44. 工作搜寻 III: 拟合值函数迭代#
44.1. 概述#
在本讲座中,我们再次研究带有离职情形的McCall工作搜寻模型,但这次会使用连续工资分布。
虽然我们在第一个工作搜寻讲座的练习中已经简要讨论过连续工资分布,但在那个案例中,这种改变相对来说是微不足道的。
这是因为我们能够将问题简化为求解单个标量值,即延续价值。
在这一讲座中,由于离职情形的存在,变化不再那么简单,因为连续工资分布会导致不可数的无限状态空间。
无限状态空间带来了额外的问题,特别是在应用值函数迭代(VFI)时。
这些问题会促使我们通过添加插值这一步骤,来改进VFI方法。
VFI和这个插值步骤的结合被称为拟合值函数迭代(拟合 VFI)。
拟合VFI在实践中非常常见,所以我们将花一些时间来详细研究。
我们将使用以下导入:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
import numpy as np
from numba import jit, float64
from numba.experimental import jitclass
44.2. 算法#
该模型与我们之前学习的带有离职情形的McCall模型相同,除了工资分布是连续的。
我们将从{ref}经简化变换 <ast_mcm>后得到的两个贝尔曼方程入手。
为了适应连续工资抽样,这两个方程呈现以下形式:
以及
这里的未知量是函数\(v\)和标量\(d\)。
这些方程与我们之前处理的一对贝尔曼方程的区别在于:
函数 \(q\) 在 (44.1) 中是工资分布的概率密度函数。
其支撑集等于 \(\mathbb R_+\)。
44.2.1. 值函数迭代#
理论上,我们应该按以下步骤进行:
若未满足某些终止条件,则令 \((v, d) = (v', d')\) 并返回步骤2。
然而,在实施这个算法之前,我们必须面对一个问题: 值函数的迭代序列既不能被精确计算,也不能被存储在计算机中。
要理解这个问题,请考察 (44.2)。
即使 \(v\) 是一个已知函数,存储其更新值 \(v'\) 的唯一方法 是记录其在每个 \(w \in \mathbb R_+\) 处的值 \(v'(w)\)。
显然,这是不可能的。
44.2.2. 拟合值函数迭代#
我们将改用拟合值函数迭代的方法。
具体步骤如下:
假设当前给定猜测值函数 \(v\)。
我们只在有限个”网格”点 \(w_1 < w_2 < \cdots < w_I\) 上记录函数 \(v'\) 的值,然后在需要时根据这些信息重构 \(v'\)。
更具体地说,这个算法是
从一个数组 \(\mathbf v\) 开始,该数组表示值函数在某些网格点 \(\{w_i\}\) 上的初始猜测值。
基于 \(\mathbf v\) 和 \(\{w_i\}\),通过插值法或近似法在状态空间 \(\mathbb R_+\) 上构建函数 \(v\)。
在每个网格点 \(w_i\) 上获取并记录更新后的函数 \(v'(w_i)\) 的样本。
若未满足某些停止条件,则将其作为新数组并返回步骤1。
我们应该如何处理步骤2?
这是一个函数近似问题,有很多种方法可以解决。
对于函数近似方案,我们需要考虑两个关键点:一是要能够准确地近似每个\(v\),二是要能够有效地融入到整个迭代算法中。
从这两个方面来看,连续分段线性插值法是一个不错的选择。
这种方法
能够很好地配合值函数迭代(参见[Gordon, 1995]或[Stachurski, 2008])
能保持关键的形状特性,如单调性和凹凸性。
线性插值将通过numpy.interp来实现。
下图展示了在网格点\(0, 0.2, 0.4, 0.6, 0.8, 1\)上对任意函数进行分段线性插值的情况。
def f(x):
y1 = 2 * np.cos(6 * x) + np.sin(14 * x)
return y1 + 2.5
c_grid = np.linspace(0, 1, 6)
f_grid = np.linspace(0, 1, 150)
def Af(x):
return np.interp(x, c_grid, f(c_grid))
fig, ax = plt.subplots()
ax.plot(f_grid, f(f_grid), 'b-', label='真实函数')
ax.plot(f_grid, Af(f_grid), 'g-', label='线性近似')
ax.vlines(c_grid, c_grid * 0, f(c_grid), linestyle='dashed', alpha=0.5)
ax.legend(loc="upper center")
ax.set(xlim=(0, 1), ylim=(0, 6))
plt.show()

44.3. 实现#
第一步,是为具有离职情况和连续工资分布的McCall模型构建一个jit类。
在这个应用中,我们将效用函数设定为对数函数,即\(u(c) = \ln c\)。
我们将采用对数正态分布来描述工资水平,其具体形式为\(w = \exp(\mu + \sigma z)\),其中\(z\)服从标准正态分布,\(\mu, \sigma\)为模型参数。
@jit
def lognormal_draws(n=1000, μ=2.5, σ=0.5, seed=1234):
np.random.seed(seed)
z = np.random.randn(n)
w_draws = np.exp(μ + σ * z)
return w_draws
以下是类的定义:
mccall_data_continuous = [
('c', float64), # 失业补偿
('α', float64), # 离职率
('β', float64), # 折现因子
('w_grid', float64[:]), # 用于拟合VFI的网格点
('w_draws', float64[:]) # 用于蒙特卡洛方法的工资抽样
]
@jitclass(mccall_data_continuous)
class McCallModelContinuous:
def __init__(self,
c=1,
α=0.1,
β=0.96,
grid_min=1e-10,
grid_max=5,
grid_size=100,
w_draws=lognormal_draws()):
self.c, self.α, self.β = c, α, β
self.w_grid = np.linspace(grid_min, grid_max, grid_size)
self.w_draws = w_draws
def update(self, v, d):
# 简化名称
c, α, β = self.c, self.α, self.β
w = self.w_grid
u = lambda x: np.log(x)
# 对用数组表示的值函数进行插值
vf = lambda x: np.interp(x, w, v)
# 使用蒙特卡洛方法进行积分估值来更新d
d_new = np.mean(np.maximum(vf(self.w_draws), u(c) + β * d))
# 更新v
v_new = u(w) + β * ((1 - α) * v + α * d)
return v_new, d_new
然后我们返回当前迭代值作为近似解。
@jit
def solve_model(mcm, tol=1e-5, max_iter=2000):
"""
对贝尔曼方程进行迭代直至收敛
* mcm 是 McCallModel 的一个实例
"""
v = np.ones_like(mcm.w_grid) # v的初始猜测值
d = 1 # d的初始猜测值
i = 0
error = tol + 1
while error > tol and i < max_iter:
v_new, d_new = mcm.update(v, d)
error_1 = np.max(np.abs(v_new - v))
error_2 = np.abs(d_new - d)
error = max(error_1, error_2)
v = v_new
d = d_new
i += 1
return v, d
以下是一个函数compute_reservation_wage,它接收一个McCallModelContinuous实例并返回相应的保留工资。
如果对所有的\(w\)都有\(v(w) < h\),那么函数返回np.inf。
@jit
def compute_reservation_wage(mcm):
"""
通过寻找最小的满足v(w) >= h的w,
计算McCall模型实例的保留工资。
如果不存在这样的w,那么w_bar就被设为np.inf。
"""
u = lambda x: np.log(x)
v, d = solve_model(mcm)
h = u(mcm.c) + mcm.β * d
w_bar = np.inf
for i, wage in enumerate(mcm.w_grid):
if v[i] > h:
w_bar = wage
break
return w_bar
下面的练习中我们探究保留工资随参数变化的情况。
44.4. 练习#
练习 44.1
使用上面的代码来探究当工资参数 \(\mu\) 发生变化时,保留工资会发生什么变化。
使用默认参数以及 mu_vals = np.linspace(0.0, 2.0, 15) 中 \(\mu\) 的值。
保留工资的变化是否符合你的预期?
解答 练习 44.1
这是一种答案
mcm = McCallModelContinuous()
mu_vals = np.linspace(0.0, 2.0, 15)
w_bar_vals = np.empty_like(mu_vals)
fig, ax = plt.subplots()
for i, m in enumerate(mu_vals):
mcm.w_draws = lognormal_draws(μ=m)
w_bar = compute_reservation_wage(mcm)
w_bar_vals[i] = w_bar
ax.set(xlabel='均值', ylabel='保留工资')
ax.plot(mu_vals, w_bar_vals, label=r'$\bar w$ 随 $\mu$ 的变化')
ax.legend()
plt.show()

不出所料,当工资报价分布向右偏移时,求职者更倾向于等待。
练习 44.2
现在我们来考虑求职者在面对波动性增加时,会做出怎样的反应。
为了理解这一点,请计算当工资报价在 \((m - s, m + s)\) 上均匀分布且 \(s\) 会变化时的保留工资。
这里的想法是我们保持均值不变,但扩大支撑集。
(这是一种均值保留展开。)
使用 s_vals = np.linspace(1.0, 2.0, 15) 和 m = 2.0。
在分析保留工资如何随 \(s\) 变化之前,让我们先思考一下:
当工资分布的波动性增加时,求职者面临两个相反的影响:
更高的不确定性可能会让求职者倾向于接受当前工作机会,因为这提供了确定性收入
但另一方面,更大的波动性也意味着出现高工资的机会增加了
你认为哪个影响会占主导地位?保留工资会随着 \(s\) 的增加而上升还是下降?
现在,请计算它。结果是否符合你的预期?
解答 练习 44.2
这是其中一种解法
mcm = McCallModelContinuous()
s_vals = np.linspace(1.0, 2.0, 15)
m = 2.0
w_bar_vals = np.empty_like(s_vals)
fig, ax = plt.subplots()
for i, s in enumerate(s_vals):
a, b = m - s, m + s
mcm.w_draws = np.random.uniform(low=a, high=b, size=10_000)
w_bar = compute_reservation_wage(mcm)
w_bar_vals[i] = w_bar
ax.set(xlabel='波动性', ylabel='保留工资')
ax.plot(s_vals, w_bar_vals, label=r'将工资波动性作为自变量的$\bar w$')
ax.legend()
plt.show()
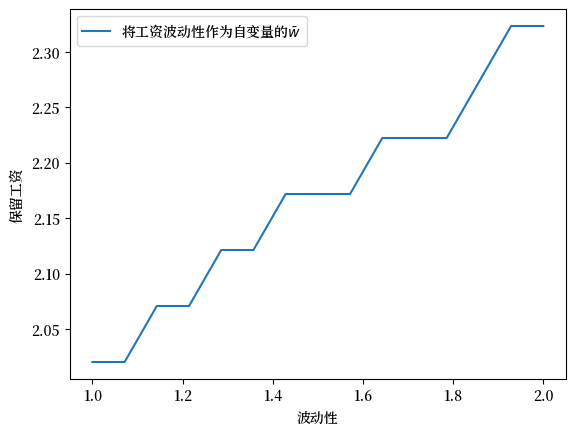
保留工资随波动性增加而增加。
人们可能会认为,更高的波动性会使求职者更倾向于接受给定的工作机会,因为接受工作代表确定性,而等待则意味着风险。
但求职就像持有期权:工人只面临上行风险(因为在自由市场中,没有人可以强迫他们接受不好的工作机会)。
更大的波动性意味着更高的上行潜力,这会鼓励求职者继续等待。