80. Python线性回归#
除了Anaconda中已有的库外,本讲座还需要以下库:
!pip install linearmodels
80.1. 概述#
线性回归是分析两个或多个变量之间关系的基础工具。
在本讲中,我们将使用Python的statsmodels包来探索线性回归分析。我们将学习如何:
建立和估计简单及多元线性回归模型
通过图表直观展示分析结果
理解内生性问题和遗漏变量偏差
使用两阶段最小二乘法处理内生性
通过这些内容,你将掌握使用Python进行线性回归分析的基本技能。
作为示例,我们将复现Acemoglu、Johnson和Robinson具有开创性意义的论文[Acemoglu et al., 2001]中的结果。
您可以在这里下载论文。
在这篇论文中,作者强调了制度在经济发展中的重要性。
该论文的一个重要创新是利用了早期殖民者的死亡率数据,作为各地区制度差异的外生来源。
这种方法对于确定因果关系至关重要 - 即制度质量的提高会带来经济增长,而不是经济发展反过来改善了制度。
让我们从一些导入开始:
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
plt.rcParams["figure.figsize"] = (11, 5) #设置默认图形大小
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.iolib.summary2 import summary_col
from linearmodels.iv import IV2SLS
import seaborn as sns
sns.set_theme()
80.1.1. 预备知识#
本讲座需要基础计量经济学知识。
如果你需要复习相关概念,可以参考[Wooldridge, 2015]等教材。
80.2. 简单线性回归#
让我们从一个有趣的经济学问题开始 - 制度差异是否会影响一个国家的经济发展水平?这正是[Acemoglu et al., 2001]试图回答的问题。
我们如何衡量制度差异和经济结果?
在这篇论文中,
经济结果用1995年经汇率调整的人均GDP对数表示。
制度差异用政治风险研究组织构建的1985-95年间平均防止征用风险指数表示。
这些数据以及论文中使用的其他变量都可以从Daron Acemoglu的个人主页下载。
接下来,我们用pandas的.read_stata()函数来读取这些存储在.dta格式文件中的数据
df1 = pd.read_stata('https://github.com/QuantEcon/lecture-python/blob/master/source/_static/lecture_specific/ols/maketable1.dta?raw=true')
df1.head()
| shortnam | euro1900 | excolony | avexpr | logpgp95 | cons1 | cons90 | democ00a | cons00a | extmort4 | logem4 | loghjypl | baseco | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AFG | 0.000000 | 1.0 | NaN | NaN | 1.0 | 2.0 | 1.0 | 1.0 | 93.699997 | 4.540098 | NaN | NaN |
| 1 | AGO | 8.000000 | 1.0 | 5.363636 | 7.770645 | 3.0 | 3.0 | 0.0 | 1.0 | 280.000000 | 5.634789 | -3.411248 | 1.0 |
| 2 | ARE | 0.000000 | 1.0 | 7.181818 | 9.804219 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | ARG | 60.000004 | 1.0 | 6.386364 | 9.133459 | 1.0 | 6.0 | 3.0 | 3.0 | 68.900002 | 4.232656 | -0.872274 | 1.0 |
| 4 | ARM | 0.000000 | 0.0 | NaN | 7.682482 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
让我们使用散点图来观察人均GDP和防止征用指数之间是否存在明显的关系
df1.plot(x='avexpr', y='logpgp95', kind='scatter')
plt.show()
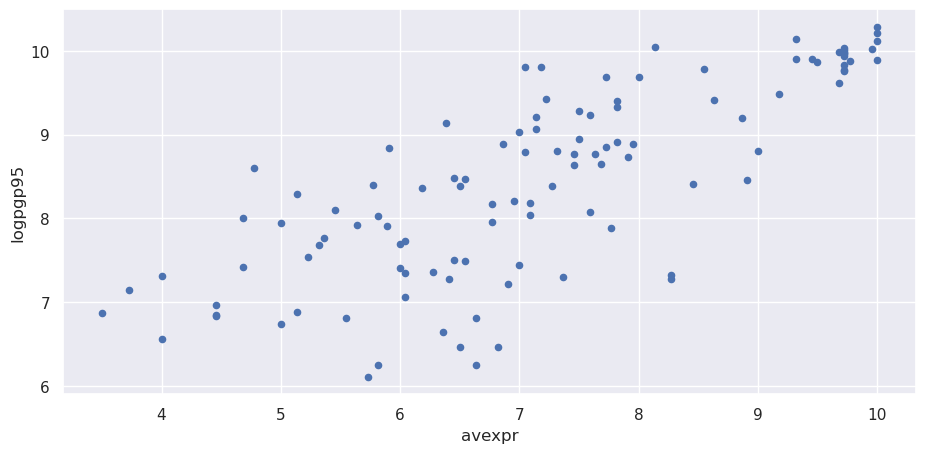
从散点图中可以清楚地看到,一个国家的防止征用保护水平与其人均GDP之间存在明显的正相关关系。
换句话说,如果我们把防止征用保护视为衡量制度质量的指标,那么数据表明制度质量越好的国家,经济表现(以人均GDP衡量)也往往越好。
从散点图的形状来看,用一条直线来拟合这种关系是比较合适的。因此我们可以用一个简单的线性模型来描述它们之间的关系。
我们可以将这个模型写作
其中:
\(\beta_0\) 是线性趋势线在y轴上的截距
\(\beta_1\) 是线性趋势线的斜率,表示防止风险保护对人均GDP对数的边际效应
\(u_i\) 是随机误差项(由于模型未包含的因素导致观测值偏离线性趋势)
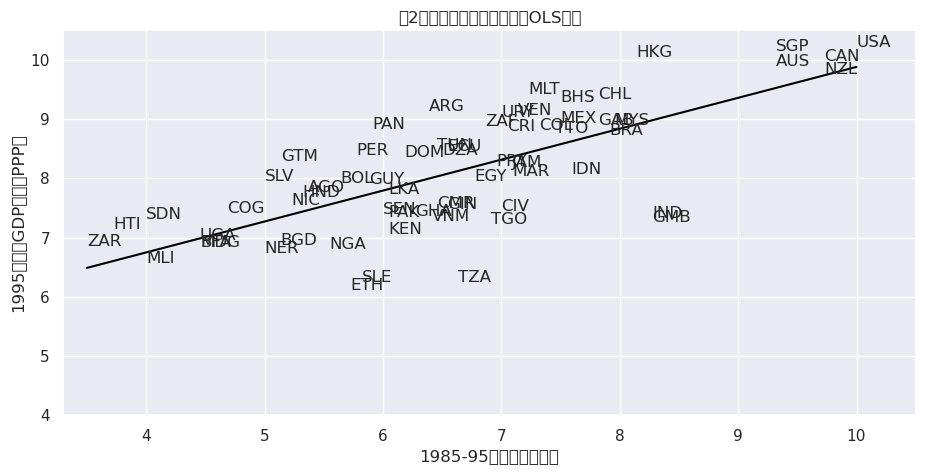
直观来看,这个线性模型涉及选择一条最佳的直线来拟合数据,如下图所示(图2,引用自[Acemoglu et al., 2001])
# 使用numpy的polyfit需要我们删除缺失值
df1_subset = df1.dropna(subset=['logpgp95', 'avexpr'])
# 仅使用'baseco'为1的样本用于绘图目的
df1_subset = df1_subset[df1_subset['baseco'] == 1]
X = df1_subset['avexpr']
y = df1_subset['logpgp95']
labels = df1_subset['shortnam']
# 用国家标签替换标记点
fig, ax = plt.subplots()
ax.scatter(X, y, marker='')
for i, label in enumerate(labels):
ax.annotate(label, (X.iloc[i], y.iloc[i]))
# 拟合线性趋势线
ax.plot(np.unique(X),
np.poly1d(np.polyfit(X, y, 1))(np.unique(X)),
color='black')
ax.set_xlim([3.3,10.5])
ax.set_ylim([4,10.5])
ax.set_xlabel('1985-95年平均征收风险')
ax.set_ylabel('1995年人均GDP对数(PPP)')
ax.set_title('图2:征收风险与收入之间的OLS关系')
plt.show()
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 24180 (\N{CJK UNIFIED IDEOGRAPH-5E74}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20154 (\N{CJK UNIFIED IDEOGRAPH-4EBA}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 22343 (\N{CJK UNIFIED IDEOGRAPH-5747}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 23545 (\N{CJK UNIFIED IDEOGRAPH-5BF9}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 25968 (\N{CJK UNIFIED IDEOGRAPH-6570}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 65288 (\N{FULLWIDTH LEFT PARENTHESIS}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 65289 (\N{FULLWIDTH RIGHT PARENTHESIS}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 22270 (\N{CJK UNIFIED IDEOGRAPH-56FE}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 65306 (\N{FULLWIDTH COLON}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 24449 (\N{CJK UNIFIED IDEOGRAPH-5F81}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 25910 (\N{CJK UNIFIED IDEOGRAPH-6536}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 39118 (\N{CJK UNIFIED IDEOGRAPH-98CE}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 38505 (\N{CJK UNIFIED IDEOGRAPH-9669}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 19982 (\N{CJK UNIFIED IDEOGRAPH-4E0E}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20837 (\N{CJK UNIFIED IDEOGRAPH-5165}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20043 (\N{CJK UNIFIED IDEOGRAPH-4E4B}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 38388 (\N{CJK UNIFIED IDEOGRAPH-95F4}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 30340 (\N{CJK UNIFIED IDEOGRAPH-7684}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20851 (\N{CJK UNIFIED IDEOGRAPH-5173}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 31995 (\N{CJK UNIFIED IDEOGRAPH-7CFB}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 24179 (\N{CJK UNIFIED IDEOGRAPH-5E73}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
估计线性模型参数(\(\beta\)值)最常用的技术是普通最小二乘法(OLS)。
顾名思义,OLS模型是通过寻找能使残差平方和最小化的参数来求解的,即:
其中\(\hat{u}_i\)是观测值与因变量预测值之间的差异。
为了估计截距项\(\beta_0\),我们需要在数据集中添加一列值为1的常数列。
这样做的原因是,如果我们将\(\beta_0\)写成\(\beta_0 x_i\)的形式,其中\(x_i = 1\),那么这一项就代表了回归线在y轴上的截距。
df1['const'] = 1
现在我们可以使用OLS函数在statsmodels中构建我们的模型。
我们将在statsmodels中使用pandas数据类型,不过标准数组也可以作为参数使用
reg1 = sm.OLS(endog=df1['logpgp95'], exog=df1[['const', 'avexpr']], \
missing='drop')
type(reg1)
statsmodels.regression.linear_model.OLS
到目前为止,我们只是构建了模型。
我们需要使用.fit()来获得参数估计值
\(\hat{\beta}_0\) 和 \(\hat{\beta}_1\)
results = reg1.fit()
type(results)
statsmodels.regression.linear_model.RegressionResultsWrapper
我们现在已将拟合的回归模型存储在results中。
要查看OLS回归结果,我们可以调用.summary()方法。
请注意,在原始论文中一个观测值被错误地删除了(参见Acemoglu网页中maketable2.do文件中的注释),因此系数略有不同。
print(results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: logpgp95 R-squared: 0.611
Model: OLS Adj. R-squared: 0.608
Method: Least Squares F-statistic: 171.4
Date: Mon, 03 Nov 2025 Prob (F-statistic): 4.16e-24
Time: 03:45:04 Log-Likelihood: -119.71
No. Observations: 111 AIC: 243.4
Df Residuals: 109 BIC: 248.8
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 4.6261 0.301 15.391 0.000 4.030 5.222
avexpr 0.5319 0.041 13.093 0.000 0.451 0.612
==============================================================================
Omnibus: 9.251 Durbin-Watson: 1.689
Prob(Omnibus): 0.010 Jarque-Bera (JB): 9.170
Skew: -0.680 Prob(JB): 0.0102
Kurtosis: 3.362 Cond. No. 33.2
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
从我们的结果中,我们看到
截距 \(\hat{\beta}_0 = 4.63\)。
斜率 \(\hat{\beta}_1 = 0.53\)。
正的 \(\hat{\beta}_1\) 参数估计值表明,制度质量对经济结果有正面影响,正如我们在图中所看到的。
\(\hat{\beta}_1\) 的p值为0.000,表明制度对GDP的影响在统计上显著(使用p < 0.05作为判断是否显著的标准)。
R方值为0.611,这意味着防止征收保护这一变量可以解释约61%的人均GDP对数的变化。
使用我们的参数估计,我们现在可以将估计关系写为
这个方程描述了最符合我们数据的直线,如图2所示。
我们可以使用这个方程来预测特定征收保护指数值对应的人均GDP对数水平。
例如,对于一个指数值为7.07的国家(这是数据集中最高的指数值),我们发现他们预测的1995年人均GDP对数值为8.38。
mean_expr = np.mean(df1_subset['avexpr'])
mean_expr
np.float32(6.515625)
predicted_logpdp95 = 4.63 + 0.53 * 7.07
predicted_logpdp95
8.3771
获得这个结果有一个更简单(也更准确)的方法,就是使用.predict() 并设置 \(constant = 1\) 和 \({avexpr}_i = mean\_expr\)
results.predict(exog=[1, mean_expr])
array([8.09156367])
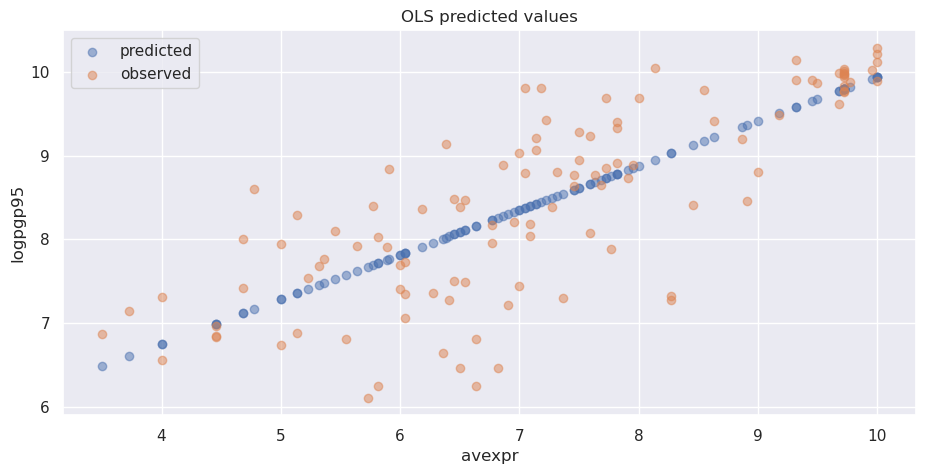
我们可以通过在结果上调用.predict()来获取数据集中每个\({avexpr}_i\)值对应的预测\({logpgp95}_i\)数组。
将预测值与\({avexpr}_i\)绘制在图上显示,预测值都落在我们之前拟合的直线上。
同时也绘制了\({logpgp95}_i\)的观测值以作比较。
# 从整个样本中删除缺失观测值
df1_plot = df1.dropna(subset=['logpgp95', 'avexpr'])
# 绘制预测值
fix, ax = plt.subplots()
ax.scatter(df1_plot['avexpr'], results.predict(), alpha=0.5,
label='predicted')
# 绘制观测值
ax.scatter(df1_plot['avexpr'], df1_plot['logpgp95'], alpha=0.5,
label='observed')
ax.legend()
ax.set_title('OLS predicted values')
ax.set_xlabel('avexpr')
ax.set_ylabel('logpgp95')
plt.show()
80.3. 扩展线性回归模型#
到目前为止,我们只关注了制度对经济表现的影响。但显然,一个国家的GDP还受到许多其他因素的影响。我们的模型目前还没有考虑这些因素。
如果我们忽略了这些影响\(logpgp95_i\)的重要变量,就会产生所谓的遗漏变量偏差。这种偏差会导致我们的参数估计既有偏又不一致。
为了解决这个问题,我们可以将原来的双变量回归扩展为多变量回归模型,把其他可能影响\(logpgp95_i\)的因素也纳入考虑。
在[Acemoglu et al., 2001]中,作者考虑了多个可能影响经济发展的因素:
气候条件:他们使用纬度作为衡量气候的代理变量,因为纬度与温度、降水等气候特征密切相关
地区特征:通过引入大陆虚拟变量(如亚洲、非洲等),来控制不同地区在文化、历史等方面的差异
让我们来看看这些扩展模型的估计结果。
我们将使用maketable2.dta中的数据,复现论文表2中的分析
df2 = pd.read_stata('https://github.com/QuantEcon/lecture-python/blob/master/source/_static/lecture_specific/ols/maketable2.dta?raw=true')
# 向数据集添加常数项
df2['const'] = 1
# 创建每个回归要使用的变量列表
X1 = ['const', 'avexpr']
X2 = ['const', 'avexpr', 'lat_abst']
X3 = ['const', 'avexpr', 'lat_abst', 'asia', 'africa', 'other']
# 对每组变量估计OLS回归
reg1 = sm.OLS(df2['logpgp95'], df2[X1], missing='drop').fit()
reg2 = sm.OLS(df2['logpgp95'], df2[X2], missing='drop').fit()
reg3 = sm.OLS(df2['logpgp95'], df2[X3], missing='drop').fit()
现在我们已经拟合了模型,我们将使用summary_col在一个表格中显示结果(模型编号与论文中的相对应)
info_dict={'R-squared' : lambda x: f"{x.rsquared:.2f}",
'No. observations' : lambda x: f"{int(x.nobs):d}"}
results_table = summary_col(results=[reg1,reg2,reg3],
float_format='%0.2f',
stars = True,
model_names=['Model 1',
'Model 3',
'Model 4'],
info_dict=info_dict,
regressor_order=['const',
'avexpr',
'lat_abst',
'asia',
'africa'])
results_table.add_title('表2 - OLS回归')
print(results_table)
表2 - OLS回归
=========================================
Model 1 Model 3 Model 4
-----------------------------------------
const 4.63*** 4.87*** 5.85***
(0.30) (0.33) (0.34)
avexpr 0.53*** 0.46*** 0.39***
(0.04) (0.06) (0.05)
lat_abst 0.87* 0.33
(0.49) (0.45)
asia -0.15
(0.15)
africa -0.92***
(0.17)
other 0.30
(0.37)
R-squared 0.61 0.62 0.72
R-squared Adj. 0.61 0.62 0.70
No. observations 111 111 111
R-squared 0.61 0.62 0.72
=========================================
Standard errors in parentheses.
* p<.1, ** p<.05, ***p<.01
80.4. 内生性#
[Acemoglu et al., 2001] 指出,使用OLS模型估计制度对经济发展的影响时,我们面临一个重要的挑战 - 内生性问题。这个问题会导致我们的估计结果产生偏差。
为什么会存在内生性呢?主要是因为制度质量和经济发展水平之间可能相互影响:
较富裕的国家可能有能力负担或倾向于选择更好的制度
影响收入的变量可能也与制度差异相关
指数的构建可能存在偏差;分析师可能倾向于认为收入较高的国家拥有更好的制度
要解决这个问题,我们可以采用一种叫做**两阶段最小二乘法(2SLS)**的方法。
这种方法需要用一个变量来替代内生变量\({avexpr}_i\),该变量必须:
与\({avexpr}_i\)相关
与误差项不相关(即不应直接影响因变量,否则由于遗漏变量偏差会与\(u_i\)相关)
这组新的回归变量被称为工具变量,其目的是消除我们在衡量制度差异时的内生性问题。
[Acemoglu et al., 2001]的主要贡献在于使用殖民者死亡率作为制度差异的工具变量。
他们的论证是这样的:在死亡率高的地区,殖民者倾向于建立掠夺性的制度,主要目的是快速榨取资源而不是长期发展。
这些制度往往对私有财产保护不足,容易被征收。
而且由于制度具有持续性,这种制度特征一直延续到了今天。
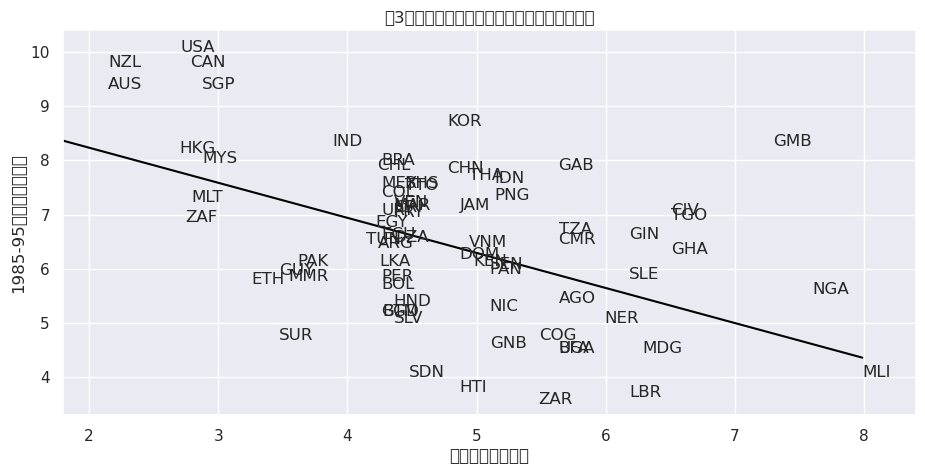
我们可以通过散点图(见[Acemoglu et al., 2001]的图3)验证这一假设。
图中显示,殖民者死亡率越高的地区,其防止征收风险指数越低(即财产保护程度越差)。
这种负相关关系支持了作者的假设,也满足了工具变量的第一个条件
# Dropping NA's is required to use numpy's polyfit
df1_subset2 = df1.dropna(subset=['logem4', 'avexpr'])
X = df1_subset2['logem4']
y = df1_subset2['avexpr']
labels = df1_subset2['shortnam']
# Replace markers with country labels
fig, ax = plt.subplots()
ax.scatter(X, y, marker='')
for i, label in enumerate(labels):
ax.annotate(label, (X.iloc[i], y.iloc[i]))
# Fit a linear trend line
ax.plot(np.unique(X),
np.poly1d(np.polyfit(X, y, 1))(np.unique(X)),
color='black')
ax.set_xlim([1.8,8.4])
ax.set_ylim([3.3,10.4])
ax.set_xlabel('殖民者死亡率对数')
ax.set_ylabel('1985-95年平均征收风险')
ax.set_title('图3:殖民者死亡率与征收风险之间的一阶关系')
plt.show()
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 24180 (\N{CJK UNIFIED IDEOGRAPH-5E74}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 24179 (\N{CJK UNIFIED IDEOGRAPH-5E73}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 22343 (\N{CJK UNIFIED IDEOGRAPH-5747}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 24449 (\N{CJK UNIFIED IDEOGRAPH-5F81}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 25910 (\N{CJK UNIFIED IDEOGRAPH-6536}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 39118 (\N{CJK UNIFIED IDEOGRAPH-98CE}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 38505 (\N{CJK UNIFIED IDEOGRAPH-9669}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 22270 (\N{CJK UNIFIED IDEOGRAPH-56FE}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 65306 (\N{FULLWIDTH COLON}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 27542 (\N{CJK UNIFIED IDEOGRAPH-6B96}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 27665 (\N{CJK UNIFIED IDEOGRAPH-6C11}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 32773 (\N{CJK UNIFIED IDEOGRAPH-8005}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 27515 (\N{CJK UNIFIED IDEOGRAPH-6B7B}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20129 (\N{CJK UNIFIED IDEOGRAPH-4EA1}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 29575 (\N{CJK UNIFIED IDEOGRAPH-7387}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 19982 (\N{CJK UNIFIED IDEOGRAPH-4E0E}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20043 (\N{CJK UNIFIED IDEOGRAPH-4E4B}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 38388 (\N{CJK UNIFIED IDEOGRAPH-95F4}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 30340 (\N{CJK UNIFIED IDEOGRAPH-7684}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 19968 (\N{CJK UNIFIED IDEOGRAPH-4E00}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 38454 (\N{CJK UNIFIED IDEOGRAPH-9636}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20851 (\N{CJK UNIFIED IDEOGRAPH-5173}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 31995 (\N{CJK UNIFIED IDEOGRAPH-7CFB}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 23545 (\N{CJK UNIFIED IDEOGRAPH-5BF9}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 25968 (\N{CJK UNIFIED IDEOGRAPH-6570}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
如果17至19世纪的殖民者死亡率对当前GDP有直接影响(除了通过制度产生的间接影响外),第二个条件可能就不成立。
例如,殖民者死亡率可能与一个国家当前的疾病环境有关,这可能会影响当前的经济表现。
[Acemoglu et al., 2001]认为这种情况不太可能,因为:
大多数殖民者死亡是由疟疾和黄热病引起的,对当地人的影响有限。
非洲或印度等地区的当地人的疾病负担似乎并不高于平均水平, 这一点从殖民前这些地区相对较高的人口密度可以得到证实。
由于我们似乎有了一个有效的工具变量,我们可以使用二阶段最小二乘法(2SLS)回归来获得一致且无偏的参数估计。
第一阶段
第一阶段包括对内生变量(\({avexpr}_i\))进行工具变量回归。
工具变量是我们模型中所有外生变量的集合(而不仅仅是我们替换的变量)。
以模型1为例,我们的工具变量仅包含一个常数项和殖民者死亡率\({logem4}_i\)。
因此,我们将估计如下的第一阶段回归:
让我们使用maketable4.dta文件中的数据来估计这个方程。我们只使用完整的观测值样本(用baseco = 1标识的数据)。
# 导入并选择数据
df4 = pd.read_stata('https://github.com/QuantEcon/lecture-python/blob/master/source/_static/lecture_specific/ols/maketable4.dta?raw=true')
df4 = df4[df4['baseco'] == 1]
# 添加常数变量
df4['const'] = 1
# 拟合第一阶段回归并打印摘要
results_fs = sm.OLS(df4['avexpr'],
df4[['const', 'logem4']],
missing='drop').fit()
print(results_fs.summary())
OLS Regression Results
==============================================================================
Dep. Variable: avexpr R-squared: 0.270
Model: OLS Adj. R-squared: 0.258
Method: Least Squares F-statistic: 22.95
Date: Mon, 03 Nov 2025 Prob (F-statistic): 1.08e-05
Time: 03:45:06 Log-Likelihood: -104.83
No. Observations: 64 AIC: 213.7
Df Residuals: 62 BIC: 218.0
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 9.3414 0.611 15.296 0.000 8.121 10.562
logem4 -0.6068 0.127 -4.790 0.000 -0.860 -0.354
==============================================================================
Omnibus: 0.035 Durbin-Watson: 2.003
Prob(Omnibus): 0.983 Jarque-Bera (JB): 0.172
Skew: 0.045 Prob(JB): 0.918
Kurtosis: 2.763 Cond. No. 19.4
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
第二阶段
我们需要使用.predict()来获取\({avexpr}_i\)的预测值。
然后在原始线性模型中,用预测值\(\widehat{avexpr}_i\)替换内生变量\({avexpr}_i\)。
因此,我们的第二阶段回归为
df4['predicted_avexpr'] = results_fs.predict()
results_ss = sm.OLS(df4['logpgp95'],
df4[['const', 'predicted_avexpr']]).fit()
print(results_ss.summary())
OLS Regression Results
==============================================================================
Dep. Variable: logpgp95 R-squared: 0.477
Model: OLS Adj. R-squared: 0.469
Method: Least Squares F-statistic: 56.60
Date: Mon, 03 Nov 2025 Prob (F-statistic): 2.66e-10
Time: 03:45:06 Log-Likelihood: -72.268
No. Observations: 64 AIC: 148.5
Df Residuals: 62 BIC: 152.9
Df Model: 1
Covariance Type: nonrobust
====================================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------------
const 1.9097 0.823 2.320 0.024 0.264 3.555
predicted_avexpr 0.9443 0.126 7.523 0.000 0.693 1.195
==============================================================================
Omnibus: 10.547 Durbin-Watson: 2.137
Prob(Omnibus): 0.005 Jarque-Bera (JB): 11.010
Skew: -0.790 Prob(JB): 0.00407
Kurtosis: 4.277 Cond. No. 58.1
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
通过第二阶段回归,我们得到了制度对经济发展影响的无偏且一致的估计结果。
结果表明,制度质量与经济发展之间存在比OLS估计更强的正相关关系。这说明在控制内生性问题后,制度的影响实际上比简单回归显示的更大。
不过需要注意的是,虽然这种分步骤进行OLS回归的方法可以得到正确的参数估计,但由于没有考虑到第一阶段估计的不确定性,标准误差的计算并不准确。
因此在实践中,我们不建议用这种”手动”方式来进行2SLS估计。
我们可以使用linearmodels包(statsmodels的扩展)在一步中正确估计2SLS回归。
注意,在使用IV2SLS时,外生变量和工具变量在函数参数中是分开的(而之前工具变量包含了外生变量)。
在statsmodels中,我们使用exog参数来指定外生变量,使用instruments参数来指定工具变量。
iv = IV2SLS(dependent=df4['logpgp95'],
exog=df4['const'],
endog=df4['avexpr'],
instruments=df4['logem4']).fit(cov_type='unadjusted')
print(iv.summary)
IV-2SLS Estimation Summary
==============================================================================
Dep. Variable: logpgp95 R-squared: 0.1870
Estimator: IV-2SLS Adj. R-squared: 0.1739
No. Observations: 64 F-statistic: 37.568
Date: Mon, Nov 03 2025 P-value (F-stat) 0.0000
Time: 03:45:06 Distribution: chi2(1)
Cov. Estimator: unadjusted
Parameter Estimates
==============================================================================
Parameter Std. Err. T-stat P-value Lower CI Upper CI
------------------------------------------------------------------------------
const 1.9097 1.0106 1.8897 0.0588 -0.0710 3.8903
avexpr 0.9443 0.1541 6.1293 0.0000 0.6423 1.2462
==============================================================================
Endogenous: avexpr
Instruments: logem4
Unadjusted Covariance (Homoskedastic)
Debiased: False
鉴于我们现在已经获得了一致且无偏的估计,我们可以从所估计的模型中推断出,制度差异(源于殖民时期建立的制度)可以帮助解释当今各国之间的收入水平差异。
[Acemoglu et al., 2001]使用0.94的边际效应来计算,智利和尼日利亚之间的指数差异(即制度质量)意味着收入可能相差高达7倍,这强调了制度在经济发展中的重要性。
80.5. 总结#
我们已经演示了在statsmodels和linearmodels中的基本OLS和2SLS回归。
80.6. 练习#
练习 80.1
在前面的讲座中,我们讨论了原始模型中的内生性问题。这个问题源于收入水平可能反过来影响制度的发展,从而导致估计结果产生偏差。
虽然识别内生性问题最好是通过仔细分析数据和模型的经济含义,但我们也可以使用一个统计工具——豪斯曼检验来正式验证内生性的存在。
具体来说,我们要检验内生变量(制度质量指标\(avexpr_i\))是否与回归方程的误差项\(u_i\)相关。
如果存在相关性,就说明存在内生性问题
这个检验分两个阶段进行。
首先,我们对工具变量\(logem4_i\)回归\(avexpr_i\)
其次,我们获取残差\(\hat{\upsilon}_i\)并将其纳入原方程
如果\(\alpha\)在统计上显著(p值<0.05),那么我们就拒绝原假设,得出\(avexpr_i\)是内生的结论。
使用上述信息,估算豪斯曼检验并解释你的结果。
解答 练习 80.1
# 加载数据
df4 = pd.read_stata('https://github.com/QuantEcon/lecture-python/blob/master/source/_static/lecture_specific/ols/maketable4.dta?raw=true')
# 添加常数项
df4['const'] = 1
# 估算第一阶段回归
reg1 = sm.OLS(endog=df4['avexpr'],
exog=df4[['const', 'logem4']],
missing='drop').fit()
# 获取残差
df4['resid'] = reg1.resid
# 估算第二阶段残差
reg2 = sm.OLS(endog=df4['logpgp95'],
exog=df4[['const', 'avexpr', 'resid']],
missing='drop').fit()
print(reg2.summary())
OLS Regression Results
==============================================================================
Dep. Variable: logpgp95 R-squared: 0.689
Model: OLS Adj. R-squared: 0.679
Method: Least Squares F-statistic: 74.05
Date: Mon, 03 Nov 2025 Prob (F-statistic): 1.07e-17
Time: 03:45:06 Log-Likelihood: -62.031
No. Observations: 70 AIC: 130.1
Df Residuals: 67 BIC: 136.8
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 2.4782 0.547 4.530 0.000 1.386 3.570
avexpr 0.8564 0.082 10.406 0.000 0.692 1.021
resid -0.4951 0.099 -5.017 0.000 -0.692 -0.298
==============================================================================
Omnibus: 17.597 Durbin-Watson: 2.086
Prob(Omnibus): 0.000 Jarque-Bera (JB): 23.194
Skew: -1.054 Prob(JB): 9.19e-06
Kurtosis: 4.873 Cond. No. 53.8
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
输出结果显示残差系数具有统计显著性,表明 \(avexpr_i\) 是内生的。
练习 80.2
OLS参数 \(\beta\) 也可以使用矩阵代数和 numpy 来估计(你可能需要复习
numpy 课程来
完成这个练习)。
我们要估计的线性方程(用矩阵形式表示)是
为了求解未知参数 \(\beta\),我们要最小化残差平方和
重新整理第一个方程并代入第二个方程,我们可以写成
解这个优化问题得到 \(\hat{\beta}\) 系数的解为
使用上述信息,计算模型1中的 \(\hat{\beta}\)
使用 numpy - 你的结果应该与讲座前面 statsmodels 的输出结果相同。
解答 练习 80.2
# 加载数据
df1 = pd.read_stata('https://github.com/QuantEcon/lecture-python/blob/master/source/_static/lecture_specific/ols/maketable1.dta?raw=true')
df1 = df1.dropna(subset=['logpgp95', 'avexpr'])
# 添加常数项
df1['const'] = 1
# 定义 X 和 y 变量
y = np.asarray(df1['logpgp95'])
X = np.asarray(df1[['const', 'avexpr']])
# 计算 β_hat
β_hat = np.linalg.solve(X.T @ X, X.T @ y)
# 打印 2 x 1 向量 β_hat 的结果
print(f'β_0 = {β_hat[0]:.2}')
print(f'β_1 = {β_hat[1]:.2}')
β_0 = 4.6
β_1 = 0.53
也可以使用 np.linalg.inv(X.T @ X) @ X.T @ y 来求解 \(\beta\),但是推荐使用 .solve(),因为它涉及的计算更少。