参数 \(\alpha, \lambda, b, d\)
计算并存储派生变量 \(g, A, \hat A\)
提供用于模拟存量变量与比率变量动态的函数
提供一个用于计算就业和失业率稳态向量 \(\bar x\) 的方法,该方法使用了我们之前在计算马尔可夫链平稳分布时介绍过的一种技术
请注意,如果只改变原始参数,派生变量 \(g, A, \hat A\) 不会自动更新。
例如,若要更新某个基本参数,如 \(\alpha = 0.03\),需要通过 lm = LakeModel(α=0.03) 创建一个新实例。
在练习部分,我们将展示如何使用getter和setter方法来避免这个问题。
class LakeModel:
"""
求解湖泊模型并计算失业存量和比率的动态。
参数:
------------
λ : 标量
当前失业劳动者的工作找到率
α : 标量
当前就业劳动者的解雇率
b : 标量
劳动力进入率
d : 标量
劳动力退出率
"""
def __init__(self, λ=0.283, α=0.013, b=0.0124, d=0.00822):
self.λ, self.α, self.b, self.d = λ, α, b, d
λ, α, b, d = self.λ, self.α, self.b, self.d
self.g = b - d
self.A = np.array([[(1-d) * (1-λ) + b, (1 - d) * α + b],
[ (1-d) * λ, (1 - d) * (1 - α)]])
self.A_hat = self.A / (1 + self.g)
def rate_steady_state(self, tol=1e-6):
"""
找到系统 :math:`x_{t+1} = \hat A x_{t}` 的稳态
返回
--------
xbar : 就业和失业率的稳态向量
"""
x = np.array([self.A_hat[0, 1], self.A_hat[1, 0]])
x /= x.sum()
return x
def simulate_stock_path(self, X0, T):
"""
模拟就业和失业存量的序列
参数
------------
X0 : 数组
包含初始值 (E0, U0)
T : 整数
模拟的时期数
返回
---------
X : 迭代器
包含就业和失业存量的序列
"""
X = np.atleast_1d(X0) # 转换为数组以防万一
for t in range(T):
yield X
X = self.A @ X
def simulate_rate_path(self, x0, T):
"""
模拟就业和失业率的序列
参数
------------
x0 : 数组
包含初始值 (e0,u0)
T : 整数
模拟的时期数
返回
---------
x : 迭代器
包含就业和失业率的序列
"""
x = np.atleast_1d(x0) # 转换为数组以防万一
for t in range(T):
yield x
x = self.A_hat @ x
如前所述,如果我们创建一个实例并通过 lm = LakeModel(α=0.03) 更新它,
派生变量如 \(A\) 也会改变。
lm = LakeModel()
lm.α
0.013
lm.A
array([[0.72350626, 0.02529314],
[0.28067374, 0.97888686]])
lm = LakeModel(α = 0.03)
lm.A
array([[0.72350626, 0.0421534 ],
[0.28067374, 0.9620266 ]])
69.3.1. 总量动态#
让我们在默认参数下(见上文)从 \(X_0 = (12, 138)\) 开始模拟
lm = LakeModel()
N_0 = 150 # 人口
e_0 = 0.92 # 初始就业率
u_0 = 1 - e_0 # 初始失业率
T = 50 # 模拟长度
U_0 = u_0 * N_0
E_0 = e_0 * N_0
fig, axes = plt.subplots(3, 1, figsize=(10, 8))
X_0 = (U_0, E_0)
X_path = np.vstack(tuple(lm.simulate_stock_path(X_0, T)))
axes[0].plot(X_path[:, 0], lw=2)
axes[0].set_title('失业')
axes[1].plot(X_path[:, 1], lw=2)
axes[1].set_title('就业')
axes[2].plot(X_path.sum(1), lw=2)
axes[2].set_title('劳动力')
for ax in axes:
ax.grid()
plt.tight_layout()
plt.show()
总量 \(E_t\) 和 \(U_t\) 不会收敛,因为它们的和 \(E_t + U_t\) 以速率 \(g\) 增长。
另一方面,就业和失业率向量 \(x_t\) 可以达到稳态 \(\bar x\),如果存在 \(\bar x\) 使得:
\(\bar x = \hat A \bar x\)
分量满足 \(\bar e + \bar u = 1\)
这个方程告诉我们稳态水平 \(\bar x\) 是 \(\hat A\) 与单位特征值相对应的的特征向量。
如果 \(\hat A\) 的其余特征值的模小于1,我们有 \(x_t \to \bar x\) 当 \(t \to \infty\)。
对于我们的默认参数,确实满足这一情况:
lm = LakeModel()
e, f = np.linalg.eigvals(lm.A_hat)
abs(e), abs(f)
(np.float64(0.6953067378358462), np.float64(1.0))
让我们看看失业率和就业率如何收敛到稳态水平(虚线红色)
lm = LakeModel()
e_0 = 0.92 # 初始就业率
u_0 = 1 - e_0 # 初始失业率
T = 50 # 模拟长度
xbar = lm.rate_steady_state()
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
x_0 = (u_0, e_0)
x_path = np.vstack(tuple(lm.simulate_rate_path(x_0, T)))
titles = ['失业率', '就业率']
for i, title in enumerate(titles):
axes[i].plot(x_path[:, i], lw=2, alpha=0.5)
axes[i].hlines(xbar[i], 0, T, 'r', '--')
axes[i].set_title(title)
axes[i].grid()
plt.tight_layout()
plt.show()
69.4. 单个劳动者的动态#
单个劳动者的就业动态由有限状态马尔可夫过程控制。
劳动者可以处于两种状态之一:
\(s_t=0\) 表示失业
\(s_t=1\) 表示就业
让我们首先假设 \(b = d = 0\)。
相关的转移矩阵为:
令 \(\psi_t\) 表示劳动者在 \(t\) 时刻就业/失业状态的边际分布。
像往常一样,我们将其视为行向量。
我们从之前的讨论中知道 \(\psi_t\) 遵循运动规律:
我们还从有限马尔可夫链讲义中知道,如果 \(\alpha \in (0, 1)\) 和 \(\lambda \in (0, 1)\),则 \(P\) 有唯一的平稳分布,这里记为 \(\psi^*\)。
唯一的平稳分布满足:
这不足为奇:失业状态的概率随着解雇率增加而增加,随着求职成功率增加而减少。
69.4.1. 遍历性#
让我们考察一个典型的就业–失业历程。
我们希望计算一个寿命无限的劳动者在就业与失业状态中所花费时间的平均比例。
令
以及
(像往常一样,\(\mathbb 1\{Q\} = 1\) 如果陈述 \(Q\) 为真,否则为0)
这些是劳动者在 \(T\) 时期之前分别花费在失业和就业上的时间比例。
如果 \(\alpha \in (0, 1)\) 且 \(\lambda \in (0, 1)\),则 \(P\) 是遍历的,因此我们有:
以概率 1 成立。
可以看出,在假设 \(b=d=0\) 下,\(P\) 正好是 \(\hat A\) 的转置。
因此,无限寿命劳动者花费在就业和失业上的时间百分比等于稳态分布中的就业和失业劳动者比例。
69.4.2. 收敛率#
时间序列样本平均值需要多长时间才能收敛到横截面平均值?
我们可以使用QuantEcon.py的 MarkovChain类来研究这个问题。
让我们绘制5000个时期的样本平均值路径
lm = LakeModel(d=0, b=0)
T = 5000 # 模拟长度
α, λ = lm.α, lm.λ
P = [[1 - λ, λ],
[ α, 1 - α]]
mc = MarkovChain(P)
xbar = lm.rate_steady_state()
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
s_path = mc.simulate(T, init=1)
s_bar_e = s_path.cumsum() / range(1, T+1)
s_bar_u = 1 - s_bar_e
to_plot = [s_bar_u, s_bar_e]
titles = ['失业时间百分比', '就业时间百分比']
for i, plot in enumerate(to_plot):
axes[i].plot(plot, lw=2, alpha=0.5)
axes[i].hlines(xbar[i], 0, T, 'r', '--')
axes[i].set_title(titles[i])
axes[i].grid()
plt.tight_layout()
plt.show()
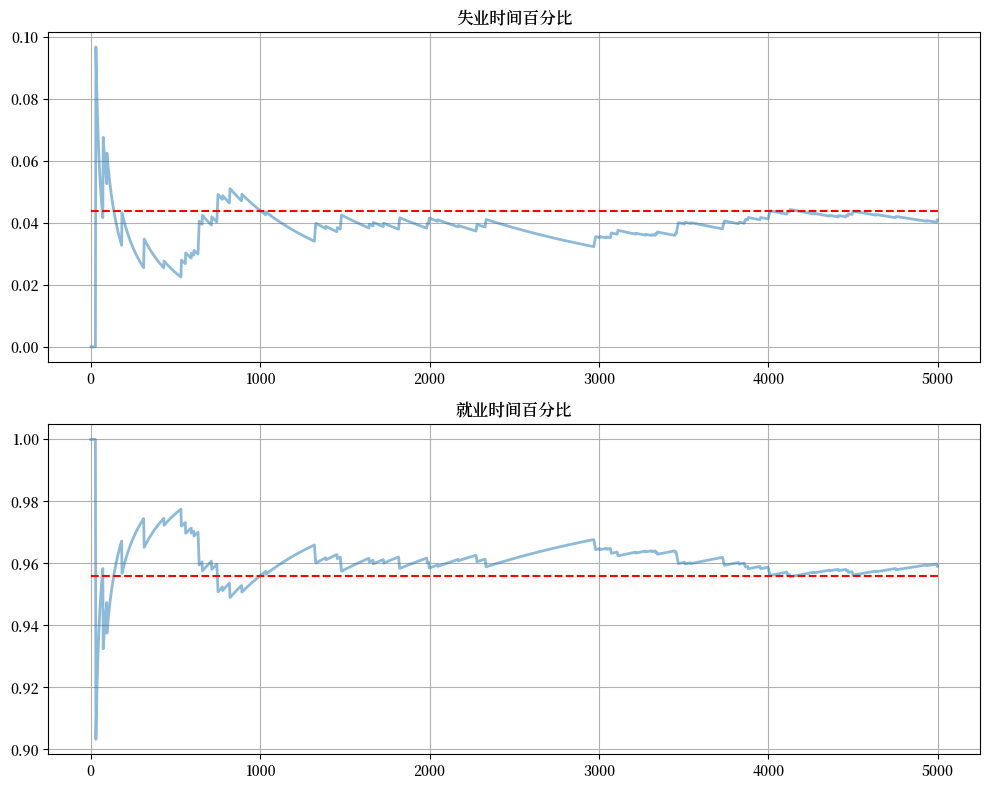
平稳概率由虚线红色给出。
在这种情况下,这两个对象需要很长时间才能收敛。
这主要是由于马尔可夫链的高持久性。
69.5. 内生求职成功率#
我们现在使雇佣率内生化。
从失业到就业的转换率将由McCall搜索模型[McCall, 1970]决定。
与以下讨论相关的所有细节都可以在我们对该模型的讨论中找到。
69.5.1. 保留工资#
关于这个模型要记住的最重要的事情是,最优决策由保留工资 \(\bar w\) 表征:
如果手中的工资报价 \(w\) 大于或等于 \(\bar w\),则劳动者接受。
否则,劳动者拒绝。
正如我们在模型讨论中看到的,保留工资取决于工资报价分布和参数:
\(\alpha\):离职率
\(\beta\):贴现因子
\(\gamma\):报价到达率
\(c\):失业补偿
69.5.2. 将McCall搜索模型与湖泊模型联系起来#
假设湖泊模型中的所有劳动者都按照McCall搜索模型行事。
离职的外生概率仍为 \(\alpha\)。
但他们的最优决策规则决定了脱离失业状态的概率 \(\lambda\)。
此时有
69.5.3. 财政政策#
我们可以使用McCall搜索版本的湖泊模型来找到最优的失业保险水平。
我们假设政府设定失业补偿 \(c\)。
政府征收一次性税收 \(\tau\) 以支付总失业金。
为了在稳态下实现预算平衡,税收、稳态失业率 \(u\) 和失业补偿率必须满足:
一次性税收适用于所有人,包括失业劳动者。
因此,工资为 \(w\) 的就业劳动者的税后收入为 \(w - \tau\)。
失业劳动者的税后收入为 \(c - \tau\)。
对于每一种政府政策的设定 \((c, \tau)\),我们可以求解劳动者的最优保留工资。
通过(69.1),这一保留工资决定了税后工资下的 \(\lambda\),进而决定了稳态失业率 \(u(c, \tau)\)。
对于给定的失业补偿水平 \(c\),我们可以求解在稳态下实现预算平衡的税收
为了比较不同政府税收与失业补偿组合方案,我们需要一个福利准则。
我们使用稳态福利准则
其中符号 \(V\) 和 \(U\) 如McCall搜索模型讲义中所定义。
工资报价分布将采用对数正态分布 \(LN(\log(20),1)\) 的离散化版本,如下图所示:
def create_wage_distribution(max_wage: float,
wage_grid_size: int,
log_wage_mean: float):
"""Create wage distribution"""
w_vec_temp = np.linspace(1e-8, max_wage,
wage_grid_size + 1)
cdf = stats.norm.cdf(np.log(w_vec_temp),
loc=np.log(log_wage_mean), scale=1)
pdf = cdf[1:] - cdf[:-1]
p_vec = pdf / pdf.sum()
w_vec = (w_vec_temp[1:] + w_vec_temp[:-1]) / 2
return w_vec, p_vec
w_vec, p_vec = create_wage_distribution(170, 200, 20)
fig, ax = plt.subplots()
ax.plot(w_vec, p_vec)
ax.set_xlabel('工资')
ax.set_ylabel('概率')
plt.tight_layout()
plt.show()
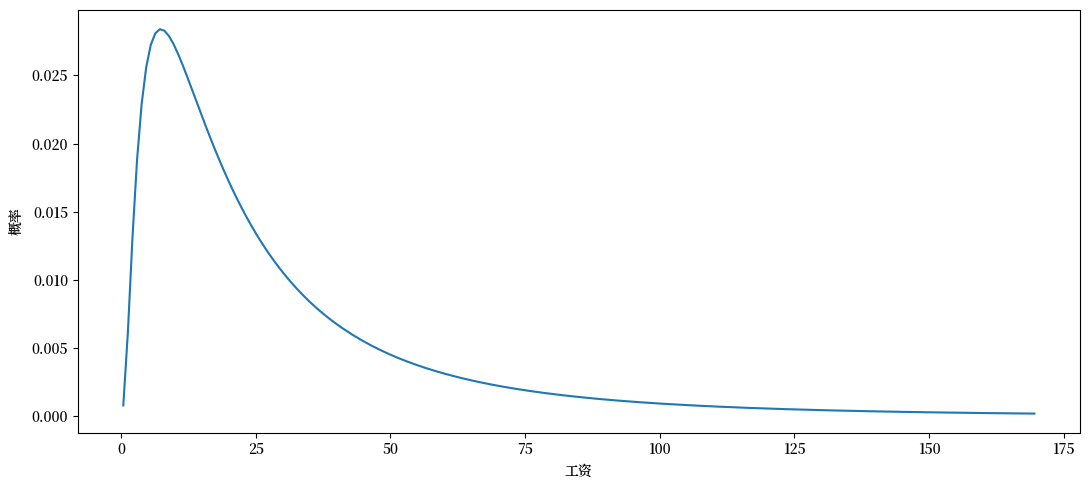
我们将一个时期设为一个月。
设定参数 \(b\) 和 \(d\) 分别为美国人口的月度出生率和死亡率率:
\(b = 0.0124\)
\(d = 0.00822\)
根据[Davis et al., 2006],我们将离职率 \(\alpha\) 设定为
\(\alpha = 0.013\)
69.5.4. 财政政策代码#
我们将使用来自McCall模型讲义的技术
第一段代码实现了价值函数迭代
# 默认效用函数
@jit
def u(c, σ):
if c > 0:
return (c**(1 - σ) - 1) / (1 - σ)
else:
return -10e6
class McCallModel:
"""
存储与给定模型相关的参数和函数。
"""
def __init__(self,
α=0.2, # 工作分离率
β=0.98, # 贴现率
γ=0.7, # 工作报价率
c=6.0, # 失业补偿
σ=2.0, # 效用参数
w_vec=None, # 可能的工资值
p_vec=None): # w_vec上的概率
self.α, self.β, self.γ, self.c = α, β, γ, c
self.σ = σ
# 使用beta-二项分布添加默认工资向量和概率
if w_vec is None:
n = 60 # 工资的可能结果数
# 工资在10到20之间
self.w_vec = np.linspace(10, 20, n)
a, b = 600, 400 # 形状参数
dist = BetaBinomial(n-1, a, b)
self.p_vec = dist.pdf()
else:
self.w_vec = w_vec
self.p_vec = p_vec
@jit
def _update_bellman(α, β, γ, c, σ, w_vec, p_vec, V, V_new, U):
"""
更新贝尔曼方程的jitted函数。注意V_new是
就地修改的(即由这个函数修改)。U的新值
被返回。
"""
for w_idx, w in enumerate(w_vec):
# w_idx索引可能的工资向量
V_new[w_idx] = u(w, σ) + β * ((1 - α) * V[w_idx] + α * U)
U_new = u(c, σ) + β * (1 - γ) * U + \
β * γ * np.sum(np.maximum(U, V) * p_vec)
return U_new
def solve_mccall_model(mcm, tol=1e-5, max_iter=2000):
"""
迭代收敛到贝尔曼方程
参数
----------
mcm : McCallModel的实例
tol : 浮点数
误差容限
max_iter : 整数
最大迭代次数
"""
V = np.ones(len(mcm.w_vec)) # V的初始猜测
V_new = np.empty_like(V) # 存储V的更新
U = 1 # U的初始猜测
i = 0
error = tol + 1
while error > tol and i < max_iter:
U_new = _update_bellman(mcm.α, mcm.β, mcm.γ,
mcm.c, mcm.σ, mcm.w_vec, mcm.p_vec, V, V_new, U)
error_1 = np.max(np.abs(V_new - V))
error_2 = np.abs(U_new - U)
error = max(error_1, error_2)
V[:] = V_new
U = U_new
i += 1
return V, U
第二段代码用于完成保留工资:
def compute_reservation_wage(mcm, return_values=False):
"""
通过找到最小的w使得V(w) > U来计算McCall模型的保留工资。
如果V(w) > U对所有w都成立,则保留工资w_bar被设置为
mcm.w_vec中的最低工资。
如果v(w) < U对所有w都成立,则w_bar被设置为np.inf。
参数
----------
mcm : McCallModel的实例
return_values : 布尔值(可选,默认=False)
也返回价值函数
返回
-------
w_bar : 标量
保留工资
"""
V, U = solve_mccall_model(mcm)
w_idx = np.searchsorted(V - U, 0)
if w_idx == len(V):
w_bar = np.inf
else:
w_bar = mcm.w_vec[w_idx]
if return_values == False:
return w_bar
else:
return w_bar, V, U
现在让我们计算并绘制福利、就业、失业和税收收入,作为失业补偿的函数。
# 一些将保持不变的全局变量
α = 0.013
α_q = (1-(1-α)**3) # 季度(α是月度)
b = 0.0124
d = 0.00822
β = 0.98
γ = 1.0
σ = 2.0
def compute_optimal_quantities(c, τ):
"""
给定c和τ计算劳动者的保留工资、工作找到率和价值函数。
"""
mcm = McCallModel(α=α_q,
β=β,
γ=γ,
c=c-τ, # 税后补偿
σ=σ,
w_vec=w_vec-τ, # 税后工资
p_vec=p_vec)
w_bar, V, U = compute_reservation_wage(mcm, return_values=True)
λ = γ * np.sum(p_vec[w_vec - τ > w_bar])
return w_bar, λ, V, U
def compute_steady_state_quantities(c, τ):
"""
使用McCall模型的最优数量计算给定c和τ的稳态失业率
并计算相应的稳态数量
"""
w_bar, λ, V, U = compute_optimal_quantities(c, τ)
# 计算稳态就业和失业率
lm = LakeModel(α=α_q, λ=λ, b=b, d=d)
x = lm.rate_steady_state()
u, e = x
# 计算稳态福利
w = np.sum(V * p_vec * (w_vec - τ > w_bar)) / np.sum(p_vec * (w_vec -
τ > w_bar))
welfare = e * w + u * U
return e, u, welfare
def find_balanced_budget_tax(c):
"""
找到将导致预算平衡的税收水平。
"""
def steady_state_budget(t):
e, u, w = compute_steady_state_quantities(c, t)
return t - u * c
τ = brentq(steady_state_budget, 0.0, 0.9 * c)
return τ
# 我们想要研究的失业保险水平
c_vec = np.linspace(5, 140, 60)
tax_vec = []
unempl_vec = []
empl_vec = []
welfare_vec = []
for c in c_vec:
t = find_balanced_budget_tax(c)
e_rate, u_rate, welfare = compute_steady_state_quantities(c, t)
tax_vec.append(t)
unempl_vec.append(u_rate)
empl_vec.append(e_rate)
welfare_vec.append(welfare)
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
plots = [unempl_vec, empl_vec, tax_vec, welfare_vec]
titles = ['失业', '就业', '税收', '福利']
for ax, plot, title in zip(axes.flatten(), plots, titles):
ax.plot(c_vec, plot, lw=2, alpha=0.7)
ax.set_title(title)
ax.grid()
plt.tight_layout()
plt.show()
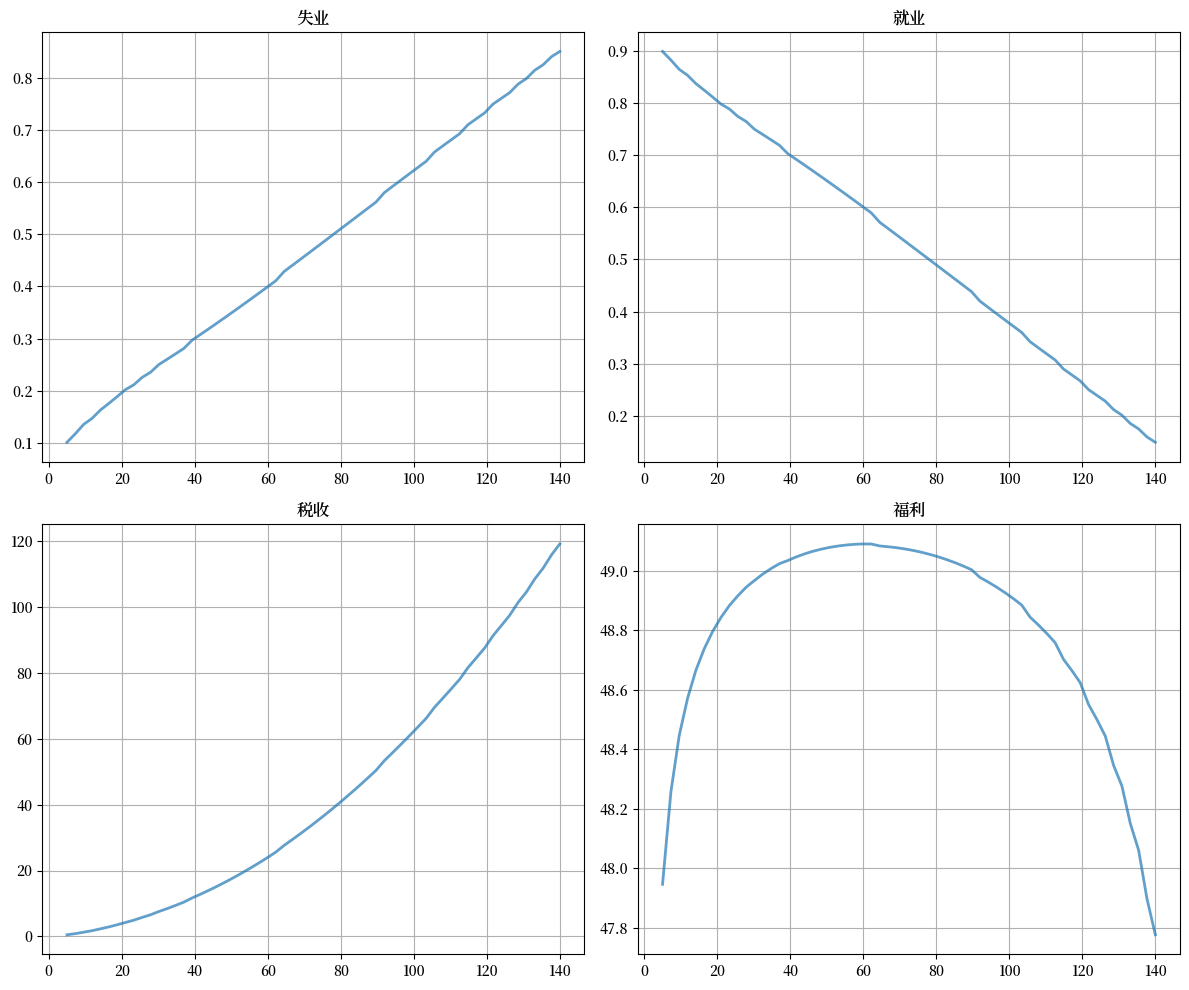
福利首先增加然后随着失业补充的增加而减少。
使稳态福利最大化的水平约为62。
69.6. 练习#
练习 69.1
在湖泊模型中,有一些派生数据如 \(A\),它依赖于原始参数如 \(\alpha\) 和 \(\lambda\)。
因此,当用户改变这些原始参数时,我们需要派生数据能够自动更新。
(例如,如果用户改变给定类实例的 \(b\) 值,我们希望 \(g = b - d\) 自动更新)
在上面的代码中,我们通过在每次想要改变参数时创建新实例来解决这个问题。
这样派生数据总是与当前参数值匹配。
但是,我们也可以使用描述符来实现,只要参数发生变化,派生数据即可自动更新。
这种方法更加安全,也无需在每次参数化时重新创建新的实例。
(另一方面,代码变得更密集,这就是为什么我们在讲座中并不总是使用描述符方法。)
在这个练习中,您的任务是使用描述符和装饰器(如 @property)来重构 LakeModel 类。
(如果您需要复习相关内容,请参阅本讲义。)
解答 练习 69.1
参考答案
class LakeModelModified:
"""
求解湖泊模型并计算失业存量和比率的动态。
参数:
------------
λ : 标量
当前失业劳动者的工作找到率
α : 标量
当前就业劳动者的解雇率
b : 标量
劳动力进入率
d : 标量
劳动力退出率
"""
def __init__(self, λ=0.283, α=0.013, b=0.0124, d=0.00822):
self._λ, self._α, self._b, self._d = λ, α, b, d
self.compute_derived_values()
def compute_derived_values(self):
# 解包名称以简化表达式
λ, α, b, d = self._λ, self._α, self._b, self._d
self._g = b - d
self._A = np.array([[(1-d) * (1-λ) + b, (1 - d) * α + b],
[ (1-d) * λ, (1 - d) * (1 - α)]])
self._A_hat = self._A / (1 + self._g)
@property
def g(self):
return self._g
@property
def A(self):
return self._A
@property
def A_hat(self):
return self._A_hat
@property
def λ(self):
return self._λ
@λ.setter
def λ(self, new_value):
self._λ = new_value
self.compute_derived_values()
@property
def α(self):
return self._α
@α.setter
def α(self, new_value):
self._α = new_value
self.compute_derived_values()
@property
def b(self):
return self._b
@b.setter
def b(self, new_value):
self._b = new_value
self.compute_derived_values()
@property
def d(self):
return self._d
@d.setter
def d(self, new_value):
self._d = new_value
self.compute_derived_values()
def rate_steady_state(self, tol=1e-6):
r"""
找到系统 :math:`x_{t+1} = \hat A x_{t}` 的稳态
返回
--------
xbar : 就业和失业率的稳态向量
"""
x = np.array([self.A_hat[0, 1], self.A_hat[1, 0]])
x /= x.sum()
return x
def simulate_stock_path(self, X0, T):
"""
模拟就业和失业存量的序列
参数
------------
X0 : 数组
包含初始值 (E0, U0)
T : 整数
模拟的时期数
返回
---------
X : 迭代器
包含就业和失业存量的序列
"""
X = np.atleast_1d(X0) # 转换为数组以防万一
for t in range(T):
yield X
X = self.A @ X
def simulate_rate_path(self, x0, T):
"""
模拟就业和失业率的序列
参数
------------
x0 : 数组
包含初始值 (e0,u0)
T : 整数
模拟的时期数
返回
---------
x : 迭代器
包含就业和失业率的序列
"""
x = np.atleast_1d(x0) # 转换为数组以防万一
for t in range(T):
yield x
x = self.A_hat @ x
练习 69.2
考虑一个经济体,其初始劳动力存量为 \(N_0 = 100\),并处于基准参数化下的稳态就业水平:
\(\alpha = 0.013\)
\(\lambda = 0.283\)
\(b = 0.0124\)
\(d = 0.00822\)
(\(\alpha\) 和 \(\lambda\) 的取值参考[Davis et al., 2006])
假设由于新的立法,雇佣率下降至 \(\lambda = 0.2\)。
绘制50个时期的失业和就业存量的转换动态。
绘制比率的转换动态。
经济需要多长时间才能收敛到新的稳态?
新的稳态就业水平是多少?
备注
使用练习1中创建的类可能更容易帮助改变变量。
解答 练习 69.2
我们首先构建包含默认参数的类并将稳态值分配给 x0
lm = LakeModelModified()
x0 = lm.rate_steady_state()
print(f"初始稳态: {x0}")
初始稳态: [0.08266627 0.91733373]
初始化模拟值
N0 = 100
T = 50
新立法将 \(\lambda\) 改变为 \(0.2\)
lm.λ = 0.2
xbar = lm.rate_steady_state() # 新稳态
X_path = np.vstack(tuple(lm.simulate_stock_path(x0 * N0, T)))
x_path = np.vstack(tuple(lm.simulate_rate_path(x0, T)))
print(f"新稳态: {xbar}")
新稳态: [0.11309295 0.88690705]
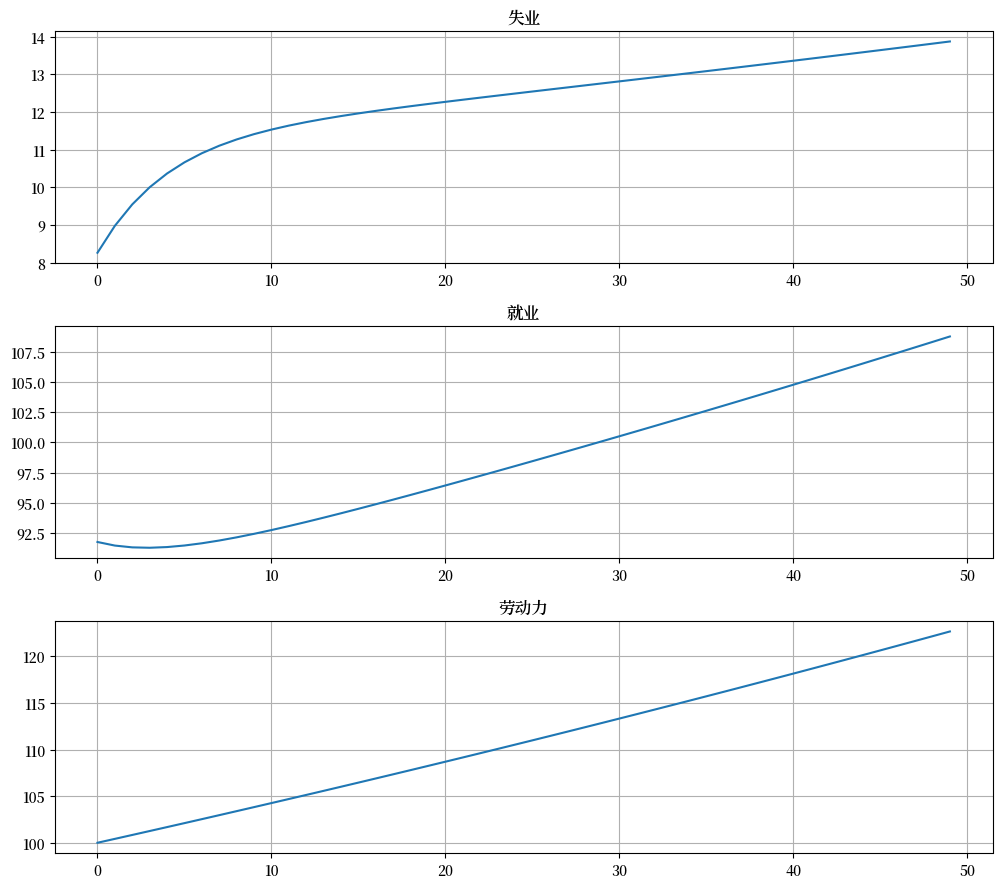
现在绘制存量
fig, axes = plt.subplots(3, 1, figsize=[10, 9])
axes[0].plot(X_path[:, 0])
axes[0].set_title('失业')
axes[1].plot(X_path[:, 1])
axes[1].set_title('就业')
axes[2].plot(X_path.sum(1))
axes[2].set_title('劳动力')
for ax in axes:
ax.grid()
plt.tight_layout()
plt.show()
以及比率如何演变
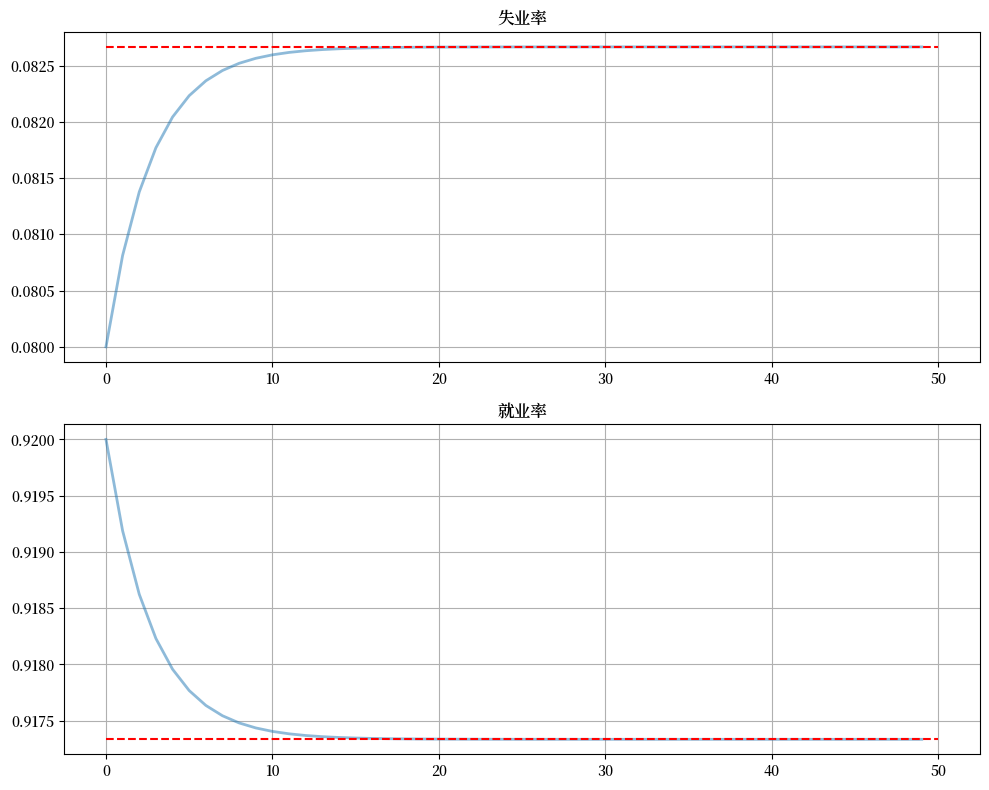
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
titles = ['失业率', '就业率']
for i, title in enumerate(titles):
axes[i].plot(x_path[:, i])
axes[i].hlines(xbar[i], 0, T, 'r', '--')
axes[i].set_title(title)
axes[i].grid()
plt.tight_layout()
plt.show()
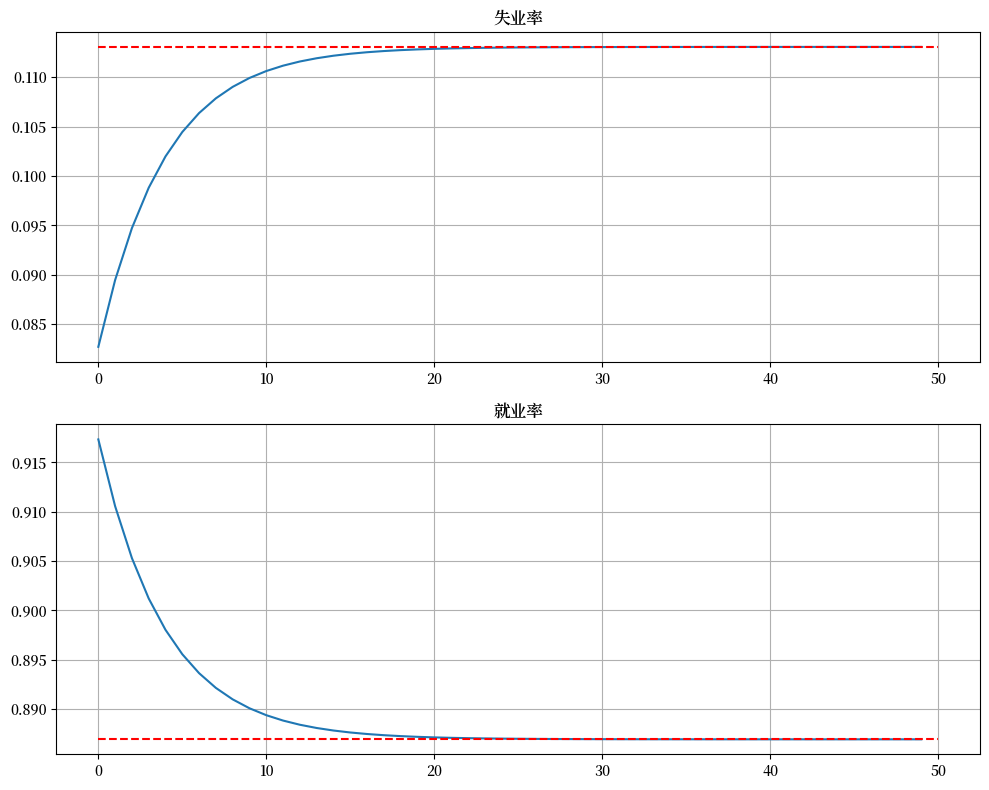
我们可以看到,经济体需要 20 个时期收敛到新的稳态水平。
练习 69.3
考虑一个经济体,其初始劳动者存量为 \(N_0 = 100\),且处于基准参数化下的稳态就业水平。
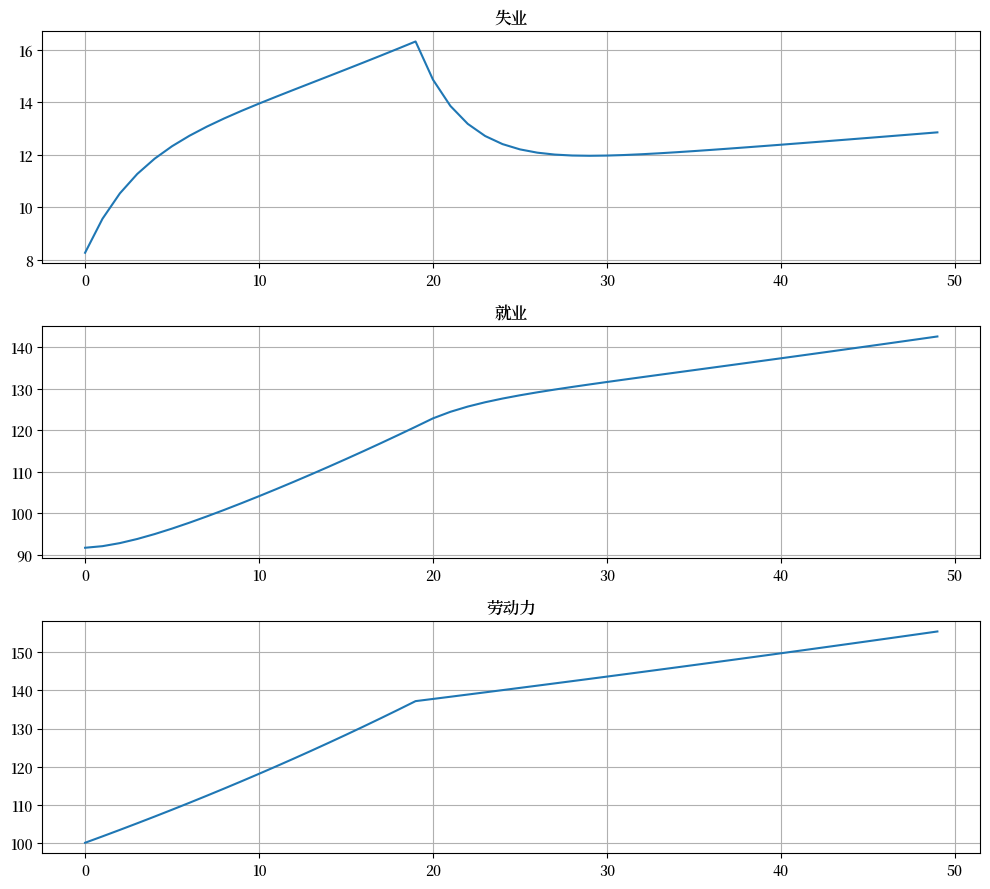
假设在前 20 期内出生率暂时升高(\(b = 0.025\)),然后恢复到原始水平。
绘制50个时期的失业和就业存量的转换动态。
绘制比率的转换动态。
经济需要多长时间才能恢复到原始稳态?
解答 练习 69.3
本练习模拟了一个经济体经历劳动力市场进入量激增的情形,随后又回到原有水平。
在前 20 期内,经济体具有新的劳动力市场进入率。
让我们从基准参数化开始,并记录其稳态。
lm = LakeModelModified()
x0 = lm.rate_steady_state()
这是其他参数:
b_hat = 0.025
T_hat = 20
让我们将 \(b\) 增加到新值并模拟 20 个时期
lm.b = b_hat
# 模拟存量
X_path1 = np.vstack(tuple(lm.simulate_stock_path(x0 * N0, T_hat)))
# 模拟比率
x_path1 = np.vstack(tuple(lm.simulate_rate_path(x0, T_hat)))
现在我们将 \(b\) 重置为原始值,然后使用 20 个时期后的状态作为新的初始条件,模拟额外的30 个时期
lm.b = 0.0124
# 模拟存量
X_path2 = np.vstack(tuple(lm.simulate_stock_path(X_path1[-1, :2], T-T_hat+1)))
# 模拟比率
x_path2 = np.vstack(tuple(lm.simulate_rate_path(x_path1[-1, :2], T-T_hat+1)))
最后,我们将这两条路径组合并绘制
# 注意[1:]以避免重复第20期
x_path = np.vstack([x_path1, x_path2[1:]])
X_path = np.vstack([X_path1, X_path2[1:]])
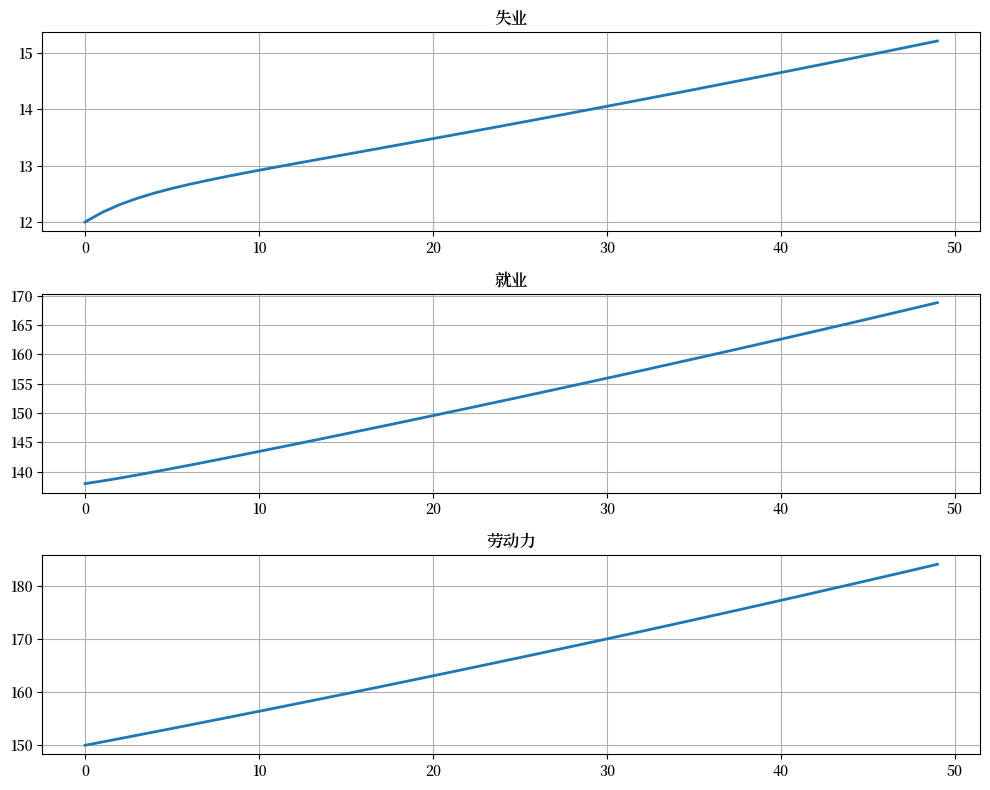
fig, axes = plt.subplots(3, 1, figsize=[10, 9])
axes[0].plot(X_path[:, 0])
axes[0].set_title('失业')
axes[1].plot(X_path[:, 1])
axes[1].set_title('就业')
axes[2].plot(X_path.sum(1))
axes[2].set_title('劳动力')
for ax in axes:
ax.grid()
plt.tight_layout()
plt.show()
以及比率
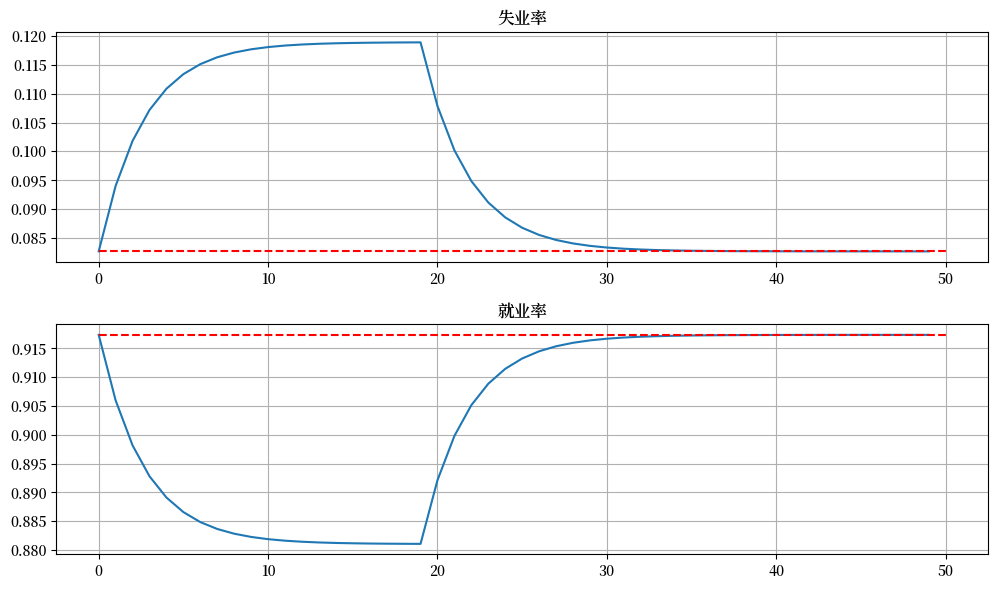
fig, axes = plt.subplots(2, 1, figsize=[10, 6])
titles = ['失业率', '就业率']
for i, title in enumerate(titles):
axes[i].plot(x_path[:, i])
axes[i].hlines(x0[i], 0, T, 'r', '--')
axes[i].set_title(title)
axes[i].grid()
plt.tight_layout()
plt.show()