26. 让弥尔顿·弗里德曼困惑的问题#
(而亚伯拉罕·瓦尔德通过发明序贯分析解决了这个问题)
26.1. 概述#
这是关于一个统计决策问题的两个讲座中的第一个。这个问题是二战期间,当弥尔顿·弗里德曼和W·艾伦·沃利斯在哥伦比亚大学的美国政府统计研究组担任分析师时,一位美国海军上尉向他们提出的。
这个问题促使亚伯拉罕·瓦尔德[Wald, 1947]提出了序贯分析,这是一种与动态规划密切相关的统计决策问题处理方法。
本讲座及其续篇延续了之前讲座的精神,从频率主义和贝叶斯两个不同的角度来处理这个问题。
在本讲中,我们从一位统计学家的角度描述Wald的问题表述,这位统计学家遵循Neyman-Pearson的频率派统计学传统,关注假设检验,并因此使用大数定律来研究在给定假设下特定统计量的极限性质,即,一个参数向量确定了统计学家感兴趣的统计模型簇中的某个特定成员。
从这节关于频率派和贝叶斯统计的讲座中,请记住频率派统计学家经常计算随机变量序列的函数,以参数向量为条件。
在这个相关讲座中,我们将讨论另一种表述方法,它采用贝叶斯统计学家的视角,将参数视为与他所关心的可观测变量共同分布的随机变量。
因为我们采用的是关注在不同参数值(即不同假设)条件下相对频率的频率派视角,本讲的关键概念包括:
第一类和第二类统计错误
第一类错误是指在原假设为真时拒绝原假设
第二类错误是指在原假设为假时接受原假设
频率派统计检验的检验效能
频率派统计检验的显著性水平
统计检验的临界区域
一致最优检验
大数定律(LLN)在解释频率统计检验的功效和规模中的作用
亚伯拉罕·瓦尔德的序贯概率比检验
我们先导入一些包:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
from numba import njit, prange, vectorize, jit
from numba.experimental import jitclass
from math import gamma
from scipy.integrate import quad
from scipy.stats import beta
from collections import namedtuple
import pandas as pd
import scipy as sp
26.2. 问题的来源#
在米尔顿·弗里德曼与罗斯·弗里德曼1998年合著的《两个幸运儿》一书的137-139页[Friedman and Friedman, 1998]中,米尔顿·弗里德曼描述了二战期间他和艾伦·沃利斯在哥伦比亚大学美国政府统计研究组工作时遇到的一个问题。
备注
参见艾伦·沃利斯1980年发表的文章[Wallis, 1980]第25和26页,其中讲述了二战期间在哥伦比亚大学统计研究组的这段经历,以及哈罗德·霍特林对问题形成所作出的重要贡献。另见珍妮弗·伯恩斯关于米尔顿·弗里德曼的著作[Burns, 2023]第5章。
让我们听听米尔顿·弗里德曼是如何讲述这件事的:
要理解这个故事,需要先了解一个简单的统计问题及其标准处理程序。序贯分析由此产生的实际问题就很合适。海军有两种备选的炮弹设计(比如说A和B),想要确定哪一个更好。为此,海军进行了一系列成对的试射。每一轮中,如果A的表现优于B,则给A记1分,B记0分;反之,如果A的表现不如B,则给A记0分,B记1分。海军请统计学家
如何进行测试以及如何分析结果。
标准的统计答案是指定发射次数(比如1,000次)和一对百分比(例如53%和47%),并告诉客户如果A在超过53%的发射中获得1分,就可以认为A更优;如果在少于47%的发射中获得1分,则可以认为B更优;如果百分比在47%到53%之间,则两者都不能被认为更优。
当Allen Wallis与(海军)Garret L. Schuyler上尉讨论这个问题时,上尉反对这样的测试,引用Allen的说法,这可能会造成浪费。如果像Schuyler这样明智且经验丰富的军需官在现场,他在前几千发甚至前几百发[弹药]后就会发现实验不需要完成,要么是因为新方法明显较差,要么是因为它明显优于预期\(\ldots\)。
Friedman和Wallis研究了这个问题一段时间但没有完全解决它。
意识到这一点后,他们把这个问题告诉了Abraham Wald。
这让Wald走上了一条创造序贯分析[Wald, 1947]的道路。
26.3. Neyman-Pearson公式#
从描述美国海军告诉G. S. Schuyler上尉使用的测试背后的理论开始会很有帮助。
Schuyler上尉的疑虑促使他向Milton Friedman和Allen Wallis表达了他的推测,即存在更好的实践程序。
显然,海军当时要求Schuyler上校使用当时最先进的Neyman-Pearson假设检验。
我们将依据Abraham Wald的[Wald, 1947]对Neyman-Pearson理论的优雅总结。
请注意以下设置特点:
假定固定样本量\(n\)
应用大数定律(在不同概率模型条件下)来解释Neyman-Pearson理论中定义的第一类错误和第二类错误的概率\(\alpha\)和\(\beta\)
在序贯分析[Wald, 1947]第一章中,Abraham Wald总结了Neyman-Pearson的假设检验方法。
Wald将问题框定为对部分已知的概率分布做出决策。
(你必须假设某些内容是已知的,才能提出一个明确的问题 – 通常,某些意味着很多)
通过限制未知部分,Wald使用以下简单结构来说明主要思想:
决策者想要决定两个分布\(f_0\)、\(f_1\)中哪一个支配独立同分布随机变量\(z\)。
原假设\(H_0\)是指\(f_0\)支配数据的陈述。
备择假设\(H_1\)是指\(f_1\)支配数据的陈述。
问题是基于固定数量\(n\)个独立观测值\(z_1, z_2, \ldots, z_n\)设计并分析一个检验原假设\(H_0\)对备择假设\(H_1\)的检验。
引用Abraham Wald的话:
导致接受或拒绝[零]假设的检验程序,简单来说就是一个规则,它为每个可能的样本量 \(n\)规定是否应该基于该样本接受或拒绝[零]假设。这也可以表述如下:检验程序 就是将所有可能的样本量\(n\)的总体划分为两个互斥的部分,比如说第1部分和第2部分, 同时应用这样的规则:如果观察到的样本包含在第2部分中,则接受[零]假设。第1部分 也被称为临界区域。由于第2部分是所有不包含在第1部分中的样本量\(n\)的总体, 第2部分由第1部分唯一确定。因此,选择检验程序等同于确定临界区域。
让我们继续听Wald的话:
Neyman和Pearson提出了以下选择临界区域的考虑因素:在接受或拒绝\(H_0\)时, 我们可能犯两种错误。当\(H_0\)为真而我们拒绝它时,我们犯第一类错误;当 \(H_1\)为真而我们接受\(H_0\)时,我们犯第二类错误。在选定特定的临界区域 \(W\)之后,犯第一类错误的概率以及犯第二类错误的概率
第一类错误是唯一确定的。第一类错误的概率等于在假设\(H_0\)为真的条件下,观察到的样本落入临界区域\(W\)的概率。第二类错误的概率等于在假设\(H_1\)为真的条件下,概率落在临界区域\(W\)之外的概率。对于任何给定的临界区域\(W\),我们用\(\alpha\)表示第一类错误的概率,用\(\beta\)表示第二类错误的概率。
让我们仔细听听Wald如何运用大数定律来解释\(\alpha\)和\(\beta\):
概率\(\alpha\)和\(\beta\)有以下重要的实际解释:假设我们抽取大量规模为\(n\)的样本。设\(M\)为抽取的样本数。假设对于这\(M\)个样本中的每一个,如果样本落入\(W\)则拒绝\(H_0\),如果样本落在\(W\)之外则接受\(H_0\)。通过这种方式,我们做出\(M\)个拒绝或接受的判断。这些判断中的一些通常会是错误的。如果\(H_0\)为真且\(M\)很大,则错误判断的比例(即错误判断数除以\(M\))约为\(\alpha\)的概率接近于\(1\)(即几乎可以确定)。如果\(H_1\)为真,则错误判断的比例约为
错误陈述的比例将大约为\(\beta\)。 因此,我们可以说从长远来看[这里Wald应用大数定律,让\(M \rightarrow \infty\)(这是我们的注释,不是Wald的)],如果\(H_0\)为真,错误陈述的比例将是\(\alpha\),如果\(H_1\)为真,则为\(\beta\)。
量\(\alpha\)被称为临界区域的大小,而量\(1-\beta\)被称为临界区域的检验力。
Wald指出
如果一个临界区域\(W\)具有较小的\(\alpha\)和\(\beta\)值,那么它比另一个更可取。虽然通过适当选择临界区域\(W\),可以使\(\alpha\)或\(\beta\)任意小,但对于固定的\(n\)值(即固定的样本量),不可能同时使\(\alpha\)和\(\beta\)都任意小。
Wald总结了Neyman和Pearson的设置如下:
Neyman和Pearson表明,由满足以下不等式的所有样本\((z_1, z_2, \ldots, z_n)\)组成的区域
\[ \frac{ f_1(z_1) \cdots f_1(z_n)}{f_0(z_1) \cdots f_0(z_n)} \geq k \]是检验假设\(H_0\)对抗备择假设\(H_1\)的最优势检验区域。右边的项\(k\)是一个常数,选择它使得该区域具有所需的大小\(\alpha\)。
Wald继续讨论了Neyman和Pearson的一致最优势检验的概念。
以下是Wald如何引入序贯检验的概念
在实验的任何阶段(对于每个整数值\(m\)的第\(m\)次试验),都给出一个规则来做出以下三个决定之一: (1)接受假设\(H\),(2)拒绝假设\(H\),(3)通过进行额外的观察来继续实验。因此, 这样的检验程序是按顺序进行的。基于第一次观察,做出上述决定之一。如果做出 第一个或第二个决定,过程就终止。如果做出第三个决定,就进行第二次试验。 同样,基于前两次观察,做出三个决定之一。如果做出第三个决定,就进行第三次 试验,依此类推。这个过程持续进行,直到做出第一个或第二个决定为止。这种 检验程序所需的观察次数\(n\)是一个随机变量,因为\(n\)的值取决于观察的结果。
26.4. 瓦尔德的序贯表述#
与奈曼-皮尔逊问题表述的对比,在瓦尔德的表述中:
样本量\(n\)不是固定的,而是一个随机变量。
两个参数\(A\)和\(B\)与奈曼-皮尔逊的\(\alpha\)和\(\beta\)相关但不同; \(A\)和\(B\)表征了瓦尔德用来确定随机变量\(n\)作为随机结果函数的截止规则。
以下是瓦尔德如何设置这个问题。
决策者可以观察一个随机变量 \(z\) 的一系列抽样。
他(或她)想要知道是哪一个概率分布 \(f_0\) 或 \(f_1\) 支配着 \(z\)。
我们使用贝塔分布作为例子。
我们还将使用在 统计散度度量 中介绍的 Jensen-Shannon 散度。
@vectorize
def p(x, a, b):
"""贝塔分布密度函数。"""
r = gamma(a + b) / (gamma(a) * gamma(b))
return r * x** (a-1) * (1 - x) ** (b-1)
def create_beta_density(a, b):
"""创建具有指定参数的贝塔密度函数。"""
return jit(lambda x: p(x, a, b))
def compute_KL(f, g):
"""计算KL散度 KL(f, g)"""
integrand = lambda w: f(w) * np.log(f(w) / g(w))
val, _ = quad(integrand, 1e-5, 1-1e-5)
return val
def compute_JS(f, g):
"""计算Jensen-Shannon散度"""
def m(w):
return 0.5 * (f(w) + g(w))
js_div = 0.5 * compute_KL(f, m) + 0.5 * compute_KL(g, m)
return js_div
下图显示了两个贝塔分布
f0 = create_beta_density(1, 1)
f1 = create_beta_density(9, 9)
grid = np.linspace(0, 1, 50)
fig, ax = plt.subplots()
ax.plot(grid, f0(grid), lw=2, label="$f_0$")
ax.plot(grid, f1(grid), lw=2, label="$f_1$")
ax.legend()
ax.set(xlabel="$z$ 值", ylabel="$z_k$ 的概率")
plt.tight_layout()
plt.show()

在已知连续观测值来自分布\(f_0\)的条件下,这个随机变量序列是独立同分布的(IID)。
在已知连续观测值来自分布\(f_1\)的条件下,这个随机变量序列也是独立同分布的(IID)。
但是观察者并不知道序列是由这两个分布中的哪一个生成的。
由可交换性和贝叶斯更新中解释的原因,这意味着观察者认为该序列不是IID的。
因此,观察者有需要学习的内容,即观测值是来自\(f_0\)还是来自\(f_1\)。
决策者想要确定是哪一个分布在生成结果。
26.4.1. 第一类错误和第二类错误#
如果我们将\(f=f_0\)视为零假设,将\(f=f_1\)视为备择假设,那么:
第一类错误是错误地拒绝了真的零假设(“假阳性”)
第二类错误是未能拒绝假的零假设(“假阴性”)
重申一下:
\(\alpha\)是第一类错误的概率
\(\beta\)是第二类错误的概率
26.4.2. 选择#
在观察到\(z_k, z_{k-1}, \ldots, z_1\)后,决策者可以在三个不同的行动中选择:
他决定\(f = f_0\)并停止获取更多的\(z\)值
他决定\(f = f_1\)并停止获取更多的\(z\)值
他推迟做决定,转而选择抽取 \(z_{k+1}\)
Wald定义
\(p_{0m} = f_0(z_1) \cdots f_0(z_m)\)
\(p_{1m} = f_1(z_1) \cdots f_1(z_m)\)
\(L_{m} = \frac{p_{1m}}{p_{0m}}\)
这里\(\{L_m\}_{m=0}^\infty\)是一个似然比过程。
Wald的序贯决策规则由实数\(B < A\)参数化。
对于给定的一对\(A, B\),决策规则是
下图说明了Wald程序的各个方面。

26.5. \(A,B\)与\(\alpha, \beta\)之间的联系#
在序贯分析[Wald, 1947]第3章中,Wald建立了以下不等式
他对这些不等式的分析导致Wald推荐以下近似作为设置\(A\)和\(B\)的规则,这些规则接近于达到决策者对第I类错误概率\(\alpha\)和第II类错误概率\(\beta\)的目标值:
对于较小的 \(\alpha\) 和 \(\beta\) 值,Wald表明近似式 (26.1) 提供了一个设定 \(A\) 和 \(B\) 的良好方法。
特别地,Wald构建了一个数学论证,使他得出结论:使用近似式 (26.1) 而不是真实函数 \(A (\alpha, \beta), B(\alpha,\beta)\) 来设定 \(A\) 和 \(B\)
\(\ldots\) 不会导致 \(\alpha\) 或 \(\beta\) 的值有任何显著增加。换句话说, 就实际目的而言,对应于 \(A = a(\alpha, \beta), B = b(\alpha,\beta)\) 的检验 至少提供了与对应于 \(A = A(\alpha, \beta)\) 和 \(B = b(\alpha, \beta)\) 的检验相同的防错决策保护。
因此,使用 \( a(\alpha, \beta), b(\alpha,\beta)\) 而不是 \( A(\alpha, \beta), B(\alpha,\beta)\) 可能产生的唯一缺点是, 这可能会导致检验所需的观测数量显著增加。
我们将编写一些Python代码来帮助我们说明Wald关于 \(\alpha\) 和 \(\beta\) 如何与表征其序贯概率比检验的参数 \(A\) 和 \(B\) 相关的论断。
26.6. 模拟#
我们尝试不同的分布 \(f_0\) 和 \(f_1\) 来研究Wald检验在各种条件下的表现。
进行这些模拟的目的是为了理解Wald的序贯概率比检验在决策速度和准确性之间的权衡。
具体来说,我们将观察:
决策阈值 \(A\) 和 \(B\) (或等效的目标错误率 \(\alpha\) 和 \(\beta\)) 如何影响平均停止时间
分布 \(f_0\) 和 \(f_1\) 之间的差异如何影响平均停止时间
我们将重点关注 \(f_0\) 和 \(f_1\) 为贝塔分布的情况,因为通过调整其形状参数可以轻松控制两个密度的重叠区域。
首先,我们定义一个命名元组来存储我们进行模拟研究所需的所有参数。
我们还根据目标第一类和第二类错误 \(\alpha\) 和 \(\beta\) 计算Wald推荐的阈值 \(A\) 和 \(B\)
SPRTParams = namedtuple('SPRTParams',
['α', 'β', # 目标第一类和第二类错误
'a0', 'b0', # f_0的形状参数
'a1', 'b1', # f_1的形状参数
'N', # 模拟次数
'seed'])
@njit
def compute_wald_thresholds(α, β):
"""计算Wald推荐的阈值。"""
A = (1 - β) / α
B = β / (1 - α)
return A, B, np.log(A), np.log(B)
现在我们可以按照Wald的建议运行模拟。
我们将对数似然比与阈值的对数 \(\log(A)\) 和 \(\log(B)\) 进行比较。
以下算法是我们模拟的基础。
计算阈值 \(A = \frac{1-\beta}{\alpha}\), \(B = \frac{\beta}{1-\alpha}\) 并使用 \(\log A\), \(\log B\)。
给定真实分布(要么是 \(f_0\) 或 \(f_1\)):
初始化对数似然比 \(\log L_0 = 0\)
重复:
从真实分布中抽取观测值 \(z\)
更新: \(\log L_{n+1} \leftarrow \log L_n + (\log f_1(z) - \log f_0(z))\)
如果 \(\log L_{n+1} \geq \log A\): 停止,拒绝 \(H_0\)
如果 \(\log L_{n+1} \leq \log B\): 停止,接受 \(H_0\)
对每个分布重复步骤2进行 \(N/2\) 次重复,总共 \(N\) 次重复,计算经验第一类错误 \(\hat{\alpha}\) 和第二类错误 \(\hat{\beta}\):
@njit
def sprt_single_run(a0, b0, a1, b1, logA, logB, true_f0, seed):
"""运行单次SPRT直到达到决策。"""
log_L = 0.0
n = 0
np.random.seed(seed)
while True:
z = np.random.beta(a0, b0) if true_f0 else np.random.beta(a1, b1)
n += 1
# 更新对数似然比
log_L += np.log(p(z, a1, b1)) - np.log(p(z, a0, b0))
# 检查停止条件
if log_L >= logA:
return n, False # 拒绝H0
elif log_L <= logB:
return n, True # 接受H0
@njit(parallel=True)
def run_sprt_simulation(a0, b0, a1, b1, α, β, N, seed):
"""SPRT模拟。"""
A, B, logA, logB = compute_wald_thresholds(α, β)
stopping_times = np.zeros(N, dtype=np.int64)
decisions_h0 = np.zeros(N, dtype=np.bool_)
truth_h0 = np.zeros(N, dtype=np.bool_)
for i in prange(N):
true_f0 = (i % 2 == 0)
truth_h0[i] = true_f0
n, accept_f0 = sprt_single_run(
a0, b0, a1, b1,
logA, logB,
true_f0, seed + i)
stopping_times[i] = n
decisions_h0[i] = accept_f0
return stopping_times, decisions_h0, truth_h0
def run_sprt(params):
"""使用给定参数运行SPRT模拟。"""
stopping_times, decisions_h0, truth_h0 = run_sprt_simulation(
params.a0, params.b0, params.a1, params.b1,
params.α, params.β, params.N, params.seed
)
# 计算错误率
truth_h0_bool = truth_h0.astype(bool)
decisions_h0_bool = decisions_h0.astype(bool)
type_I = np.sum(truth_h0_bool & ~decisions_h0_bool) \
/ np.sum(truth_h0_bool)
type_II = np.sum(~truth_h0_bool & decisions_h0_bool) \
/ np.sum(~truth_h0_bool)
return {
'stopping_times': stopping_times,
'decisions_h0': decisions_h0_bool,
'truth_h0': truth_h0_bool,
'type_I': type_I,
'type_II': type_II
}
# 运行模拟
params = SPRTParams(α=0.05, β=0.10, a0=2, b0=5, a1=5, b1=2, N=20000, seed=1)
results = run_sprt(params)
print(f"平均停止时间: {results['stopping_times'].mean():.2f}")
print(f"经验第一类错误: {results['type_I']:.3f} (目标 = {params.α})")
print(f"经验第二类错误: {results['type_II']:.3f} (目标 = {params.β})")
平均停止时间: 1.59
经验第一类错误: 0.012 (目标 = 0.05)
经验第二类错误: 0.022 (目标 = 0.1)
正如在上文中 Wald 讨论近似式 (26.1) 中给出的 \(a(\alpha, \beta), b(\alpha, \beta)\) 的质量时所预期的那样,我们发现该算法实际上给出了比目标值更低的第一类和第二类错误率。
备注
关于近似式 (26.1) 质量的最新研究,请参见 [Fischer and Ramdas, 2024]。
以下代码创建了几个图表来展示我们的模拟结果。
让我们绘制模拟的结果
plot_sprt_results(results, params)
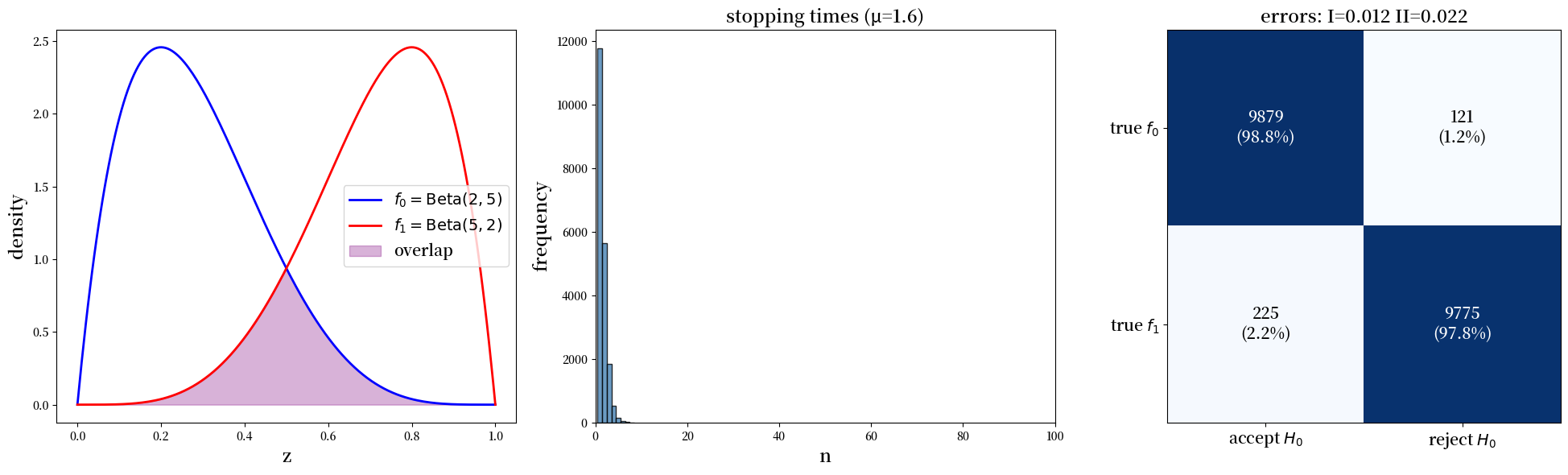
在这个例子中,停止时间保持在10以下。
我们可以构建一个\(2 \times 2\)的”混淆矩阵”,其对角线元素统计了Wald决策规则正确接受和正确拒绝原假设的次数。
print("混淆矩阵数据:")
print(f"第一类错误:{results['type_I']:.3f}")
print(f"第二类错误:{results['type_II']:.3f}")
混淆矩阵数据:
第一类错误:0.012
第二类错误:0.022
接下来我们使用代码研究三对不同的 \(f_0, f_1\) 分布,它们之间有不同程度的差异。
我们为每对分布绘制与上面相同的三种图表
params_1 = SPRTParams(α=0.05, β=0.10, a0=2, b0=8, a1=8, b1=2, N=5000, seed=42)
results_1 = run_sprt(params_1)
params_2 = SPRTParams(α=0.05, β=0.10, a0=4, b0=5, a1=5, b1=4, N=5000, seed=42)
results_2 = run_sprt(params_2)
params_3 = SPRTParams(α=0.05, β=0.10, a0=0.5, b0=0.4, a1=0.4,
b1=0.5, N=5000, seed=42)
results_3 = run_sprt(params_3)
plot_sprt_results(results_1, params_1)

plot_sprt_results(results_2, params_2)

plot_sprt_results(results_3, params_3)

请注意,当两个分布相距较远时,停止时间会更短。
这是很合理的。
当两个分布”相距较远”时,判断哪个分布在产生数据不应该需要太长时间。
当两个分布”相近”时,判断哪个分布在产生数据应该需要更长时间。
我们很容易想到将这种模式与我们在似然比过程中讨论的Kullback–Leibler散度联系起来。
虽然当两个分布差异更大时KL散度更大,但KL散度并不是对称的,这意味着分布\(f\)相对于分布\(g\)的KL散度不一定等于\(g\)相对于\(f\)的KL散度。
如果我们想要一个真正具有度量性质的对称散度,我们可以使用Jensen-Shannon距离。
这就是我们现在要做的。
我们将计算Jensen-Shannon距离,并绘制它与平均停止时间的关系图。
def js_dist(a0, b0, a1, b1):
"""Jensen–Shannon距离"""
f0 = create_beta_density(a0, b0)
f1 = create_beta_density(a1, b1)
# 混合
m = lambda w: 0.5*(f0(w) + f1(w))
return np.sqrt(0.5*compute_KL(m, f0) + 0.5*compute_KL(m, f1))
def generate_β_pairs(N=100, T=10.0, d_min=0.5, d_max=9.5):
ds = np.linspace(d_min, d_max, N)
a0 = (T - ds) / 2
b0 = (T + ds) / 2
return list(zip(a0, b0, b0, a0))
param_comb = generate_β_pairs()
# 为每个参数组合运行模拟
js_dists = []
mean_stopping_times = []
param_list = []
for a0, b0, a1, b1 in param_comb:
# 计算KL散度
js_div = js_dist(a1, b1, a0, b0)
# 用固定参数集运行SPRT模拟
params = SPRTParams(α=0.05, β=0.10, a0=a0, b0=b0,
a1=a1, b1=b1, N=5000, seed=42)
results = run_sprt(params)
js_dists.append(js_div)
mean_stopping_times.append(results['stopping_times'].mean())
param_list.append((a0, b0, a1, b1))
# 创建图表
fig, ax = plt.subplots()
scatter = ax.scatter(js_dists, mean_stopping_times,
s=80, alpha=0.7, linewidth=0.5)
ax.set_xlabel('Jensen–Shannon距离', fontsize=14)
ax.set_ylabel('平均停止时间', fontsize=14)
plt.tight_layout()
plt.show()
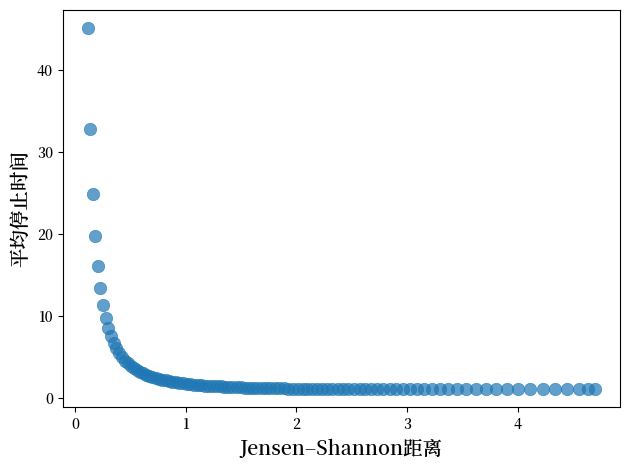
该图显示了相对熵与平均停止时间之间存在明显的负相关关系。
随着Jensen-Shannon散度的增加(分布之间的差异增大),平均停止时间呈指数下降。
以下是我们上述实验的采样示例
def plot_beta_distributions_grid(param_list, js_dists, mean_stopping_times,
selected_indices=None):
"""绘制贝塔分布网格,包含JS距离和停止时间。"""
if selected_indices is None:
selected_indices = [0, len(param_list)//6, len(param_list)//3,
len(param_list)//2, 2*len(param_list)//3, -1]
fig, axes = plt.subplots(2, 3, figsize=(15, 8))
z_grid = np.linspace(0, 1, 200)
for i, idx in enumerate(selected_indices):
row, col = i // 3, i % 3
a0, b0, a1, b1 = param_list[idx]
f0 = create_beta_density(a0, b0)
f1 = create_beta_density(a1, b1)
axes[row, col].plot(z_grid, f0(z_grid), 'b-', lw=2, label='$f_0$')
axes[row, col].plot(z_grid, f1(z_grid), 'r-', lw=2, label='$f_1$')
axes[row, col].fill_between(z_grid, 0,
np.minimum(f0(z_grid), f1(z_grid)),
alpha=0.3, color='purple')
axes[row, col].set_title(f'JS距离: {js_dists[idx]:.3f}'
f'\n平均时间: {mean_stopping_times[idx]:.1f}',
fontsize=12)
axes[row, col].set_xlabel('z', fontsize=10)
if i == 0:
axes[row, col].set_ylabel('密度', fontsize=10)
axes[row, col].legend(fontsize=10)
plt.tight_layout()
plt.show()
plot_beta_distributions_grid(param_list, js_dists, mean_stopping_times)

再次发现,当分布之间的差异越大(用Jensen-Shannon距离衡量),停止时间就越短。
让我们可视化单个似然比过程,看看它们是如何向决策边界演变的。
def plot_likelihood_paths(params, n_highlight=10, n_background=200):
"""可视化似然比路径。"""
A, B, logA, logB = compute_wald_thresholds(params.α, params.β)
f0, f1 = map(lambda ab: create_beta_density(*ab),
[(params.a0, params.b0),
(params.a1, params.b1)])
fig, axes = plt.subplots(1, 2, figsize=(14, 7))
for dist_idx, (true_f0, ax, title) in enumerate([
(True, axes[0], '真实分布: $f_0$'),
(False, axes[1], '真实分布: $f_1$')
]):
rng = np.random.default_rng(seed=42 + dist_idx)
paths_data = []
# 生成路径
for path in range(n_background + n_highlight):
log_L_path, log_L, n = [0.0], 0.0, 0
while True:
z = rng.beta(params.a0, params.b0) if true_f0 \
else rng.beta(params.a1, params.b1)
n += 1
log_L += np.log(f1(z)) - np.log(f0(z))
log_L_path.append(log_L)
if log_L >= logA or log_L <= logB:
paths_data.append((log_L_path, n, log_L >= logA))
break
# 绘制背景路径
for path, _, decision in paths_data[:n_background]:
ax.plot(range(len(path)), path, color='C1' if decision else 'C0',
alpha=0.2, linewidth=0.5)
# 绘制高亮路径及标签
for i, (path, _, decision) in enumerate(paths_data[n_background:]):
ax.plot(range(len(path)), path, color='C1' if decision else 'C0',
alpha=0.8, linewidth=1.5,
label='拒绝 $H_0$' if decision and i == 0 else (
'接受 $H_0$' if not decision and i == 0 else ''))
# 添加阈值线和格式化
ax.axhline(y=logA, color='C1', linestyle='--', linewidth=2,
label=f'$\\log A = {logA:.2f}$')
ax.axhline(y=logB, color='C0', linestyle='--', linewidth=2,
label=f'$\\log B = {logB:.2f}$')
ax.axhline(y=0, color='black', linestyle='-', alpha=0.5, linewidth=1)
ax.set_xlabel(r'$n$')
ax.set_ylabel(r'$\log(L_n)$')
ax.set_title(title, fontsize=20)
ax.legend(fontsize=18, loc='center right')
y_margin = max(abs(logA), abs(logB)) * 0.2
ax.set_ylim(logB - y_margin, logA + y_margin)
plt.tight_layout()
plt.show()
plot_likelihood_paths(params_3, n_highlight=10, n_background=100)

接下来,让我们调整决策阈值 \(A\) 和 \(B\),并观察平均停止时间以及第一类和第二类错误率的变化。
在下面的代码中,我们通过调整因子 \(A_f\) 和 \(B_f\) 来调整 Wald 规则的阈值。
@njit(parallel=True)
def run_adjusted_thresholds(a0, b0, a1, b1, α, β, N, seed, A_f, B_f):
"""带有调整阈值的 SPRT 模拟。"""
# 计算原始阈值
A_original = (1 - β) / α
B_original = β / (1 - α)
# 应用调整因子
A_adj = A_original * A_f
B_adj = B_original * B_f
logA = np.log(A_adj)
logB = np.log(B_adj)
# 预分配数组
stopping_times = np.zeros(N, dtype=np.int64)
decisions_h0 = np.zeros(N, dtype=np.bool_)
truth_h0 = np.zeros(N, dtype=np.bool_)
# 并行运行模拟
for i in prange(N):
true_f0 = (i % 2 == 0)
truth_h0[i] = true_f0
n, accept_f0 = sprt_single_run(a0, b0, a1, b1,
logA, logB, true_f0, seed + i)
stopping_times[i] = n
decisions_h0[i] = accept_f0
return stopping_times, decisions_h0, truth_h0, A_adj, B_adj
def run_adjusted(params, A_f=1.0, B_f=1.0):
"""运行带有调整 A 和 B 阈值的 SPRT 的包装函数。"""
stopping_times, decisions_h0, truth_h0, A_adj, B_adj = run_adjusted_thresholds(
params.a0, params.b0, params.a1, params.b1,
params.α, params.β, params.N, params.seed, A_f, B_f
)
truth_h0_bool = truth_h0.astype(bool)
decisions_h0_bool = decisions_h0.astype(bool)
# 计算错误率
type_I = np.sum(truth_h0_bool
& ~decisions_h0_bool) / np.sum(truth_h0_bool)
type_II = np.sum(~truth_h0_bool
& decisions_h0_bool) / np.sum(~truth_h0_bool)
return {
'stopping_times': stopping_times,
'type_I': type_I,
'type_II': type_II,
'A_used': A_adj,
'B_used': B_adj
}
adjustments = [
(5.0, 0.5),
(1.0, 1.0),
(0.3, 3.0),
(0.2, 5.0),
(0.15, 7.0),
]
results_table = []
for A_f, B_f in adjustments:
result = run_adjusted(params_2, A_f, B_f)
results_table.append([
A_f, B_f,
f"{result['stopping_times'].mean():.1f}",
f"{result['type_I']:.3f}",
f"{result['type_II']:.3f}"
])
df = pd.DataFrame(results_table,
columns=["A_f", "B_f", "平均停止时间",
"第一类错误", "第二类错误"])
df = df.set_index(["A_f", "B_f"])
df
| 平均停止时间 | 第一类错误 | 第二类错误 | ||
|---|---|---|---|---|
| A_f | B_f | |||
| 5.00 | 0.5 | 16.1 | 0.006 | 0.036 |
| 1.00 | 1.0 | 11.1 | 0.033 | 0.070 |
| 0.30 | 3.0 | 5.5 | 0.086 | 0.195 |
| 0.20 | 5.0 | 3.4 | 0.120 | 0.304 |
| 0.15 | 7.0 | 2.2 | 0.146 | 0.410 |
让我们通过回顾(26.1)来更仔细地思考这个表格。
回想一下\(A = \frac{1-\beta}{\alpha}\)和\(B = \frac{\beta}{1-\alpha}\)。
当我们用小于1的因子乘以\(A\)(使\(A\)变小)时,我们实际上是在使拒绝原假设\(H_0\)变得更容易。
这增加了第一类错误的概率。
当我们用大于1的因子乘以\(B\)(使\(B\)变大)时,我们是在使接受原假设\(H_0\)变得更容易。
这增加了第二类错误的概率。
表格证实了这种直觉:当\(A\)减小且\(B\)增加超出其最优Wald值时,第一类和第二类错误率都会增加,而平均停止时间会减少。
26.7. 相关讲座#
我们将在以下早期和后续讲座中深入探讨这里使用的一些概念:
在这个续篇中,我们从贝叶斯统计学家的角度重新阐述了这个问题,他们将参数视为与他们关心的可观察量共同分布的随机变量向量。
可交换性的概念是统计学习的基础,在我们的可交换随机变量讲座中有深入探讨。
要深入理解似然比过程及其在频率派和贝叶斯统计理论中的作用,请参见似然比过程。
在此基础上,似然比过程和贝叶斯学习探讨了似然比过程在贝叶斯学习中的作用。
最后,这个后续讲座重新审视了这里讨论的主题,并探讨了海军命令船长使用的频率主义决策规则是否会比Abraham Wald的序贯决策规则表现得更好或更差。
26.8. 练习#
在下面的两个练习中,请尝试重写本讲座中的整个SPRT套件。
练习 26.1
在第一个练习中,我们将序贯概率比检验应用于区分由3状态马尔可夫链生成的两个模型
(关于马尔可夫链似然比过程的回顾,请参见本节。)
考虑使用Wald的序贯概率比检验来区分两个3状态马尔可夫链模型。
你有关于转移概率的竞争假设:
\(H_0\):链遵循转移矩阵 \(P^{(0)}\)
\(H_1\):链遵循转移矩阵 \(P^{(1)}\)
给定转移矩阵:
对于观测序列\((x_0, x_1, \ldots, x_t)\),似然比为:
其中\(\pi^{(i)}\)是假设\(i\)下的平稳分布。
任务:
实现马尔可夫链的似然比计算
实现Wald序贯检验,I类错误\(\alpha = 0.05\)和II类错误\(\beta = 0.10\)
在每个假设下运行1000次模拟并计算经验错误率
分析停止时间的分布
检验在以下情况停止:
\(\Lambda_t \geq A = \frac{1-\beta}{\alpha} = 18\): 拒绝\(H_0\)
\(\Lambda_t \leq B = \frac{\beta}{1-\alpha} = 0.105\): 接受\(H_0\)
解答 练习 26.1
以下是该练习的一个解决方案。
在讲座中,我们更详细地编写代码以清晰地说明概念。
在下面的代码中,我们简化了一些代码结构以便更简短地呈现。
首先我们定义马尔可夫链SPRT的参数
MarkovSPRTParams = namedtuple('MarkovSPRTParams',
['α', 'β', 'P_0', 'P_1', 'N', 'seed'])
def compute_stationary_distribution(P):
"""计算转移矩阵P的平稳分布。"""
eigenvalues, eigenvectors = np.linalg.eig(P.T)
idx = np.argmin(np.abs(eigenvalues - 1))
pi = np.real(eigenvectors[:, idx])
return pi / pi.sum()
@njit
def simulate_markov_chain(P, pi_0, T, seed):
"""模拟马尔可夫链路径。"""
np.random.seed(seed)
path = np.zeros(T, dtype=np.int32)
cumsum_pi = np.cumsum(pi_0)
path[0] = np.searchsorted(cumsum_pi, np.random.uniform())
for t in range(1, T):
cumsum_row = np.cumsum(P[path[t-1]])
path[t] = np.searchsorted(cumsum_row, np.random.uniform())
return path
这里我们定义了用于马尔可夫链的 SPRT 运行函数
@njit
def markov_sprt_single_run(P_0, P_1, π_0, π_1,
logA, logB, true_P, true_π, seed):
"""运行单次马尔可夫链 SPRT。"""
max_n = 10000
path = simulate_markov_chain(true_P, true_π, max_n, seed)
log_L = np.log(π_1[path[0]] / π_0[path[0]])
if log_L >= logA: return 1, False
if log_L <= logB: return 1, True
for t in range(1, max_n):
prev_state, curr_state = path[t-1], path[t]
p_1, p_0 = P_1[prev_state, curr_state], P_0[prev_state, curr_state]
if p_0 > 0:
log_L += np.log(p_1 / p_0)
elif p_1 > 0:
log_L = np.inf
if log_L >= logA: return t+1, False
if log_L <= logB: return t+1, True
return max_n, log_L < 0
def run_markov_sprt(params):
"""运行马尔可夫链 SPRT。"""
π_0 = compute_stationary_distribution(params.P_0)
π_1 = compute_stationary_distribution(params.P_1)
A, B, logA, logB = compute_wald_thresholds(params.α, params.β)
stopping_times = np.zeros(params.N, dtype=np.int64)
decisions_h0 = np.zeros(params.N, dtype=bool)
truth_h0 = np.zeros(params.N, dtype=bool)
for i in range(params.N):
true_P, true_π = (params.P_0, π_0) if i % 2 == 0 else (params.P_1, π_1)
truth_h0[i] = i % 2 == 0
n, accept_h0 = markov_sprt_single_run(
params.P_0, params.P_1, π_0, π_1, logA, logB,
true_P, true_π, params.seed + i)
stopping_times[i] = n
decisions_h0[i] = accept_h0
type_I = np.sum(truth_h0 & ~decisions_h0) / np.sum(truth_h0)
type_II = np.sum(~truth_h0 & decisions_h0) / np.sum(~truth_h0)
return {
'stopping_times': stopping_times, 'decisions_h0': decisions_h0,
'truth_h0': truth_h0, 'type_I': type_I, 'type_II': type_II
}
现在我们可以运行马尔可夫链的SPRT并可视化结果
# 运行马尔可夫链SPRT
P_0 = np.array([[0.7, 0.2, 0.1],
[0.3, 0.5, 0.2],
[0.1, 0.3, 0.6]])
P_1 = np.array([[0.5, 0.3, 0.2],
[0.2, 0.6, 0.2],
[0.2, 0.2, 0.6]])
params_markov = MarkovSPRTParams(α=0.05, β=0.10,
P_0=P_0, P_1=P_1, N=1000, seed=42)
results_markov = run_markov_sprt(params_markov)
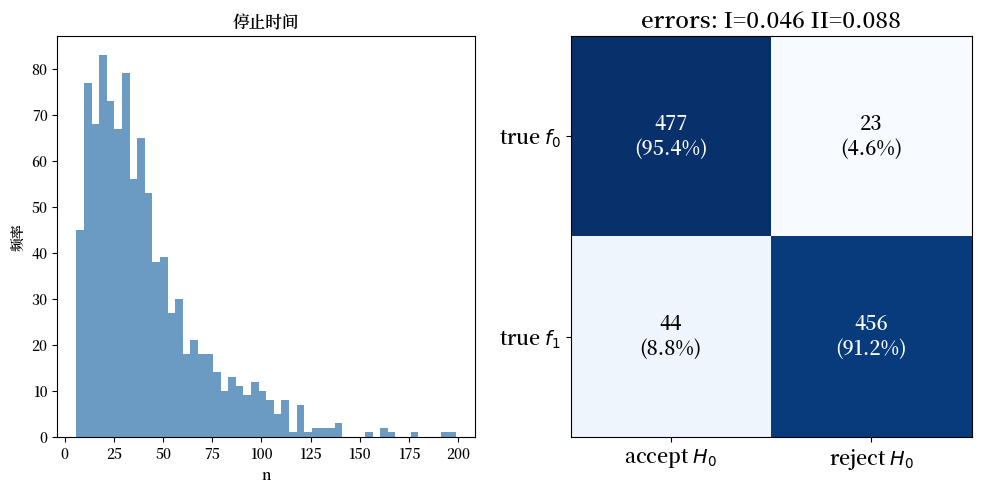
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
ax1.hist(results_markov['stopping_times'],
bins=50, color="steelblue", alpha=0.8)
ax1.set_title("停止时间")
ax1.set_xlabel("n")
ax1.set_ylabel("频率")
plot_confusion_matrix(results_markov, ax2)
plt.tight_layout()
plt.show()
练习 26.2
在本练习中,将Wald的序贯检验应用于区分具有不同动态和噪声结构的两个VAR(1)模型。
关于VAR模型的似然比过程的回顾,请参见VAR模型的似然过程。
给定每个假设下的VAR模型:
\(H_0\): \(x_{t+1} = A^{(0)} x_t + C^{(0)} w_{t+1}\)
\(H_1\): \(x_{t+1} = A^{(1)} x_t + C^{(1)} w_{t+1}\)
其中 \(w_t \sim \mathcal{N}(0, I)\) 且:
任务:
使用VAR讲座中的函数实现VAR似然比
实现Wald的序贯检验,其中 \(\alpha = 0.05\) 且 \(\beta = 0.10\)
分析在两个假设下以及模型错误设定情况下的表现
在停止时间和准确性方面与马尔可夫链情况进行比较
解答 练习 26.2
以下是该练习的一个解决方案。
首先我们定义VAR模型和模拟器的参数
VARSPRTParams = namedtuple('VARSPRTParams',
['α', 'β', 'A_0', 'C_0', 'A_1', 'C_1', 'N', 'seed'])
def create_var_model(A, C):
"""创建VAR模型。"""
μ_0 = np.zeros(A.shape[0])
CC = C @ C.T
Σ_0 = sp.linalg.solve_discrete_lyapunov(A, CC)
CC_inv = np.linalg.inv(CC + 1e-10 * np.eye(CC.shape[0]))
Σ_0_inv = np.linalg.inv(Σ_0 + 1e-10 * np.eye(Σ_0.shape[0]))
return {
'A': A, 'C': C, 'μ_0': μ_0, 'Σ_0': Σ_0,
'CC_inv': CC_inv, 'Σ_0_inv': Σ_0_inv,
'log_det_CC': np.log(
np.linalg.det(CC + 1e-10 * np.eye(CC.shape[0]))),
'log_det_Σ_0': np.log(
np.linalg.det(Σ_0 + 1e-10 * np.eye(Σ_0.shape[0])))
}
现在我们为VAR模型定义似然比和SPRT函数,类似于马尔可夫链的情况
def var_log_likelihood(x_curr, x_prev, model, initial=False):
"""计算VAR对数似然。"""
n = len(x_curr)
if initial:
diff = x_curr - model['μ_0']
return -0.5 * (n * np.log(2 * np.pi) + model['log_det_Σ_0'] +
diff @ model['Σ_0_inv'] @ diff)
else:
diff = x_curr - model['A'] @ x_prev
return -0.5 * (n * np.log(2 * np.pi) + model['log_det_CC'] +
diff @ model['CC_inv'] @ diff)
def var_sprt_single_run(model_0, model_1, model_true,
logA, logB, seed):
"""单次VAR SPRT运行。"""
np.random.seed(seed)
max_T = 500
# 生成VAR路径
Σ_chol = np.linalg.cholesky(model_true['Σ_0'])
x = model_true['μ_0'] + Σ_chol @ np.random.randn(
len(model_true['μ_0']))
# 初始似然比
log_L = (var_log_likelihood(x, None, model_1, True) -
var_log_likelihood(x, None, model_0, True))
if log_L >= logA: return 1, False
if log_L <= logB: return 1, True
# 序贯更新
for t in range(1, max_T):
x_prev = x.copy()
w = np.random.randn(model_true['C'].shape[1])
x = model_true['A'] @ x + model_true['C'] @ w
log_L += (var_log_likelihood(x, x_prev, model_1) -
var_log_likelihood(x, x_prev, model_0))
if log_L >= logA: return t+1, False
if log_L <= logB: return t+1, True
return max_T, log_L < 0
def run_var_sprt(params):
"""运行VAR SPRT。"""
model_0 = create_var_model(params.A_0, params.C_0)
model_1 = create_var_model(params.A_1, params.C_1)
A, B, logA, logB = compute_wald_thresholds(params.α, params.β)
stopping_times = np.zeros(params.N)
decisions_h0 = np.zeros(params.N, dtype=bool)
truth_h0 = np.zeros(params.N, dtype=bool)
for i in range(params.N):
model_true = model_0 if i % 2 == 0 else model_1
truth_h0[i] = i % 2 == 0
n, accept_h0 = var_sprt_single_run(model_0, model_1, model_true,
logA, logB, params.seed + i)
stopping_times[i] = n
decisions_h0[i] = accept_h0
type_I = np.sum(truth_h0 & ~decisions_h0) / np.sum(truth_h0)
type_II = np.sum(~truth_h0 & decisions_h0) / np.sum(~truth_h0)
return {'stopping_times': stopping_times,
'decisions_h0': decisions_h0,
'truth_h0': truth_h0,
'type_I': type_I, 'type_II': type_II}
让我们运行SPRT并可视化结果
# 运行 VAR SPRT
A_0 = np.array([[0.8, 0.1],
[0.2, 0.7]])
C_0 = np.array([[0.3, 0.1],
[0.1, 0.3]])
A_1 = np.array([[0.6, 0.2],
[0.3, 0.5]])
C_1 = np.array([[0.4, 0.0],
[0.0, 0.4]])
params_var = VARSPRTParams(α=0.05, β=0.10,
A_0=A_0, C_0=C_0, A_1=A_1, C_1=C_1,
N=1000, seed=42)
results_var = run_var_sprt(params_var)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
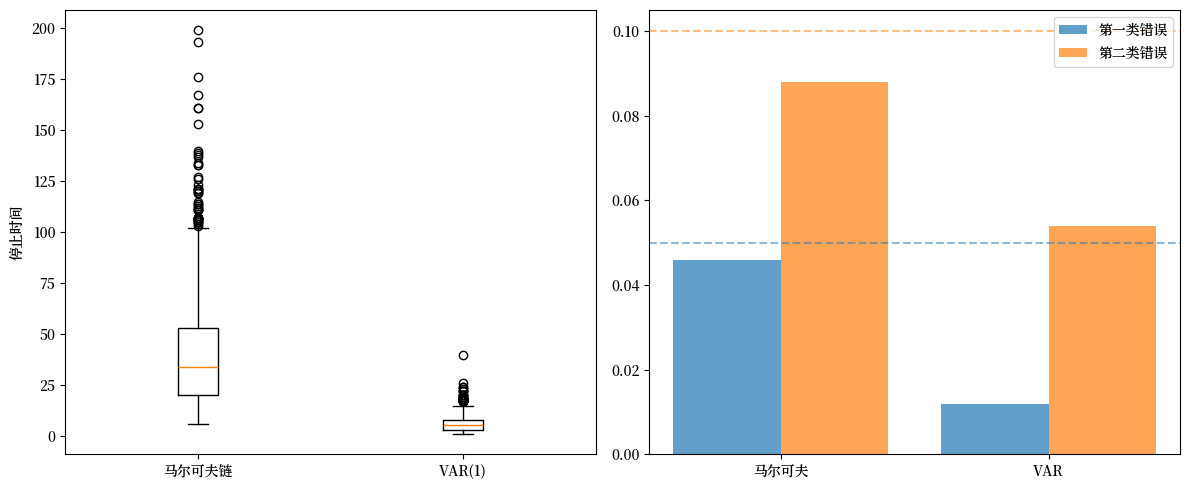
ax1.boxplot([results_markov['stopping_times'],
results_var['stopping_times']],
tick_labels=['马尔可夫链', 'VAR(1)'])
ax1.set_ylabel('停止时间')
x = np.arange(2)
ax2.bar(x - 0.2, [results_markov['type_I'], results_var['type_I']],
0.4, label='第一类错误', alpha=0.7)
ax2.bar(x + 0.2, [results_markov['type_II'], results_var['type_II']],
0.4, label='第二类错误', alpha=0.7)
ax2.axhline(y=0.05, linestyle='--', alpha=0.5, color='C0')
ax2.axhline(y=0.10, linestyle='--', alpha=0.5, color='C1')
ax2.set_xticks(x), ax2.set_xticklabels(['马尔可夫', 'VAR'])
ax2.legend()
plt.tight_layout()
plt.show()