42. 工作搜寻 I: McCall搜寻模型#
“询问一个McCall劳动者就像与一个失业的朋友对话:‘也许你的期望值定得太高了’,或者’为什么你在找到新工作之前就辞掉了原来的工作?’这就是真正的社会科学:试图通过观察人们所处的情况、他们面临的选择、以及他们自己所认为的优缺点来建模,以理解人类行为。” – 小罗伯特·卢卡斯
除了Anaconda中已有的内容外,本讲座还需要以下库:
!pip install quantecon
42.1. 概述#
McCall 搜索模型 [McCall, 1970] 帮助改变了经济学家思考劳动力市场的方式。
为了阐明”非自愿”失业等概念,McCall 从以下因素建模了失业劳动者的决策问题:
当前工资和可能的未来工资
耐心程度
失业补助
为了解决这个决策问题,McCall 使用了动态规划。
在本讲中,我们将建立 McCall 的模型并使用动态规划来分析它。
我们将看到,McCall 的模型不仅本身很有趣,而且是学习动态规划的绝佳载体。
让我们从一些导入开始:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5) #设置默认图片尺寸
import numpy as np
from numba import jit, float64
from numba.experimental import jitclass
import quantecon as qe
from quantecon.distributions import BetaBinomial
42.2. McCall模型#
一个失业者在每个时期都会收到一个工资为\(w_t\)的工作机会。
在本讲中,我们采用以下简单环境:
工资序列\(\{w_t\}_{t \geq 0}\)是独立同分布的,其中\(q(w)\)是在有限集合\(\mathbb{W}\)中观察到工资\(w\)的概率。
失业者在\(t\)期的开始观察到\(w_t\)。
失业者知道\(\{w_t\}\)是具有共同分布\(q\)的独立同分布序列,并可以利用这一点计算期望值。
(在后续讲座中,我们将放宽这些假设。)
在时间\(t\),失业者有两个选择:
接受工作机会,并以固定工资\(w_t\)永久工作。
拒绝工作机会,获得失业补助\(c\),并在下一期重新考虑。
假设失业者具有无限长的生命,其目标是最大化折现收益总和的期望值
常数\(\beta\)位于\((0, 1)\)之间,被称为折现因子。
\(\beta\) 越小,未来效用的折现值越高。
变量 \(y_t\) 是收入,
当就业时,它等于工资 \(w_t\)
当失业时,它等于失业补助金 \(c\)
42.2.1. 权衡取舍#
劳动者面临一个权衡:
等待太久以获得好的工作机会是有代价的,因为未来会被折现。
过早接受工作机会也是有代价的,因为将来可能会出现更好的机会。
为了在这种权衡中做出最优决策,我们使用动态规划。
动态规划可以被视为一个两步骤的过程:
首先为”状态”赋值
然后根据这些值推导出最优行动
我们将依次讨论这些步骤。
42.2.2. 价值函数#
为了在当前和未来回报之间进行最优权衡,我们需要考虑两个方面:
不同选择带来的当前收益
这些选择在下一期会导致的不同状态
为了权衡决策问题的这两个方面,我们需要给状态赋予价值。
为此,让\(v^*(w)\)表示当工资为\(w \in \mathbb{W}\)时,一个失业劳动者在当前时期开始时的总生命周期价值。
具体来说,我们考虑这样一种情况:一个失业者现在面临一个工资为 \(w\) 的工作机会。
那么,\(v^*(w)\)表示的是该失业者在当前和未来所有时间点做出最优决策时,目标函数(43.1)的价值。
当然,计算\(v^*(w)\)并不简单,因为我们还不知道哪些决策是最优的,哪些不是!
但是可以将\(v^*\)看作一个函数,它为每个可能的工资\(w\)分配在持有该工作机会时可获得的最大终身价值。
一个关键点是,这个函数\(v^*\)必须满足以下递归关系: 对于 \(\mathbb{W}\) 中的每一个可能的 \(w\),我们有
这个重要的方程是贝尔曼方程的一个版本,这个方程在经济动态学和其他涉及长期规划的领域中无处不在。
其背后的直观理解如下:
max运算中的第一项是接受当前工作机会的终身收益,因为
max运算中的第二项是延续值,即拒绝当前工作机会并在随后所有时期做出最优行为的终身收益。
通过从这两个选项中选择最优的一个,我们就能得到在当前工资报价 \(w\) 下的最大终身价值。
而这恰恰就是 (42.1) 左边的 \(v^*(w)\)。
42.2.3. 最优策略#
假设现在我们能够求解 (42.1) 得到未知函数 \(v^*\)。
一旦我们掌握了这个函数,我们就可以做出最优行为(即在接受和拒绝之间做出正确选择)。
我们只需要在(42.1)的右侧选择最大值即可。
最优行动最好被理解为一个策略,它通常是一个从状态到行动的映射。
对于任何\(w\),我们都可以通过在(42.1)右侧选择最大值来得到相应的最佳选择(接受或拒绝)。
因此,我们有一个从\(\mathbb R\)到\(\{0, 1\}\)的映射,其中1表示接受,0表示拒绝。
我们可以将策略写作如下
这里\(\mathbf{1}\{ P \}\)在语句\(P\)为真时等于1,否则等于0。
我们也可以将其写作
其中
这里的 \(\bar w\)(称为保留工资)是一个取决于 \(\beta, c\) 和工资分布的常数。
失业者当且仅当当前工作机会的工资超过保留工资时接受该工作。
根据(42.2),如果我们能计算出价值函数,就能计算出这个保留工资。
42.3. 计算最优策略:第一种方法#
为了将上述想法付诸实践,我们需要计算每个可能状态 \(w \in \mathbb W\) 下的价值函数。
为了简化符号,让我们设定
价值函数则由向量 \(v^* = (v^*(i))_{i=1}^n\) 表示。
根据(42.1),这个向量满足如下非线性方程组
42.3.1. 算法#
为了计算这个向量,我们使用连续逼近法:
第1步:选择一个任意的初始猜测值 \(v \in \mathbb R^n\)。
第2步:通过以下方式计算新向量 \(v' \in \mathbb R^n\)
第3步:计算 \(v\) 和 \(v'\) 之间的差异度量,例如 \(\max_i |v(i)- v'(i)|\)。
第4步:如果偏差大于某个固定的容差,则令 \(v = v'\) 并返回第2步,否则继续。
第5步:返回 \(v\)。
对于较小的容差,返回的函数 \(v\) 是价值函数 \(v^*\) 的近似值。
下面的理论将详细说明这一点。
42.3.2. 不动点理论#
这个算法背后的数学原理是什么?
首先,通过以下方式定义从 \(\mathbb R^n\) 到自身的映射 \(T\):
(通过在每个 \(i\) 处计算右侧的值,从给定向量 \(v\) 得到新向量 \(Tv\)。)
连续近似序列 \(\{v_k\}\) 中的元素 \(v_k\) 对应于 \(T^k v\)。
这是从初始猜测 \(v\) 开始,应用 \(k\) 次 \(T\) 的结果
可以证明,\(T\) 在 \(\mathbb R^n\) 上满足巴拿赫不动点定理的条件。
一个推论是 \(T\) 在 \(\mathbb R^n\) 中有唯一的不动点。
即存在唯一的向量 \(\bar v\) 使得 \(T \bar v = \bar v\)。
而且,从 \(T\) 的定义可以直接得出这个不动点就是 \(v^*\)。
巴拿赫收缩映射定理的第二个推论是,无论 \(v\) 取何值,序列 \(\{ T^k v \}\) 都会收敛到不动点 \(v^*\)。
42.3.3. 实现#
对于状态过程的分布 \(q\),我们的默认选择是Beta-二项分布。
n, a, b = 50, 200, 100 # 默认参数
q_default = BetaBinomial(n, a, b).pdf() # q的默认选择
我们的工资默认值设置为
w_min, w_max = 10, 60
w_default = np.linspace(w_min, w_max, n+1)
这是不同工资结果的概率分布图:
fig, ax = plt.subplots()
ax.plot(w_default, q_default, '-o', label='$q(w(i))$')
ax.set_xlabel('工资')
ax.set_ylabel('概率')
plt.show()

我们将使用Numba来加速我们的代码。
参见我们关于Numba的讲座中对
@jitclass的讨论。
以下内容通过提供一些类型来帮助Numba
mccall_data = [
('c', float64), # 失业补偿
('β', float64), # 贴现因子
('w', float64[:]), # 工资值数组,w[i] = 状态i下的工资
('q', float64[:]) # 概率数组
]
这是一个用于存储数据并计算状态-行动对的值的类,即基于当前状态和任意可行的行动,计算贝尔曼方程 (42.4) 右侧最大值括号中的值。
类中包含了默认参数值。
@jitclass(mccall_data)
class McCallModel:
def __init__(self, c=25, β=0.99, w=w_default, q=q_default):
self.c, self.β = c, β
self.w, self.q = w_default, q_default
def state_action_values(self, i, v):
"""
状态-动作对的值。
"""
# 简化名称
c, β, w, q = self.c, self.β, self.w, self.q
# 评估每个状态-行动对的值
# 考虑行动 = 接受或拒绝当前报价
accept = w[i] / (1 - β)
reject = c + β * np.sum(v * q)
return np.array([accept, reject])
根据这些默认值,让我们尝试绘制序列 \(\{ T^k v \}\) 中最初几个近似值函数。
我们将从猜测值 \(v\) 开始,其中 \(v(i) = w(i) / (1 - β)\),这是在每个给定工资下都接受的价值。
这里有一个实现该功能的函数:
def plot_value_function_seq(mcm, ax, num_plots=6):
"""
绘制一系列值函数。
* mcm 是 McCallModel 的一个实例
* ax 是实现了 plot 方法的轴对象
"""
n = len(mcm.w)
v = mcm.w / (1 - mcm.β)
v_next = np.empty_like(v)
for i in range(num_plots):
ax.plot(mcm.w, v, '-', alpha=0.4, label=f"iterate {i}")
# 更新猜测值
for j in range(n):
v_next[j] = np.max(mcm.state_action_values(j, v))
v[:] = v_next # 将内容复制到 v 中
ax.legend(loc='lower right')
现在让我们创建一个 McCallModel 实例,并观察迭代 \(T^k v\) 从下方收敛的过程:
mcm = McCallModel()
fig, ax = plt.subplots()
ax.set_xlabel('工资')
ax.set_ylabel('价值')
plot_value_function_seq(mcm, ax)
plt.show()
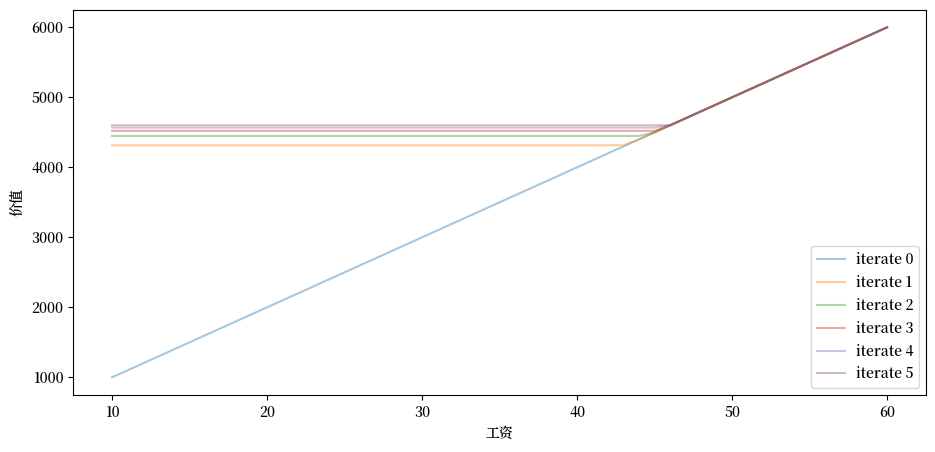
你可以看到收敛的发生:连续的迭代值越来越接近。
这里有一个更严谨的迭代计算极限的方法,它会持续计算直到连续迭代之间的测量偏差小于容差值。
一旦我们获得了对极限的良好近似,我们将用它来计算保留工资。
我们将通过Numba的JIT编译来加速我们的循环。
@jit
def compute_reservation_wage(mcm,
max_iter=500,
tol=1e-6):
# 简化名称
c, β, w, q = mcm.c, mcm.β, mcm.w, mcm.q
# == 首先计算价值函数 == #
n = len(w)
v = w / (1 - β) # 初始猜测
v_next = np.empty_like(v)
j = 0
error = tol + 1
while j < max_iter and error > tol:
for j in range(n):
v_next[j] = np.max(mcm.state_action_values(j, v))
error = np.max(np.abs(v_next - v))
j += 1
v[:] = v_next # 将内容复制到v中
# == 现在计算保留工资 == #
return (1 - β) * (c + β * np.sum(v * q))
现在我们计算在默认参数下的保留工资
compute_reservation_wage(mcm)
47.316499710024964
42.3.4. 比较静态分析#
现在我们知道如何计算保留工资,让我们来看看它如何随参数变化。
具体来说,让我们看看当我们改变\(\beta\)和\(c\)时会发生什么。
grid_size = 25
R = np.empty((grid_size, grid_size))
c_vals = np.linspace(10.0, 30.0, grid_size)
β_vals = np.linspace(0.9, 0.99, grid_size)
for i, c in enumerate(c_vals):
for j, β in enumerate(β_vals):
mcm = McCallModel(c=c, β=β)
R[i, j] = compute_reservation_wage(mcm)
fig, ax = plt.subplots()
cs1 = ax.contourf(c_vals, β_vals, R.T, alpha=0.75)
ctr1 = ax.contour(c_vals, β_vals, R.T)
plt.clabel(ctr1, inline=1, fontsize=13)
plt.colorbar(cs1, ax=ax)
ax.set_title("保留工资")
ax.set_xlabel("$c$", fontsize=16)
ax.set_ylabel("$β$", fontsize=16)
ax.ticklabel_format(useOffset=False)
plt.show()

如预期所示,保留工资随着耐心程度和失业补助的增加而增加。
42.4. 计算最优策略:方法二#
刚才描述的动态规划方法是标准且广泛适用的。
但对于我们的McCall搜索模型来说,还有一个更简单的方法,可以避免计算价值函数。
让 \(h\) 表示延续值:
贝尔曼方程现在可以写作
将这个等式代入 (42.6) 得到
这是一个我们可以求解 \(h\) 的非线性方程。
和之前一样,我们将使用连续近似法:
第1步:选择一个初始猜测值 \(h\)。
第2步:通过以下公式计算更新值 \(h'\)
第3步:计算偏差 \(|h - h'|\)。
第4步:如果偏差大于某个固定的容差,则设置 \(h = h'\) 并返回第2步,否则返回 \(h\)。
我们可以再次使用巴拿赫不动点定理来证明这个过程总是收敛的。
与之前的方法相比,这里有一个重要区别:我们现在是对单个标量 \(h\) 进行迭代,而不是像之前那样对 \(n\) 维向量 \(v(i), i = 1, \ldots, n\) 进行迭代,这使得计算过程更加简单。
以下是实现代码:
@jit
def compute_reservation_wage_two(mcm,
max_iter=500,
tol=1e-5):
# 简化名称
c, β, w, q = mcm.c, mcm.β, mcm.w, mcm.q
# == 首先计算h == #
h = np.sum(w * q) / (1 - β)
i = 0
error = tol + 1
while i < max_iter and error > tol:
s = np.maximum(w / (1 - β), h)
h_next = c + β * np.sum(s * q)
error = np.abs(h_next - h)
i += 1
h = h_next
# == 现在计算保留工资 == #
return (1 - β) * h
你可以使用以上代码来完成下面的练习。
42.5. 练习#
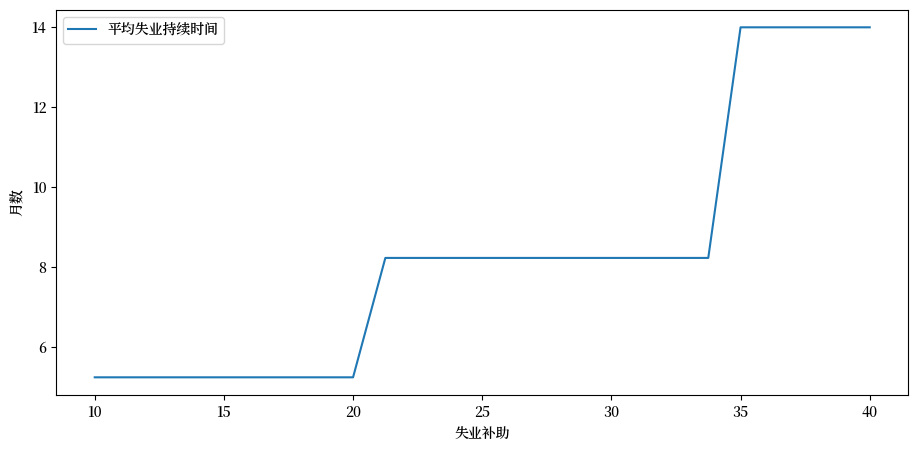
练习 42.1
当 \(\beta=0.99\) 且 \(c\) 取以下值时,计算失业的平均持续时间
c_vals = np.linspace(10, 40, 25)
也就是说,让失业者从失业状态开始,根据给定参数计算其保留工资,然后模拟看需要多长时间才能接受工作。
重复多次并取平均值。
绘制平均失业持续时间与 c_vals 中的 \(c\) 值的函数关系图。
解答 练习 42.1
参考答案
cdf = np.cumsum(q_default)
@jit
def compute_stopping_time(w_bar, seed=1234):
np.random.seed(seed)
t = 1
while True:
# 生成工资抽样
w = w_default[qe.random.draw(cdf)]
# 当抽样值高于保留工资时停止
if w >= w_bar:
stopping_time = t
break
else:
t += 1
return stopping_time
@jit
def compute_mean_stopping_time(w_bar, num_reps=100000):
obs = np.empty(num_reps)
for i in range(num_reps):
obs[i] = compute_stopping_time(w_bar, seed=i)
return obs.mean()
c_vals = np.linspace(10, 40, 25)
stop_times = np.empty_like(c_vals)
for i, c in enumerate(c_vals):
mcm = McCallModel(c=c)
w_bar = compute_reservation_wage_two(mcm)
stop_times[i] = compute_mean_stopping_time(w_bar)
fig, ax = plt.subplots()
ax.plot(c_vals, stop_times, label="平均失业持续时间")
ax.set(xlabel="失业补助", ylabel="月数")
ax.legend()
plt.show()
练习 42.2
本练习的目的是展示如何将上文使用的离散工资分布替换为连续分布。
这是一个重要内容,因为许多常用的分布都是连续的(即具有密度函数)。
幸运的是,在我们的简单模型中理论变化很小。
回想一下,(42.6)中的\(h\)表示在本期不接受工作但在随后所有期间表现最优的价值:
要转换为连续分布,我们可以用以下式子替换(42.6):
方程(42.7)变为:
目标是通过迭代求解这个非线性方程,并从中得到保留工资。
尝试实现这一点,设置
状态序列 \(\{ s_t \}\) 为独立同分布的标准正态分布,且
工资函数为 \(w(s) = \exp(\mu + \sigma s)\)。
你需要实现一个新版本的 McCallModel 类,该类假设工资为对数正态分布。
通过蒙特卡洛方法计算积分,即对大量工资抽样进行平均。
对于默认参数,使用 c=25, β=0.99, σ=0.5, μ=2.5。
当你的代码可以运行后,研究保留工资如何随 \(c\) 和 \(\beta\) 变化。
解答 练习 42.2
参考答案:
mccall_data_continuous = [
('c', float64), # 失业补助
('β', float64), # 贴现因子
('σ', float64), # 对数正态分布的尺度参数
('μ', float64), # 对数正态分布的位置参数
('w_draws', float64[:]) # 蒙特卡洛的工资抽样
]
@jitclass(mccall_data_continuous)
class McCallModelContinuous:
def __init__(self, c=25, β=0.99, σ=0.5, μ=2.5, mc_size=1000):
self.c, self.β, self.σ, self.μ = c, β, σ, μ
# 抽样并存储随机冲击
np.random.seed(1234)
s = np.random.randn(mc_size)
self.w_draws = np.exp(μ+ σ * s)
@jit
def compute_reservation_wage_continuous(mcmc, max_iter=500, tol=1e-5):
c, β, σ, μ, w_draws = mcmc.c, mcmc.β, mcmc.σ, mcmc.μ, mcmc.w_draws
h = np.mean(w_draws) / (1 - β) # 初始值猜测
i = 0
error = tol + 1
while i < max_iter and error > tol:
integral = np.mean(np.maximum(w_draws / (1 - β), h))
h_next = c + β * integral
error = np.abs(h_next - h)
i += 1
h = h_next
# == 现在计算保留工资 == #
return (1 - β) * h
现在我们研究保留工资如何随着 \(c\) 和 \(\beta\) 变化。
我们将使用等值线图来分析这个问题。
grid_size = 25
R = np.empty((grid_size, grid_size))
c_vals = np.linspace(10.0, 30.0, grid_size)
β_vals = np.linspace(0.9, 0.99, grid_size)
for i, c in enumerate(c_vals):
for j, β in enumerate(β_vals):
mcmc = McCallModelContinuous(c=c, β=β)
R[i, j] = compute_reservation_wage_continuous(mcmc)
fig, ax = plt.subplots()
cs1 = ax.contourf(c_vals, β_vals, R.T, alpha=0.75)
ctr1 = ax.contour(c_vals, β_vals, R.T)
plt.clabel(ctr1, inline=1, fontsize=13)
plt.colorbar(cs1, ax=ax)
ax.set_title("保留工资")
ax.set_xlabel("$c$", fontsize=16)
ax.set_ylabel("$β$", fontsize=16)
ax.ticklabel_format(useOffset=False)
plt.show()
